Copyright Red Hat 1998 - 2035
This document is licensed under the "Creative Commons Attribution-ShareAlike (CC-BY-SA) 3.0" license.
This is the JGroups manual. It provides information about:
-
Installation and configuration
-
Using JGroups (the API)
-
Configuration of the JGroups protocols
The focus is on how to use JGroups, not on how JGroups is implemented.
Here are a couple of points I want to abide by throughout this book:
-
I like brevity. I will strive to describe concepts as clearly as possible (for a non-native English speaker) and will refrain from saying more than I have to to make a point.
-
I like simplicity. Keep It Simple and Stupid. This is one of the biggest goals I have both in writing this manual and in writing JGroups. It is easy to explain simple concepts in complex terms, but it is hard to explain a complex system in simple terms. I’ll try to do the latter.
So, how did it all start?
I spent 1998-1999 at the Computer Science Department at Cornell University as a post-doc, in Ken Birman’s group. Ken is credited with inventing the group communication paradigm, especially the Virtual Synchrony model. At the time they were working on their third generation group communication prototype, called Ensemble.
Ensemble followed Horus (written in C by Robbert VanRenesse), which followed ISIS (written by Ken Birman, also in C). Ensemble was written in OCaml, developed at INRIA, which is a functional language and related to ML. I never liked the OCaml language, which in my opinion has a hideous syntax. Therefore I never really made much of Ensemble, either.
However, Ensemble had a Java interface (implemented by a student in a semester project) which allowed me to program in Java and use Ensemble underneath. The Java part would require that an Ensemble process was running somewhere on the same machine, and would connect to it via a bidirectional pipe. The student had developed a simple protocol for talking to the Ensemble engine, and extended the engine as well to talk back to Java.
However, I still needed to compile and install the Ensemble runtime for each different platform, which is exactly why Java was developed in the first place: portability.
Therefore I started writing a simple framework (now JChannel), which would allow me to treat Ensemble as just another group communication transport, which could be replaced at any time by a pure Java solution. And soon I found myself working on a pure Java implementation of the group communication transport.
I figured that a pure Java implementation would have a much bigger impact than something written in Ensemble. In the end I didn’t spend much time writing scientific papers that nobody would read anyway (I guess I’m not a good scientist, at least not a theoretical one), but rather code for JGroups, which could have a much bigger impact. For me, knowing that real-life projects/products are using JGroups is much more satisfactory than having a paper accepted at a conference/journal.
That’s why, after my time was up, I left Cornell and academia altogether, and started a job in the telecom industry in Silicon Valley.
At around that time (May 2000), SourceForge had just opened its site, and I decided to use it for hosting JGroups. This was a major boost for JGroups because now other developers could work on the code. From then on, the page hits and download numbers for JGroups have steadily risen.
In the fall of 2002, Sacha Labourey contacted me, letting me know that JGroups was being used by JBoss for their clustering implementation. I joined JBoss in 2003 and have been working on JGroups and JBossCache ever since. My goal is to make JGroups the most widely used clustering software in Java …
I want to thank all contributors to JGroups, present and past, for their work. Without you, this project would never have taken off the ground.
I also want to thank Ken Birman and Robbert VanRenesse for many fruitful discussions of all aspects of group communication in particular and distributed systems in general.
I want to dedicate this manual to Jeannette, Michelle and Nicole.
Bela Ban, San Jose, Aug 2002, Kreuzlingen Switzerland 2014
1. Overview
Group communication uses the terms group and member. Members are part of a group. In the more common terminology, a member is a node and a group is a cluster. We use these terms interchangeably.
A node is a process, residing on some host. A cluster can have one or more nodes belonging to it. There can be multiple nodes on the same host, and all may or may not be part of the same cluster. Nodes can of course also run on different hosts.
JGroups is toolkit for reliable group communication. Processes can join a group, send messages to all members or single members and receive messages from members in the group. The system keeps track of the members in every group, and notifies group members when a new member joins, or an existing member leaves or crashes. A group is identified by its name. Groups do not have to be created explicitly; when a process joins a non-existing group, that group will be created automatically. Processes of a group can be located on the same host, within the same LAN, or across a WAN. A member can be part of multiple groups.
The architecture of JGroups is shown in The architecture of JGroups.
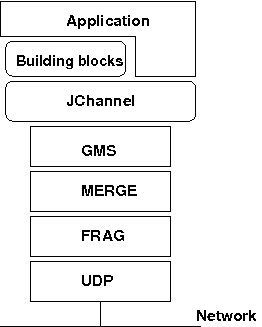
It consists of 3 parts: (1) the Channel used by application programmers to build reliable group communication applications, (2) the building blocks, which are layered on top of the channel and provide a higher abstraction level and (3) the protocol stack, which implements the properties specified for a given channel.
This document describes how to install and use JGroups, ie. the Channel API and the building blocks. The targeted audience is application programmers who want to use JGroups to build reliable distributed programs that need group communication.
A channel is connected to a protocol stack. Whenever the application sends a message, the channel passes it on to the protocol stack, which passes it to the topmost protocol. The protocol processes the message and the passes it down to the protocol below it. Thus the message is handed from protocol to protocol until the bottom (transport) protocol puts it on the network.
The same happens in the reverse direction: the transport protocol listens for messages on the network. When a message is received it will be handed up the protocol stack until it reaches the channel. The channel then invokes the receive() callback in the application to deliver the message.
When an application connects to the channel, the protocol stack will be started, and when it disconnects the stack will be stopped. When the channel is closed, the stack will be destroyed, releasing its resources.
The following three sections give an overview of channels, building blocks and the protocol stack.
1.1. Channel
To join a group and send messages, a process has to create a channel and connect to it using the group name (all channels with the same name form a group). The channel is the handle to the group. While connected, a member may send and receive messages to/from all other group members. The client leaves a group by disconnecting from the channel. A channel can be reused: clients can connect to it again after having disconnected. However, a channel allows only 1 client to be connected at a time. If multiple groups are to be joined, multiple channels can be created and connected to. A client signals that it no longer wants to use a channel by closing it. After this operation, the channel cannot be used any longer.
Each channel has a unique address. Channels always know who the other members are in the same group: a list of member addresses can be retrieved from any channel. This list is called a view. A process can select an address from this list and send a unicast message to it (also to itself), or it may send a multicast message to all members of the current view (also including itself). Whenever a process joins or leaves a group, or when a crashed process has been detected, a new view is sent to all remaining group members. When a member process is suspected of having crashed, a suspicion message is received by all non-faulty members. Thus, channels receive regular messages, and view and suspicion notifications.
The properties of a channel are typically defined in an XML file, but JGroups also allows for configuration through simple strings, URIs, DOM trees or even programmatically.
The Channel API and its related classes is described in the API section.
1.2. Building Blocks
Channels are simple and primitive. They offer the bare functionality of group communication, and have been designed after the simple model of sockets, which are widely used and well understood. The reason is that an application can make use of just this small subset of JGroups, without having to include a whole set of sophisticated classes, that it may not even need. Also, a somewhat minimalistic interface is simple to understand: a client needs to know about 5 methods to be able to create and use a channel.
Channels provide asynchronous message sending/reception, somewhat similar to UDP. A message sent is essentially put on the network and the send() method will return immediately. Conceptual requests, or responses to previous requests, are received in undefined order, and the application has to take care of matching responses with requests.
JGroups offers building blocks that provide more sophisticated APIs on top of a Channel. Building blocks either create and use channels internally, or require an existing channel to be specified when creating a building block. Applications communicate directly with the building block, rather than the channel. Building blocks are intended to save the application programmer from having to write tedious and recurring code, e.g. request-response correlation, and thus offer a higher level of abstraction to group communication.
Building blocks are described in Building Blocks.
1.3. The Protocol Stack
The protocol stack containins a number of protocol layers in a bidirectional list. All messages sent and received over the channel have to pass through all protocols. Every layer may modify, reorder, pass or drop a message, or add a header to a message. A fragmentation layer might break up a message into several smaller messages, adding a header with an id to each fragment, and re-assemble the fragments on the receiver’s side.
The composition of the protocol stack, i.e. its protocols, is determined by the creator of the channel: an XML file defines the protocols to be used (and the parameters for each protocol). The configuration is then used to create the stack.
Knowledge about the protocol stack is not necessary when only using channels in an application. However, when an application wishes to ignore the default properties for a protocol stack, and configure their own stack, then knowledge about what the individual layers are supposed to do is needed.
2. Installation and configuration
The installation refers to version 4.x of JGroups.
The JGroups JAR can be downloaded from SourceForge.
It is named jgroups-x.y.z, where x=major, y=minor and z=patch version, for example jgroups-4.0.0.Final.jar.
The JAR is all that’s needed to get started using JGroups; it contains all core, demo and (selected) test
classes, the sample XML configuration files and the schema.
Alternatively, Maven / Gradle / Ivy etc can be used:
groupId: org.jgroups
artifactId: jgroups
version: 4.0.0.Final (for example)The source code is hosted on https://github.com/belaban/jgroups[GitHub]. To build JGroups, ANT is currently used. In <<BuildingJGroups>> we'll show how to build JGroups from source.
2.1. Requirements
-
JGroups up to (and including) 3.5.0.Final requires JDK 6.
-
JGroups 3.6.x to (excluding) 4.0 requires JDK 7.
-
JGroups 4.x requires JDK 8.
-
There is no JNI code present so JGroups should run on all platforms.
-
Logging: by default, JGroups tries to use log4j2. If the classes are not found on the classpath, it resorts to log4j, and if still not found, it falls back to java.util.logging logger. See Logging for details on log configuration.
2.2. Structure of the source version
The source version consists of the following directories and files:
- src
-
the sources
- tests
-
unit and stress tests
- lib
-
JARs needed to either run the unit tests, or build the manual etc. No JARs from here are required at runtime! Note that these JARs are downloaded automatically via ivy.
- conf
-
configuration files needed by JGroups, plus default protocol stack definitions
- doc
-
documentation
2.3. Building JGroups from source
-
Download the sources from GitHub, either via git clone, or the download link into a directory
JGroups, e.g./home/bela/JGroups. -
Download ant (preferably 1.8.x or higher)
-
Change to the
JGroupsdirectory -
Run
ant -
This will compile all Java files (into the
classesdirectory). Note that if thelibdirectory doesn’t exist, ant will download ivy intoliband then use ivy to download the dependent libraries defined inivy.xml. -
To generate the JGroups JAR:
ant jar -
This will generate the following JAR files in the
distdirectory:-
jgroups-x.y.z.jar: the JGroups JAR -
jgroups-sources.jar: the source code for the core classes and demos
-
-
Now add the following directories to the classpath:
-
JGroups/classes -
JGroups/conf -
All needed JAR files in
JGroups/lib. Note that most JARs inlibare only required for running unit tests and generating test reports
-
-
To generate JavaDocs simple run:
ant javadocand the Javadoc documentation will be generated indist/javadoc
2.4. Logging
JGroups has no runtime dependencies; all that’s needed to use it is to have jgroups.jar on the classpath. For logging, this means the JVM’s logging (java.util.logging) is used.
However, JGroups can use any other logging framework. By default, log4j2 and slf4j are supported if the corresponding JARs are found on the classpath.
2.4.1. log4j2
To use log4j2, the API and CORE JARs have to be found on the
classpath. There’s an XML configuration for log4j2 in the conf dir, which can be used e.g. via
-Dlog4j.configurationFile=$JGROUPS/conf/log4j2.xml.
log4j2 is currently the preferred logging library used by JGroups, and will be used even if the log4j JAR is also present on the classpath.
2.4.2. log4j
To use log4j, the log4j JAR has to be found on the classpath. Note though that
if the log4j2 API and CORE JARs are found, then log4j2 will be used, so those JARs will have to be removed if log4j
is to be used. There’s an XML configuration for log4j in the conf dir, which can be used e.g. via
-Dlog4j.configuration=file:$JGROUPS/conf/log4j.properties.
2.4.3. JDK logging (JUL)
To force use of JDK logging, even if the log4j(2) JARs are present, -Djgroups.use.jdk_logger=true can be used.
2.4.4. Support for custom logging frameworks
JGroups allows custom loggers to be used instead of the ones supported by default. To do this, interface
CustomLogFactory has to be implemented:
public interface CustomLogFactory {
Log getLog(Class clazz);
Log getLog(String category);
}The implementation needs to return an implementation of org.jgroups.logging.Log.
To use the custom log, LogFactory.setCustomLogFactory(CustomLogFactory f) needs to be called.
2.4.5. Setting the preferred log class
It is possible to set the preferred log class via system property jgroups.log_class. To do this, the fully
qualified name of a class which provides the following functionality has to be given:
-
Implement the
Loginterface -
Provide a constructor taking a
Classtype as only argument -
Provide a constructor taking a
Stringtype as only argument
Example: -Djgroups.log_class=org.jgroups.logging.Slf4jLogImpl
2.5. Testing your setup
To see whether your system can find the JGroups classes, execute the following command:
java org.jgroups.Version
or
java -jar jgroups-x.y.z.jar
You should see the following output (more or less) if the class is found:
$ java org.jgroups.Version Version: 4.0.0.Final
2.6. Running a demo program
To test whether JGroups works okay on your machine, run the following command twice:
java org.jgroups.demos.Draw
2 whiteboard windows should appear as shown in Screenshot of 2 Draw instances.
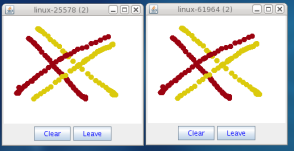
If you started them simultaneously, they could initially show a membership of 1 in their title bars. After some time, both windows should show 2. This means that the two instances found each other and formed a cluster.
When drawing in one window, the second instance should also be updated. As the default group transport uses IP multicast, make sure that - if you want start the 2 instances in different subnets - IP multicast is enabled. If this is not the case, the 2 instances won’t find each other and the example won’t work.
You can change the properties of the demo to for example use
a different transport if multicast doesn’t work (it should always
work on the same machine). Please consult the documentation to see how to do this.
State transfer (see the section in the API later) can also be tested by passing the -state flag to Draw.
2.7. Using IP Multicasting without a network connection
Sometimes there isn’t a network connection (e.g. DSL modem is down), or we want to multicast only on the local machine. For this the loopback interface (typically lo) can be configured, e.g.
route add -net 224.0.0.0 netmask 240.0.0.0 dev lo
This means that all traffic directed to the 224.0.0.0 network will be sent to the loopback interface, which means it
doesn’t need any network to be running. Note that the 224.0.0.0 network is a placeholder for all multicast addresses
in most UNIX implementations: it will catch all multicast traffic.
The above instructions may also work for Windows systems, but this hasn’t been tested. Note that not all operating systems allow multicast traffic to use the loopback interface.
Typical home networks have a gateway/firewall with 2 NICs:
the first (e.g. eth0) is connected to the outside world (Internet
Service Provider), the second (eth1) to the internal network, with
the gateway firewalling/masquerading traffic between the internal
and external networks. If no route for multicast traffic is added,
the default will be to use the fdefault gateway, which will
typically direct the multicast traffic towards the ISP. To prevent
this (e.g. ISP drops multicast traffic, or latency is too high),
we recommend to add a route for multicast traffic which goes to
the internal network (e.g. eth1).
2.8. It doesn’t work!
Make sure your machine is set up correctly for IP multicasting. There is a test program mcast which can be used to
check if IP multicasting works.
The options are:
-bind_addr-
the network interface to bind to for the receiver. If null,
mcastwill join all available interfaces -port-
the local port to use. If 0, an ephemeral port will be picked
-mcast_addr-
the multicast address to join
-mcast_port-
the port to listen on for multicasts
-ttl-
The TTL (for sending of packets)
Start multiple instances of mcast:
java org.jgroups.tests.mcast
If you want to bind to a specific network interface card (NIC), use -bind_addr 192.168.0.2, where 192.168.0.2
is the IP address of the NIC to which you want to bind. Use this parameter in both sender and receiver.
You should be able to type in the mcast window and see the output in all other instance. If not, try to use -ttl 32
in the sender. If this still fails, consult a system administrator to help you setup IP multicast correctly. If you
are the system administrator, look for another job :-)
Other means of getting help: there is a public forum on JIRA for questions. Also consider subscribing to the javagroups-users mailing list to discuss such and other problems.
2.9. Problems with IPv6
Another source of problems might be the use of IPv6, and/or misconfiguration of /etc/hosts. If you communicate between
an IPv4 and an IPv6 host, and they are not able to find each other, try the -Djava.net.preferIPv4Stack=true
property, e.g.
java -Djava.net.preferIPv4Stack=true org.jgroups.demos.Draw -props /home/bela/udp.xml
The JDK uses IPv6 by default, although is has a dual stack, that is, it also supports IPv4.
To force use of IPv6, start your JVM with -Djava.net.preferIPv6Addresses=true.
Here’s more details on the subject.
2.10. Wiki
There is a wiki which lists FAQs and their solutions at http://www.jboss.org/wiki/Wiki.jsp?page=JGroups. It is frequently updated and a useful companion to this manual.
2.11. I have discovered a bug!
If you think that you discovered a bug, submit a bug report on JIRA or send email to the jgroups-users mailing list if you’re unsure about it. Please include the following information: - [x] Version of JGroups (java org.jgroups.Version) - [x] Platform (e.g. Solaris 8) - [ ] Version of JDK (e.g. JDK 1.6.20_52) - [ ] Stack trace in case of a hang. Use kill -3 PID on UNIX systems or CTRL-BREAK on windows machines - [x] Small program that reproduces the bug (if it can be reproduced)
2.12. Supported classes
JGroups project has been around since 1998. Over this time, some of the JGroups classes have been used in experimental phases and have never been matured enough to be used in today’s production releases. However, they were not removed since some people used them in their products.
The following tables list unsupported and experimental classes. These classes are not actively maintained, and we will not work to resolve potential issues you might find. Their final fate is not yet determined; they might even be removed altogether in the next major release. Weight your risks if you decide to use them anyway.
2.12.1. Experimental classes
| Package | Class |
|---|---|
org.jgroups.blocks |
GridOutputStream |
org.jgroups.blocks |
GridInputStream |
org.jgroups.blocks |
GridFile |
org.jgroups.blocks |
PartitionedHashMap |
org.jgroups.blocks |
GridFilesystem |
org.jgroups.auth |
Krb5Token |
org.jgroups.client |
StompConnection |
org.jgroups.protocols |
DAISYCHAIN |
org.jgroups.protocols |
AsyncNoBundler |
org.jgroups.protocols |
SEQUENCER2 |
org.jgroups.protocols |
ABP |
org.jgroups.protocols |
SWIFT_PING |
org.jgroups.protocols |
AlternatingBundler |
org.jgroups.protocols |
RATE_LIMITER |
org.jgroups.protocols |
TUNNEL |
org.jgroups.protocols |
SimpleTCP |
org.jgroups.protocols |
RemoveQueueBundler |
2.12.2. Unsupported classes
| Package | Class |
|---|---|
org.jgroups.blocks |
ReplicatedTree |
org.jgroups.blocks |
PartitionedHashMap |
org.jgroups.protocols |
EXAMPLE |
org.jgroups.protocols |
DISCARD_PAYLOAD |
org.jgroups.protocols |
ABP |
3. API
This chapter explains the classes available in JGroups that will be used by applications to build reliable group communication applications. The focus is on creating and using channels.
All of the classes discussed here are in the org.jgroups package unless otherwise mentioned.
3.1. Utility classes
The org.jgroups.util.Util class contains useful common functionality which cannot be assigned to any other package.
3.1.1. objectToByteBuffer(), objectFromByteBuffer()
The first method takes an object as argument and serializes it into a byte buffer (the object has to be serializable or externalizable). The byte array is then returned. This method is often used to serialize objects into the byte buffer of a message. The second method returns a reconstructed object from a buffer. Both methods throw an exception if the object cannot be serialized or unserialized.
3.1.2. objectToStream(), objectFromStream()
The first method takes an object and writes it to an output stream. The second method takes an input stream and reads an object from it. Both methods throw an exception if the object cannot be serialized or unserialized.
3.2. Interfaces
These interfaces are used with some of the APIs presented below, therefore they are listed first.
3.2.1. MessageListener
The MessageListener interface below provides callbacks for message reception and for providing and setting the state:
public interface MessageListener {
void receive(Message msg);
void receive(MessageBatch batch);
void getState(OutputStream output) throws Exception;
void setState(InputStream input) throws Exception;
}Method receive() is called whenever a message is received and receive(MessageBatch) is called when a message
batch is received.
The getState() and setState() methods are used to fetch and set the group state (e.g. when joining).
Refer to State transfer for a discussion of state transfer.
3.2.2. MembershipListener
The MembershipListener interface is similar to the MessageListener interface above: every time a new view, a suspicion message,
or a block event is received, the corresponding method of the class implementing MembershipListener will be called.
public interface MembershipListener {
void viewAccepted(View new_view);
void suspect(Object suspected_mbr);
void block();
void unblock();
}Oftentimes the only callback that needs to be implemented will be
viewAccepted() which notifies the receiver that a new member has joined the
group or that an existing member has left or crashed. The suspect()
callback is invoked by JGroups whenever a member if suspected of having crashed, but not yet excluded
[1].
The block() method is called to notify the member that it will soon be blocked
sending messages. This is done by the FLUSH protocol, for example to ensure that nobody is sending
messages while a state transfer or view installation is in progress. When block() returns, any thread
sending messages will be blocked, until FLUSH unblocks the thread again, e.g. after the state has been
transferred successfully.
Therefore, block() can be used to send pending messages or complete some other work.
Note that block() should be brief, or else the entire FLUSH protocol is blocked.
The unblock() method is called to notify the member that the FLUSH protocol has completed and the member can resume
sending messages. If the member did not stop sending messages on block(), FLUSH simply blocked them and
will resume, so no action is required from a member. Implementation of the unblock() callback is optional.
|
|
Note that it is oftentimes simpler to extend ReceiverAdapter (see below) and implement the needed
callbacks than to implement all methods of both of these interfaces, as most callbacks are not needed.
|
3.2.3. Receiver
public interface Receiver extends MessageListener, MembershipListener;A Receiver can be used to receive messages and view changes; receive() will be invoked as soon as a
message has been received, and viewAccepted() will be called whenever a new view is installed.
3.2.4. ReceiverAdapter
This class implements Receiver with no-op implementations. When implementing a callback, we can simply extend ReceiverAdapter and overwrite receive() in order to not having to implement all callbacks of the interface.
ReceiverAdapter looks as follows:
public class ReceiverAdapter implements Receiver {
void receive(Message msg) {}
void receive(MessageBatch batch) {}
void getState(OutputStream output) throws Exception {}
void setState(InputStream input) throws Exception {}
void viewAccepted(View view) {}
void suspect(Address mbr) {}
void block() {}
void unblock() {}
}A ReceiverAdapter is the recommended way to implement callbacks.
|
|
Note that anything that could block should not be done in a callback. This includes sending of messages;
if we have FLUSH on the stack, and send a message in a viewAccepted() callback, then the following happens:
the FLUSH protocol blocks all
(multicast) messages before installing a view, then installs the view, then unblocks. However,
because installation of the view triggers the viewAccepted() callback, sending of messages inside of
viewAccepted() will block. This in turn blocks the viewAccepted() thread, so the flush will never return! If we need to send a message in a callback, the sending should be done on a separate thread, or a timer task should be submitted to the timer. |
3.2.5. ChannelListener
public interface ChannelListener {
void channelConnected(JChannel channel);
void channelDisconnected(JChannel channel);
void channelClosed(JChannel channel);
}A class implementing ChannelListener can use the JChannel.addChannelListener() method to register with a channel to obtain information about state changes in a channel. Whenever a channel is closed, disconnected or opened, the corresponding callback will be invoked.
3.3. Address
Each member of a group has an address, which uniquely identifies the member. The interface for such an
address is Address, which requires concrete implementations to provide methods such as comparison and
sorting of addresses. JGroups addresses have to implement the following interface:
public interface Address extends Streamable, Comparable<Address> {
int size();
}For marshalling purposes, size() needs to return the number of bytes an instance of an address implementation
takes up in serialized form.
|
|
Please never use implementations of Address directly; Address should always be used as an opaque identifier of a cluster node! |
Actual implementations of addresses are generated by the transport protocol (e.g. UDP or TCP).
This allows for all possible types of addresses to be used with JGroups.
Since an address uniquely identifies a channel, and therefore a group member, it can be used to send messages to that group member, e.g. in Messages (see next section).
The default implementation of Address is org.jgroups.util.UUID. It uniquely identifies
a node, and when disconnecting and reconnecting to a cluster, a node is given a new UUID on reconnection.
UUIDs are never shown directly, but are usually shown as a logical name (see Logical names). This is a name given to a node either via the user or via JGroups, and its sole purpose is to make logging output a bit more readable.
UUIDs maps to IpAddresses, which are IP addresses and ports. These are eventually used by the transport protocol to send a message.
3.3.1. IpAddressUUID
If TP.use_ip_addrs is enabled, then instead of using UUIDs, IpAddressUUIDs are used. These are IpAddresses with
some randomness added, to prevent reincarnation (restarting of a member under the same address and port, and
therefore having the same identity as the previous member).
The advantage of IpAddressUUIDs is that they always carry their physical address with them, therefore the discovery
phase needs to exchange less information and no lookup is needed to translate between UUIDs and IpAddresses.
The downside is that IpAddressUUIDs need more memory. See https://issues.jboss.org/browse/JGRP-2080 for details.
3.4. Message
Data is sent between members in the form of messages (org.jgroups.Message). A message can be sent by a member to
a single member, or to all members of the group of which the channel is an endpoint.
The structure of a message is shown in Structure of a message.
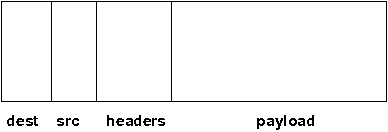
A message has 5 fields:
- Destination address
-
The address of the receiver. If
null, the message will be sent to all current group members.Message.getDest()returns the destination address of a message. - Source address
-
The address of the sender. Can be
null, and will be filled in by the transport protocol (e.g. UDP) before the message is put on the network.Message.getSrc()returns the source address, ie. the address of the sender of a message. - Flags
-
This is one byte used for flags. The currently recognized flags are
OOB,DONT_BUNDLE,NO_FC,NO_RELIABILITY,NO_TOTAL_ORDER,NO_RELAYandRSVP. ForOOB, see the discussion on the transport details. For the use of flags see the message flags. - Payload
-
The actual data (as a byte buffer). The
Messageclass contains convenience methods to set a serializable object and to retrieve it again, using serialization to convert the object to/from a byte buffer. A message also has an offset and a length, if the buffer is only a subrange of a larger buffer. - Headers
-
A list of headers that can be attached to a message. Anything that should not be in the payload can be attached to a message as a header. Methods
putHeader(),getHeader()andremoveHeader()of Message can be used to manipulate headers.
Note that headers are only used by protocol implementers; headers should not be added or removed by application code!
A message is similar to an IP packet and consists of the payload (a byte buffer) and the addresses of the sender and receiver (as Addresses). Any message put on the network can be routed to its destination (receiver address), and replies can be returned to the sender’s address.
A message usually does not need to fill in the sender’s address when sending a message; this is done automatically by the protocol stack before a message is put on the network. However, there may be cases, when the sender of a message wants to give an address different from its own, so that for example, a response should be returned to some other member.
The destination address (receiver) can be an Address, denoting the address of a member, determined e.g.
from a message received previously, or it can be null, which means that the message
will be sent to all members of the group. A typical multicast message, sending string
"Hello" to all members would look like this:
Message msg=new Message(null, "Hello");
channel.send(msg);3.5. MessageBatch
A message batch is a class used to deliver messages which includes a number of messages rather than just one. The sender and destination (= receiver) of a batch is the same for all messages of the batch. A batch can be iterated over, e.g.
MessageBatch batch;
for(Message msg: batch) {
// do something with msg
}The advantage of a message batch is that multiple messages are delivered in one go; which means potential locks are acquired only once, we have fewer threads (less work for the thread pool) and fewer context switches.
JGroups tries to bundle as many messages as possible into a batch on the sender side.
Also on the receiver side, if multiple threads added messages to a table, it tries to remove as many of them as possible and pass them up to other protocols (or the application) as a batch.
3.6. Header
A header is a custom bit of information that can be added to each message. JGroups uses headers extensively, for example to add sequence numbers to each message (NAKACK and UNICAST), so that those messages can be delivered in the order in which they were sent.
3.7. Event
Events are means by which JGroups protcols can talk to each other. Contrary to Messages, which travel over the network between group members, events only travel up and down the stack.
|
|
Headers and events are only used by protocol implementers; they are not needed by application code! |
3.8. View
A view (org.jgroups.View) is a list of the current members of a group. It consists
of a ViewId, which uniquely identifies the view (see below), and a list of members.
Views are installed in a channel automatically by the underlying protocol stack whenever a new member joins
or an existing one leaves (or crashes). All members of a group see the same sequence of views.
Note that the first member of a view is the coordinator (the one who emits new views). Thus, whenever the membership changes, every member can determine the coordinator easily and without having to contact other members, by picking the first member of a view.
The code below shows how to send a (unicast) message to the first member of a view (error checking code omitted):
View view=channel.getView();
Address first=view.getMembers().get(0);
Message msg=new Message(first, "Hello world");
channel.send(msg);Whenever an application is notified that a new view has been installed (e.g. by
Receiver.viewAccepted(), the view is already set in the channel. For example,
calling Channel.getView() in a viewAccepted()
callback would return the same view (or possibly the next one in case there has already been a new view!).
3.8.1. ViewId
The ViewId is used to uniquely number views. It consists of the address of the view creator and a
sequence number. ViewIds can be compared for equality and put in a hashmaps as they implement equals()
and hashCode().
|
|
Note that the latter 2 methods only take the ID into account. |
3.8.2. MergeView
Whenever a group splits into subgroups, e.g. due to a network partition, and later the subgroups merge
back together, a MergeView instead of a View will be received by the application. MergeView is
a subclass of View and contains as additional instance variables the list of views that were merged.
As an example if the cluster with view V1={P,Q,R,S,T} split into subgroups V2={P,Q,R} and V2={S,T}, the merged view might be V3={P,Q,R,S,T}. In this case the MergeView contains a list of two views: V2={P,Q,R}) and V2={S,T}.
|
|
Because the default merge policy adds members from subgroups into a common group and sorts the resulting list, the membership order might change on a merge event. Thus a view V1={P,Q,R,S,T}, followed by view V2={P,Q,R} and V2={S,T} might result in a merge view V3={P,T,Q,S,R}. To prevent this, the task of creating new views can be delegated to custom code (see Determining the coordinator and controlling view generation). |
|
|
Because merging needs to handle all edge cases, it is not guaranteed that subsequent MergeViews won’t have identical membership. For example, we we have view A2={A,B} in A and B3={B} in B, then a subsequent merge might install view A4={A,B} in both A and B. In A’s case, the membership between A2 and A4 doesn’t change. An application has to be able to handle duplicate subsequent merge views. Note that consecutive regular views will never have duplicate members. |
3.9. JChannel
In order to join a group and send messages, a process has to create a channel. A channel is like a socket. When a client connects to a channel, it gives the the name of the group it would like to join. Thus, a channel is (in its connected state) always associated with a particular group. The protocol stack takes care that channels with the same group name find each other: whenever a client connects to a channel given group name G, then it tries to find existing channels with the same name, and joins them, resulting in a new view being installed (which contains the new member). If no members exist, a new group will be created.
A state transition diagram for the major states a channel can assume are shown in [ChannelStatesFig].
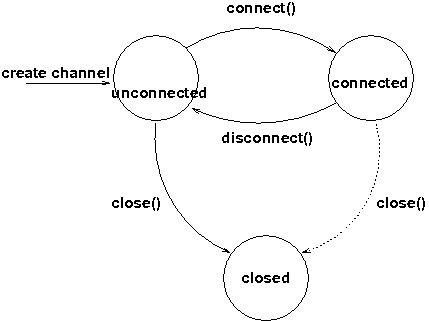
When a channel is first created, it is in the unconnected state.
An attempt to perform certain operations which are only valid in the connected state (e.g. send/receive messages) will result in an exception.
After a successful connection by a client, it moves to the connected state. Now the channel will receive messages from other members and may send messages to other members or to the group, and it will get notified when new members join or leave. Getting the local address of a channel is guaranteed to be a valid operation in this state (see below).
When the channel is disconnected, it moves back to the unconnected state. Both a connected and unconnected channel may be closed, which makes the channel unusable for further operations. Any attempt to do so will result in an exception. When a channel is closed directly from a connected state, it will first be disconnected, and then closed.
The methods available for creating and manipulating channels are discussed now.
3.9.1. Creating a channel
A channel is created using one of its public constructors (e.g. new JChannel()).
The most frequently used constructor of JChannel looks as follows:
public JChannel(String props) throws Exception;The props argument points to an XML file containing the configuration of the protocol stack to be used. This can be a String, but there are also other constructors which take for example a DOM element or a URL (see the javadoc for details).
The code sample below shows how to create a channel based on an XML configuration file:
JChannel ch=new JChannel("/home/bela/udp.xml");If the props argument is null, the default properties will be used. An exception will be thrown if the channel cannot be created. Possible causes include protocols that were specified in the property argument, but were not found, or wrong parameters to protocols.
For example, the Draw demo can be launched as follows:
java org.javagroups.demos.Draw -props file:/home/bela/udp.xml
or
java org.javagroups.demos.Draw -props http://www.jgroups.org/udp.xml
In the latter case, an application downloads its protocol stack specification from a server, which allows for central administration of application properties.
A sample XML configuration looks like this (edited from udp.xml):
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups.xsd">
<UDP
mcast_port="${jgroups.udp.mcast_port:45588}"
ip_ttl="4"
ucast_recv_buf_size="5M"
ucast_send_buf_size="5M"
mcast_recv_buf_size="5M"
mcast_send_buf_size="5M"
max_bundle_size="64K"
enable_diagnostics="true"
thread_pool.min_threads="2"
thread_pool.max_threads="8"
thread_pool.keep_alive_time="5000" />
<PING />
<MERGE3 max_interval="30000"
min_interval="10000"/>
<FD_SOCK/>
<FD_ALL/>
<VERIFY_SUSPECT timeout="1500" />
<pbcast.NAKACK2 xmit_interval="500"
xmit_table_num_rows="100"
xmit_table_msgs_per_row="2000"
xmit_table_max_compaction_time="30000"
max_msg_batch_size="500"
use_mcast_xmit="false"
discard_delivered_msgs="true"/>
<UNICAST3 xmit_interval="500"
xmit_table_num_rows="100"
xmit_table_msgs_per_row="2000"
xmit_table_max_compaction_time="60000"
conn_expiry_timeout="0"
max_msg_batch_size="500"/>
<pbcast.STABLE desired_avg_gossip="50000"
max_bytes="4M"/>
<pbcast.GMS print_local_addr="true" join_timeout="2000"/>
<UFC max_credits="2M"
min_threshold="0.4"/>
<MFC max_credits="2M"
min_threshold="0.4"/>
<FRAG2 frag_size="60K" />
</config>A stack is wrapped by <config> and </config> elements and lists all protocols from bottom
(UDP) to top (FRAG2). Each element defines one protocol.
Each protocol is implemented as a Java class. When a protocol stack is created based on the above XML configuration, the first element ("UDP") becomes the bottom-most layer, the second one will be placed on the first, etc: the stack is created from the bottom to the top.
Each element has to be the name of a Java class that resides in the org.jgroups.protocols package.
Note that only the base name has to be given, not the fully specified class name
(UDP instead of org.jgroups.protocols.UDP).
If the protocol class is not found, JGroups assumes that the name given is a fully qualified classname
and will therefore try to instantiate that class. If this does not work an exception is thrown.
This allows for protocol classes to reside in different packages altogether, e.g. a valid protocol name
could be com.sun.eng.protocols.reliable.UCAST.
Each layer may have zero or more arguments, which are specified as a list of name/value pairs in
parentheses directly after the protocol name. In the example above, UDP is configured with some options,
one of them being the IP multicast port (mcast_port) which is set to 45588, or to the value of
the system property jgroups.udp.mcast_port, if set.
|
|
Note that all members in a group have to have the same protocol stack. |
Programmatic creation
Usually, channels are created by passing the name of an XML configuration file to the JChannel() constructor. On top of this declarative configuration, JGroups provides an API to create a channel programmatically.
The way to do this is to first create a JChannel, then an instance of
ProtocolStack, then add all desired protocols to the stack and finally calling init() on the stack
to set it up. The rest, e.g. calling JChannel.connect() is the same as with the declarative
creation.
An example of how to programmatically create a channel is shown below (copied from ProgrammaticChat):
public class ProgrammaticChat {
public static void main(String[] args) throws Exception {
Protocol[] prot_stack={
new UDP().setValue("bind_addr", InetAddress.getByName("127.0.0.1")),  new PING(),
new MERGE3(),
new FD_SOCK(),
new FD_ALL(),
new VERIFY_SUSPECT(),
new BARRIER(),
new NAKACK2(),
new UNICAST3(),
new STABLE(),
new GMS(),
new UFC(),
new MFC(),
new FRAG2()};
JChannel ch=new JChannel(prot_stack).name(args[0]);
new PING(),
new MERGE3(),
new FD_SOCK(),
new FD_ALL(),
new VERIFY_SUSPECT(),
new BARRIER(),
new NAKACK2(),
new UNICAST3(),
new STABLE(),
new GMS(),
new UFC(),
new MFC(),
new FRAG2()};
JChannel ch=new JChannel(prot_stack).name(args[0]); 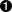 ch.setReceiver(new ReceiverAdapter() {
public void viewAccepted(View new_view) {
System.out.println("view: " + new_view);
}
public void receive(Message msg) {
System.out.println("<< " + msg.getObject() + " [" + msg.getSrc() + "]");
}
});
ch.connect("ChatCluster");
for(;;) {
String line=Util.readStringFromStdin(": ");
ch.send(null, line);
}
}
}
ch.setReceiver(new ReceiverAdapter() {
public void viewAccepted(View new_view) {
System.out.println("view: " + new_view);
}
public void receive(Message msg) {
System.out.println("<< " + msg.getObject() + " [" + msg.getSrc() + "]");
}
});
ch.connect("ChatCluster");
for(;;) {
String line=Util.readStringFromStdin(": ");
ch.send(null, line);
}
}
}First, the JChannel is created (1) with an array of protocols. The protocols have some fields already set, e.g.
bind_addr in UDP (2).
The protocols are arranged bottom-first; e.g. UDP as transport is first, then PING and so on, until FRAG2, which
is the top protocol. Every protocol can be configured via setters, but there is also a generic
setValue(String attr_name, Object value), which can be used to configure protocols as well, as shown in the example.
3.9.2. Giving the channel a logical name
A channel can be given a logical name which is then used instead of the channel’s address in toString().
A logical name might show the function of a channel, e.g. "HostA-HTTP-Cluster", which is more legible
than a UUID 3c7e52ea-4087-1859-e0a9-77a0d2f69f29.
For example, when we have 3 channels, using logical names we might see a view {A,B,C}, which is nicer
than
{56f3f99e-2fc0-8282-9eb0-866f542ae437,ee0be4af-0b45-8ed6-3f6e-92548bfa5cde,
9241a071-10ce-a931-f675-ff2e3240e1ad}!
If no logical name is set, JGroups generates one, using the hostname and a random number, e.g.
linux-3442. If this is not desired and the UUIDs should be shown, use system property
-Djgroups.print_uuids=true.
The logical name can be set using:
public void setName(String logical_name);This must be done before connecting a channel. Note that the logical name stays with a channel until the channel is destroyed, whereas a UUID is created on each connection.
When JGroups starts, it prints the logical name and the associated physical address(es):
------------------------------------------------------------------- GMS: address=mac-53465, cluster=DrawGroupDemo, physical address=192.168.1.3:49932 -------------------------------------------------------------------
The logical name is mac-53465 and the physical address is 192.168.1.3:49932. The UUID is not shown here.
3.9.3. Generating custom addresses
Since 2.12 address generation is pluggable. This means that an application can determine what kind of
addresses it uses. The default address type is UUID, and since some protocols use UUID, it is
recommended to provide custom classes as subclasses of UUID.
This can be used to for example pass additional data around with an address, for example information about the location of the node to which the address is assigned. Note that methods equals(), hashCode() and compare() of the UUID super class should not be changed.
To use custom addresses, an implementation of org.jgroups.stack.AddressGenerator
has to be written.
For any class CustomAddress, it will need to get registered with the ClassConfigurator in order to marshal it correctly:
class CustomAddress extends UUID {
static {
ClassConfigurator.add((short)8900, CustomAddress.class);
}
}|
|
Note that the ID should be chosen such that it doesn’t collide with any IDs defined in
jg-magic-map.xml.
|
Set the address generator in JChannel.setAddressGenerator(AddressGenerator). This has to
be done before the channel is connected.
An example of a subclass is org.jgroups.util.PayloadUUID, and there are two more shipped with JGroups.
3.9.4. Joining a cluster
When a client wants to join a cluster, it connects to a channel giving the name of the cluster to be joined:
public void connect(String cluster) throws Exception;The cluster name is the name of the cluster to be joined. All channels that call connect() with
the same name form a cluster. Messages sent on any channel in the cluster will be received by all
members (including the one who sent it).
|
|
Local delivery can be turned off using setDiscardOwnMessages(true).
|
The connect() method returns as soon as the cluster has been joined successfully. If the channel is in
the closed state (see channel states), an exception will be thrown. If there are
no other members, i.e. no other member has connected to a cluster with this name, then a new cluster is
created and the member joins it as first member. The first member of a cluster becomes its coordinator.
A coordinator is in charge of installing new views whenever the membership changes
3.9.5. Joining a cluster and getting the state in one operation
Clients can also join a cluster and fetch cluster state in one operation.
The best way to conceptualize the connect and fetch state connect method is to think of it as an
invocation of the regular connect() and getState() methods executed in succession. However, there are
several advantages of using the connect and fetch state connect method over the regular connect. First
of all, the underlying message exchange is heavily optimized, especially if the flush protocol is used.
But more importantly, from a client’s perspective, the connect() and fetch state operations become
one atomic operation.
public void connect(String cluster, Address target, long timeout) throws Exception;Just as in a regular connect(), the cluster name represents a cluster to be joined. The target parameter indicates a cluster member to fetch the state from. A null target indicates that the state should be fetched from the cluster coordinator. If the state should be fetched from a particular member other than the coordinator, clients can simply provide the address of that member. The timeout paremeter bounds the entire join and fetch operation. An exception will be thrown if the timeout is exceeded.
3.9.6. Getting the local address and the cluster name
Method getAddress() returns the address of the channel. The address may or may
not be available when a channel is in the unconnected state.
public Address getAddress();Method getClusterName() returns the name of the cluster which the member joined.
public String getClusterName();Again, the result is undefined if the channel is in the disconnected or closed state.
3.9.7. Getting the current view
The following method can be used to get the current view of a channel:
public View getView();This method returns the current view of the channel. It is updated every time a new view is
installed (viewAccepted() callback).
Calling this method on an unconnected or closed channel is implementation defined. A channel may return null, or it may return the last view it knew of.
3.9.8. Sending messages
Once the channel is connected, messages can be sent using one of the send() methods:
public void send(Message msg) throws Exception;
public void send(Address dst, Object obj) throws Exception;
public void send(Address dst, byte[] buf, int off, int len) throws Exception;The first send() method has only one argument, which is the message to be sent.
The message’s destination should either be the address of the receiver (unicast) or null (multicast).
When the destination is null, the message will be sent to all members of the cluster (including itself).
The remainaing send() methods are helper methods; they take either a byte[]
buffer or an object, create a Message and call send(Message).
If the channel is not connected, or was closed, an exception will be thrown upon attempting to send a message.
Here’s an example of sending a message to all members of a cluster:
Map data; // any serializable data
channel.send(null, data);The null value as destination address means that the message will be sent to all members in the cluster.
The payload is a hashmap, which will be serialized into the message’s buffer and unserialized at the
receiver. Alternatively, any other means of generating a byte buffer and setting the message’s buffer
to it (e.g. using Message.setBuffer()) also works.
Here’s an example of sending a unicast message to the first member (coordinator) of a group:
Address receiver=channel.getView().getMembers().get(0);
channel.send(receiver, "hello world");The sample code determines the coordinator (first member of the view) and sends it a "hello world" message.
A note about buffer reuse
The following code is wrong:
protected void sendFile() throws Exception {
FileInputStream in=new FileInputStream(filename);
byte[] buf=new byte[8096];
for(;;) {
int bytes=in.read(buf);
if(bytes == -1)
break;
channel.send(new Message(null, buf, 0, bytes));
}
}-
Buffer
bufis reused and can get overwritten with new data while JGroups-
queues the message in a bundler and sends multiple messages as a message batch
-
possibly retransmits the message if not received by the receiver(s); retransmitting the changed buffer
-
-
Correct: move
bufinto the for loop
Discarding one’s own messages
Sometimes, it is desirable not to have to deal with one’s own messages, ie. messages sent by oneself.
To do this, JChannel.setDiscardOwnMessages(boolean flag) can be set to
true (false by default). This means that every cluster node will receive a message sent
by P, but P itself won’t.
Synchronous messages
While JGroups guarantees that a message will eventually be delivered at all non-faulty members, sometimes this might take a while. For example, if we have a retransmission protocol based on negative acknowledgments, and the last message sent is lost, then the receiver(s) will have to wait until the stability protocol notices that the message has been lost, before it can be retransmitted.
This can be changed by setting the Message.RSVP flag in a message: when this flag is encountered,
the message send blocks until all members have acknowledged reception of the message (of course
excluding members which crashed or left meanwhile).
This also serves as another purpose: if we send an RSVP-tagged message, then - when the send() returns - we’re guaranteed that all messages sent before will have been delivered at all members as well. So, for example, if P sends message 1-10, and marks 10 as RSVP, then, upon JChannel.send() returning, P will know that all members received messages 1-10 from P.
Note that since RSVP’ing a message is costly, and might block the sender for a while, it should be used sparingly. For example, when completing a unit of work (ie. member P sending N messages), and P needs to know that all messages were received by everyone, then RSVP could be used.
To use RSVP, two things have to be done:
First, the RSVP protocol has to be in the config, somewhere above the reliable transmission
protocols such as NAKACK2 or UNICAST3, e.g.:
<config>
<UDP/>
<PING />
<FD_ALL/>
<pbcast.NAKACK2 use_mcast_xmit="true"
discard_delivered_msgs="true"/>
<UNICAST3 timeout="300,600,1200"/>
<RSVP />
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="4M"/>
<pbcast.GMS print_local_addr="true" join_timeout="3000"/>
...
</config>Secondly, the message we want to get ack’ed must be marked as RSVP:
Message msg=new Message(null, "hello world").setFlag(Message.RSVP);
ch.send(msg);Here, we send a message to all cluster members (dest == null). (Note that RSVP also works for sending
a message to a unicast destination). Method send() will return as soon as it has received acks from
all current members. If there are 4 members A, B, C and D, and A has received acks from itself, B
and C, but D’s ack is missing and D crashes before the timeout kicks in, then this will
nevertheless make send() return, as if D had actually sent an ack.
If the timeout property is greater than 0, and we don’t receive all acks within
timeout milliseconds, a TimeoutException will be thrown (if RSVP.throw_exception_on_timeout is true).
The application can choose to catch this (runtime) exception and do something with it, e.g. retry.
The configuration of RSVP is described here: RSVP.
|
|
RSVP was added in version 3.1. |
Non blocking RSVP
Sometimes a sender wants a given message to be resent until it has been received, or a timeout occurs, but doesn’t want
to block. As an example, RpcDispatcher.callRemoteMethodsWithFuture() needs to return immediately, even if the results
aren’t available yet. If the call options contain flag RSVP, then the future would only be returned once all
responses have been received. This is clearly undesirable behavior.
To solve this, flag RSVP_NB (non-blocking) can be used. This has the same behavior as RSVP, but the caller is not
blocked by the RSVP protocol. When a timeout occurs, a warning message will be logged, but since the caller doesn’t
block, the call won’t throw an exception.
3.9.9. Receiving messages
Methods receive(Message) and receive(MessageBatch) in ReceiverAdapter (or Receiver) can be overridden to
receive messages.
public void receive(Message msg);
public void receive(MessageBatch batch);A Receiver can be registered with a channel using JChannel.setReceiver(). All received messages, view
changes and state transfer requests will invoke callbacks on the registered Receiver:
JChannel ch=new JChannel();
ch.setReceiver(new ReceiverAdapter() {
public void receive(Message msg) {
System.out.println("received message " + msg);
}
public void viewAccepted(View view) {
System.out.println("received view " + new_view);
}
});
ch.connect("MyCluster");|
|
The semantics of receive(Message msg) changed slightly in 4.0: as the buffer of msg might get reused by
the transport (to reduce the memory allocation rate), the receive() method must consume the buffer
(e.g. de-serialize it into an application object), or make a copy.
As soon as receive() returns, the message’s buffer might get overwritten with new data.
|
To receive message batches (see MessageBatch), method receive(MessageBatch) has to be implemented, e.g.:
public void receive(MessageBatch batch) {
for(Message msg: batch) {
// do something with the message
}
}Implementing the receive(MessageBatch) callback is not strictly necessary, as the default implementation will call
receive(Message) for each message of a batch, but it may be more efficient if the application can process batches
of messages in one go.
3.9.10. Receiving view changes
As shown above, the viewAccepted() callback of ReceiverAdapter can be used
to get callbacks whenever a cluster membership change occurs. The receiver needs to be set via
JChannel.setReceiver(Receiver).
As discussed in ReceiverAdapter, code in callbacks must avoid anything that takes a lot of time, or blocks; JGroups invokes this callback as part of the view installation, and if this user code blocks, the view installation would block, too.
3.9.11. Getting the group’s state
A newly joined member may want to retrieve the state of the cluster before starting work. This is done
with getState():
public void getState(Address target, long timeout) throws Exception;This method returns the state of one member (usually of the oldest member, the coordinator). The target parameter can usually be null, to ask the current coordinator for the state. If a timeout (ms) elapses before the state is fetched, an exception will be thrown. A timeout of 0 waits until the entire state has been transferred.
|
|
The reason for not directly returning the state as a result of getState() is that the state has to be returned in the correct position relative to other messages. Returning it directly would violate the FIFO properties of a channel, and state transfer would not be correct! |
To participate in state transfer, both state provider and state requester have to implement the following callbacks from ReceiverAdapter (Receiver):
public void getState(OutputStream output) throws Exception;
public void setState(InputStream input) throws Exception;Method getState() is invoked on the state provider (usually the coordinator). It
needs to write its state to the output stream given. Note that output doesn’t need to be closed when
done (or when an exception is thrown); this is done by JGroups.
The setState() method is invoked on the state requester; this is the member
which called JChannel.getState(). It needs to read its state from the input stream and set its
internal state to it. Note that input doesn’t need to be closed when
done (or when an exception is thrown); this is done by JGroups.
In a cluster consisting of A, B and C, with D joining the cluster and calling Channel.getState(), the
following sequence of callbacks happens:
-
D calls
JChannel.getState(). The state will be retrieved from the oldest member, A -
A’s
getState()callback is called. A writes its state to the output stream passed as a parameter togetState(). -
D’s
setState()callback is called with an input stream as argument. D reads the state from the input stream and sets its internal state to it, overriding any previous data. -
D:
JChannel.getState()returns. Note that this will only happen after the state has been transferred successfully, or a timeout elapsed, or either the state provider or requester throws an exception. Such an exception will be re-thrown bygetState(). This could happen for instance if the state provider’sgetState()callback tries to stream a non-serializable class to the output stream.
The following code fragment shows how a group member participates in state transfers:
public void getState(OutputStream output) throws Exception {
synchronized(state) {
Util.objectToStream(state, new DataOutputStream(output));
}
}
public void setState(InputStream input) throws Exception {
List<String> list;
list=(List<String>)Util.objectFromStream(new DataInputStream(input));
synchronized(state) {
state.clear();
state.addAll(list);
}
System.out.println(list.size() + " messages in chat history):");
for(String str: list)
System.out.println(str);
}This code is the Chat example from the JGroups tutorial and the state here is a list of strings.
The getState() implementation synchronized on the state (so no incoming messages can modify it during
the state transfer), and uses the JGroups utility method objectToStream().
The setState() implementation also uses the Util.objectFromStream() utility method to read the state from
the input stream and assign it to its internal list.
State transfer protocols
In order to use state transfer, a state transfer protocol has to be included in the configuration.
This can either be STATE_TRANSFER, STATE, or STATE_SOCK. More details on the protocols can
be found in the protocols list section.
This is the original state transfer protocol, which used to transfer byte[] buffers. It still does
that, but is internally converted to call the getState() and setState() callbacks which use
input and output streams.
Note that, because byte[] buffers are converted into input and output streams, this protocol
should not be used for transfer of large states.
For details see pbcast.STATE_TRANSFER.
This is the STREAMING_STATE_TRANSFER protocol, renamed in 3.0. It sends the entire state
across from the provider to the requester in (configurable) chunks, so that memory consumption
is minimal.
For details see pbcast.STATE.
Same as STREAMING_STATE_TRANSFER, but a TCP connection between provider and requester is
used to transfer the state.
For details see STATE_SOCK.
3.9.12. Disconnecting from a channel
Disconnecting from a channel is done using the following method:
public void disconnect();It will have no effect if the channel is already in the disconnected or closed state. If connected, it will leave the cluster. This is done (transparently for a channel user) by sending a leave request to the current coordinator. The latter will subsequently remove the leaving node from the view and install a new view in all remaining members.
After a successful disconnect, the channel will be in the unconnected state, and may subsequently be reconnected.
3.9.13. Closing a channel
To destroy a channel instance (destroy the associated protocol stack, and release all resources),
method close() is used:
public void close();Closing a connected channel disconnects the channel first.
The close() method moves the channel to the closed state, in which no further operations are allowed (most throw an exception when invoked on a closed channel). In this state, a channel instance is not considered used any longer by an application and — when the reference to the instance is reset — the channel essentially only lingers around until it is garbage collected by the Java runtime system.
4. Building Blocks
Building blocks are layered on top of channels, and can be used instead of channels whenever a higher-level interface is required.
Whereas channels are simple socket-like constructs, building blocks may offer a far more sophisticated
interface. In some cases, building blocks offer access to the underlying channel, so that — if the building
block at hand does not offer a certain functionality — the channel can be accessed directly. Building blocks
are located in the org.jgroups.blocks package.
4.1. MessageDispatcher
A channels is a simple class asynchronously send and receive messages. However, a significant number of communication patterns in group communication require synchronous communication. For example, a sender would like to send a message to the group and wait for all responses. Or another application would like to send a message to the group and wait only until the majority of the receivers have sent a response, or until a timeout occurred.
MessageDispatcher provides blocking (and non-blocking) request sending and response correlation. It offers synchronous (as well as asynchronous) message sending with request-response correlation, e.g. matching one or multiple responses with the original request.
An example of using this class would be to send a request message to all cluster members, and block until all responses have been received, or until a timeout has elapsed.
Contrary to RpcDispatcher, MessageDispatcher deals with sending message requests and correlating message responses, while RpcDispatcher deals with invoking method calls and correlating responses. RpcDispatcher extends MessageDispatcher, and offers an even higher level of abstraction over MessageDispatcher.
RpcDispatcher is essentially a way to invoke remote procedure calls (RCs) across a cluster.
Both MessageDispatcher and RpcDispatcher sit on top of a channel; therefore an instance of
MessageDispatcher is created with a channel as argument. It can now be
used in both client and server role: a client sends requests and receives responses and
a server receives requests and sends responses. MessageDispatcher allows for an
application to be both at the same time. To be able to serve requests in the server role, the
RequestHandler.handle() method has to be implemented:
Object handle(Message msg) throws Exception;The handle() method is called whenever a request is received. It must return a value
(must be serializable, but can be null) or throw an exception. The returned value will be sent to the sender,
and exceptions are also propagated to the sender.
Before looking at the methods of MessageDispatcher, let’s take a look at RequestOptions first.
4.1.1. RequestOptions
Every message sending in MessageDispatcher or request invocation in RpcDispatcher is governed by an instance of RequestOptions. This is a class which can be passed to a call to define the various options related to the call, e.g. a timeout, whether the call should block or not, the flags (see Tagging messages with flags) etc.
The various options are:
-
Response mode: this determines whether the call is blocking and - if yes - how long it should block. The modes are:
GET_ALL-
Block until responses from all members (minus the suspected ones) have been received.
GET_NONE-
Wait for none. This makes the call non-blocking
GET_FIRST-
Block until the first response (from anyone) has been received
-
Timeout: number of milliseconds we’re willing to block. If the call hasn’t terminated after the timeout elapsed, a TimeoutException will be thrown. A timeout of 0 means to wait forever. The timeout is ignored if the call is non-blocking (mode=
GET_NONE) -
Anycasting: if set to true, this means we’ll use unicasts to individual members rather than sending multicasts. For example, if we have have TCP as transport, and the cluster is {A,B,C,D,E}, and we send a message through MessageDispatcher where dests={C,D}, and we do not want to send the request to everyone, then we’d set anycasting=true. This will send the request to C and D only, as unicasts, which is better if we use a transport such as TCP which cannot use IP multicasting (sending 1 packet to reach all members).
-
Response filter: A RspFilter allows for filtering of responses and user-defined termination of a call. For example, if we expect responses from 10 members, but can return after having received 3 non-null responses, a RspFilter could be used. See Response filters for a discussion on response filters.
-
Flags: the various flags to be passed to the message, see the section on message flags for details.
-
Exclusion list: here we can pass a list of members (addresses) that should be excluded. For example, if the view is A,B,C,D,E, and we set the exclusion list to A,C then the caller will wait for responses from everyone except A and C. Also, every recipient that’s in the exclusion list will discard the message.
An example of how to use RequestOptions is:
RpcDispatcher disp;
RequestOptions opts=new RequestOptions(Request.GET_ALL)
.setFlags(Message.NO_FC, Message.OOB);
Object val=disp.callRemoteMethod(target, method_call, opts);The methods to send requests are:
public <T> RspList<T>
castMessage(Collection<Address> dests, byte[] data, int offset, int length,
RequestOptions opts) throws Exception;
public <T> CompletableFuture<RspList<T>>
castMessageWithFuture(Collection<Address> dests, Buffer data,
RequestOptions opts) throws Exception;
public <T> T sendMessage(Address dest, byte[] data, int offset, int length,
RequestOptions opts) throws Exception;
public <T> CompletableFuture<T>
sendMessageWithFuture(Address dest, byte[] data, int offset, int length,
RequestOptions opts) throws Exception;castMessage() sends a message to all members defined in dests. If dests is null, the message is sent to all
members of the current cluster.
If a message is sent synchronously (defined by options.mode), then options.timeout
defines the maximum amount of time (in milliseconds) to wait for the responses.
castMessage() returns a RspList, which contains a map of addresses and Rsps;
there’s one Rsp per member listed in dests.
A Rsp instance contains the response value (or null), an exception if the target handle() method threw
an exception, whether the target member was suspected, or not, and so on. See the example below for
more details.
castMessageWithFuture() returns immediately, with a CompletableFuture. The future
can be used to fetch the response list (now or later), and it also allows for installation of a callback
which will be invoked when the future is done.
See Asynchronous calls with futures for details on how to use CompletableFutures.
Note that Buffer is a simple wrapper around a byte[] array, an offset and a length.
sendMessage() allows an application programmer to send a unicast message to a
single cluster member and receive the response. The destination of the message has to be non-null (valid
address of a member). The mode argument is ignored (it is by default set to
ResponseMode.GET_FIRST) unless it is set to GET_NONE in which case
the request becomes asynchronous, ie. we will not wait for the response.
sendMessageWithFuture() returns immediately with a future, which can be used to fetch the result.
One advantage of using this building block is that failed members are removed from the set of expected responses. For example, when sending a message to 10 members and waiting for all responses, and 2 members crash before being able to send a response, the call will return with 8 valid responses and 2 marked as failed. The return value of castMessage() is a RspList which contains all responses (not all methods shown):
public class RspList<T> implements Map<Address,Rsp> {
public boolean isReceived(Address sender);
public int numSuspectedMembers();
public List<T> getResults();
public List<Address> getSuspectedMembers();
public boolean isSuspected(Address sender);
public Object get(Address sender);
public int size();
}isReceived() checks whether a response from sender
has already been received. Note that this is only true as long as no response has yet been received, and the
member has not been marked as failed. numSuspectedMembers() returns the number of
members that failed (e.g. crashed) during the wait for responses. getResults()
returns a list of return values. get() returns the return value for a specific member.
4.1.2. Requests and target destinations
When a non-null list of addresses is passed (as the destination list) to MessageDispatcher.castMessage() or
RpcDispatcher.callRemoteMethods(), then this does not mean that only the members
included in the list will receive the message, but rather it means that we’ll only wait for responses from
those members, if the call is blocking.
If we want to restrict the reception of a message to the destination members, there are a few ways to do this:
-
If we only have a few destinations to send the message to, use several unicasts.
-
Use anycasting. E.g. if we have a membership of
{A,B,C,D,E,F}, but only want A and C to receive the message, then set the destination list to A and C and enable anycasting in the RequestOptions passed to the call (see above). This means that the transport will send 2 unicasts. -
Use exclusion lists. If we have a membership of
{A,B,C,D,E,F}, and want to send a message to almost all members, but exclude D and E, then we can define an exclusion list: this is done by settting the destination list tonull(= send to all members), or to{A,B,C,D,E,F}and set the exclusion list in the RequestOptions passed to the call to D and E.
4.1.3. Example
This section shows an example of how to use a MessageDispatcher.
public class MessageDispatcherTest implements RequestHandler {
JChannel channel;
MessageDispatcher disp;
RspList rsp_list;
String props; // to be set by application programmer
public void start() throws Exception {
channel=new JChannel(props);
disp=new MessageDispatcher(channel, this);
channel.connect("MessageDispatcherTestGroup");
for(int i=0; i < 10; i++) {
Util.sleep(100);
System.out.println("Casting message #" + i);
byte[] payload=("Number #" + i).getBytes();
rsp_list=disp.castMessage(null,
payload, 0, payload.length,
RequestOptions.SYNC());
System.out.println("Responses:\n" +rsp_list);
}
Util.close(disp,channel);
}
public Object handle(Message msg) throws Exception {
System.out.println("handle(): " + msg);
return "Success!";
}
public static void main(String[] args) {
try {
new MessageDispatcherTest().start();
}
catch(Exception e) {
System.err.println(e);
}
}
}The example starts with the creation of a channel. Next, an instance of MessageDispatcher is created on top of the channel. Then the channel is connected. The MessageDispatcher will from now on send requests, receive matching responses (client role) and receive requests and send responses (server role).
We then send 10 messages to the group and wait for all responses. The timeout argument is 0, which causes the call to block until all responses have been received.
The handle() method simply prints out a message and returns a string. This will
be sent back to the caller as a response value (in Rsp.value). Had the call thrown an exception,
Rsp.exception would be set instead.
Finally both the MessageDispatcher and channel are closed.
4.2. RpcDispatcher
RpcDispatcher is derived from MessageDispatcher. It allows a
programmer to invoke remote methods in all (or single) cluster members and optionally wait for the return
value(s). An application will typically create a channel first, and then create an
RpcDispatcher on top of it. RpcDispatcher can be used to invoke remote methods
(client role) and at the same time be called by other members (server role).
Compared to MessageDispatcher, no handle() method needs to be implemented. Instead the methods to be called can be
placed directly in the class using regular method definitions (see example below).
The methods will get invoked using reflection.
To invoke remote method calls (unicast and multicast) the following methods are used:
public <T> RspList<T>
callRemoteMethods(Collection<Address> dests, String method_name, Object[] args,
Class[] types, RequestOptions options) throws Exception;
public <T> RspList<T>
callRemoteMethods(Collection<Address> dests, MethodCall method_call,
RequestOptions opts) throws Exception;
public <T> CompletableFuture<RspList<T>>
callRemoteMethodsWithFuture(Collection<Address> dests, MethodCall method_call,
RequestOptions options) throws Exception;
public <T> T
callRemoteMethod(Address dest, String meth, Object[] args, Class[] types,
RequestOptions opts) throws Exception;
public <T> T
callRemoteMethod(Address dest,
MethodCall call,
RequestOptions options) throws Exception;
public <T> CompletableFuture<T>
callRemoteMethodWithFuture(Address dest,
MethodCall call,
RequestOptions opts) throws ExceptionThe family of callRemoteMethods() methods is invoked with a list of receiver
addresses. If null, the method will be invoked in all cluster members (including the sender). Each call takes
the target members to invoke it on (null mean invoke on all cluster members), a method and a RequestOptions instance.
The method can be given as (1) the method name, (2) the arguments and (3) the argument types, or a
MethodCall (containing a java.lang.reflect.Method and argument) can be given instead.
As with MessageDispatcher, a RspList or a future to a RspList is returned.
The family of callRemoteMethod() methods takes almost the same parameters, except that there is only one destination
address instead of a list. If the dest argument is null, the call will fail.
The callRemoteMethod() calls return the actual result (of type T), or throw an
exception if the method threw an exception on the target member.
Java’s Reflection API is used to find the correct method in the target member according to the method name and number and types of supplied arguments. There is a runtime exception if a method cannot be resolved.
4.2.1. MethodLookup and MethodDispatcher
Using reflection to find and invoke methods is rather slow.
As an alternative, we can use method IDs and the MethodLookup or MethodInvoker interfaces to resolve
methods, which is faster and has every RPC carry less data across the wire.
Interface MethodLookup looks as follows:
public interface MethodLookup {
Method findMethod(short id);
}An implementation is given an ID and needs to return the associated Method object. Implementations typically maintain
the ID-method mappings in a hashmap and use the method ID as key into the map. This hashmap lookup is faster than
having to use Java reflection to find the method for every invocation.
A example of how to use a MethodLookup implementation is shown in
RpcDispatcherSpeedTest.
A MethodLookup still uses reflection to invoke the method against the target object. In some cases
(e.g. Quarkus), reflection is forbidden, or at least all methods to be invoked via reflection have
to be listed at compile-time (when generating the native image). This is tedious when adding/removing fields/methods,
and so a way of invoking methods completely free of Java reflection has been added to RpcDispatcher:
|
|
MethodInvoker was added in 4.1.0
|
public interface MethodInvoker {
/**
* Invokes a method associated with a given ID and the given args against the target
* @param target The object against which to invoke the method
* @param id The ID of the method
* @param args The arguments of the invocation
* @return The result. It may be null if a method returns void
* @throws Exception Thrown if the invocation threw an exception
*/
Object invoke(Object target, short id, Object[] args) throws Exception;
}An implementation can be set in the RpcDispatcher using setMethodInvoker(MethodInvoker mi). When a MethodInvoker
is present in an RpcDispatcher, it takes precedence over MethodLookup.
A MethodInvoker is given the target object, against which to invoke the method, the ID of the method to invoke and
a list of arguments. A typical implementation might do the following (copied from
ProgrammaticUPerf):
public Object invoke(Object target, short id, Object[] args) throws Exception {
ProgrammaticUPerf uperf=(ProgrammaticUPerf)target;
Boolean bool_val;
switch(id) {
case START:
return uperf.startTest();
case GET:
Integer key=(Integer)args[0];
return uperf.get(key);
case PUT:
key=(Integer)args[0];
byte[] val=(byte[])args[1];
uperf.put(key, val);
return null;
case GET_CONFIG:
return uperf.getConfig();
case SET_SYNC:
uperf.setSync((Boolean)args[0]);
return null;
case SET_OOB:
bool_val=(Boolean)args[0];
uperf.setOOB(bool_val);
return null;
...
case QUIT_ALL:
uperf.quitAll();
return null;
}
}The downside here is that this code needs to be changed when methods are added or removed, or when signatures change. However, if Java reflection cannot be used, then this may be feasible.
4.2.2. Example of using RpcDispatcher
The code below shows an example of using RpcDispatcher:
public class RpcDispatcherTest {
JChannel channel;
RpcDispatcher disp;
RspList rsp_list;
String props; // set by application
public static int print(int number) throws Exception {
return number * 2;
}
public void start() throws Exception {
MethodCall call=new MethodCall(getClass().getMethod("print", int.class));
RequestOptions opts=new RequestOptions(ResponseMode.GET_ALL, 5000);
channel=new JChannel(props);
disp=new RpcDispatcher(channel, this);
channel.connect("RpcDispatcherTestGroup");
for(int i=0; i < 10; i++) {
Util.sleep(100);
call.setArgs(i);
rsp_list=disp.callRemoteMethods(null, call, opts);
System.out.println("Responses: " + rsp_list);
}
Util.close(disp, channel);
}
public static void main(String[] args) throws Exception {
new RpcDispatcherTest().start();
}
}Class RpcDispatcher defines method print() which will be called subsequently. The entry point start() creates a
channel and an RpcDispatcher which is layered on top. Method callRemoteMethods() then invokes the remote print()
in all cluster members (also in the caller). When all responses have been received, the call returns
and the responses are printed.
As can be seen, the RpcDispatcher building block reduces the amount of code that needs to be written to implement RPC-based group communication applications by providing a higher abstraction level between the application and the primitive channels.
Asynchronous calls with futures
When invoking a synchronous call, the calling thread is blocked until the response (or responses) has been received.
A Future allows a caller to return immediately and grab the result(s) later. The methods which return futures are:
public <T> CompletableFuture<RspList<T>>
callRemoteMethodsWithFuture(Collection<Address> dests,
MethodCall method_call,
RequestOptions options) throws Exceptio;
public <T> CompleteableFuture<T>
callRemoteMethodWithFuture(Address dest,
MethodCall call,
RequestOptions options) throws Exception;A CompleteableFuture extends java.util.concurrent.Future, with its regular methods such as isDone(),
get() and cancel(). CompleteableFuture also allows to install some code that is run when the future is done.
This is shown in the following code:
CompleteableFuture<RspList<Integer>> future=dispatcher.callRemoteMethodsWithFuture(...);
future.whenComplete((result,ex) -> {
System.out.printf("result=%d\n", result);
});Here, the result (an int) is printed to stdout when available. Note that we could also have received an exception
instead of a result, in which case argument ex would have carried the exception.
4.2.3. Response filters
Response filters allow application code to hook into the reception of responses from cluster members and
can let the request-response execution and correlation code know (1) wether a response is acceptable and
(2) whether more responses are needed, or whether the call (if blocking) can return. The
RspFilter interface looks as follows:
public interface RspFilter {
boolean isAcceptable(Object response, Address sender);
boolean needMoreResponses();
}isAcceptable() is given a response value and the address of the member which sent
the response, and needs to decide whether the response is valid (should return true) or not
(should return false).
needMoreResponses() determine whether a call returns or not.
The sample code below shows how to use a RspFilter:
public void testResponseFilter() throws Exception {
final long timeout = 10 * 1000 ;
RequestOptions opts;
opts=new RequestOptions(ResponseMode.GET_ALL,
timeout, false,
new RspFilter() {
int num=0;
public boolean isAcceptable(Object response,
Address sender) {
boolean retval=((Integer)response).intValue() > 1;
if(retval)
num++;
return retval;
}
public boolean needMoreResponses() {
return num < 2;
}
});
RspList rsps=disp1.callRemoteMethods(null, "foo", null, null, opts);
System.out.println("responses are:\n" + rsps);
assert rsps.size() == 3;
assert rsps.numReceived() == 2;
}Here, we invoke a cluster wide RPC (dests=null), which blocks (mode=GET_ALL) for 10 seconds max
(timeout=10000), but also passes an instance of RspFilter to the call (in options).
The filter accepts all responses whose value is greater than 1, and returns as soon as it has received 2 responses which satisfy the above condition.
|
|
If we have a RspFilter which doesn’t terminate the call even if responses from all members have
been received, we might block forever (if no timeout was given)! For example, if we have 10 members,
and every member returns 1 or 2 as return value of foo() in the above code, then
isAcceptable() would always return false, therefore never incrementing num,
and needMoreResponses() would always return true; this would never terminate
the call if it wasn’t for the timeout of 10 seconds!This was fixed in 3.1; a blocking call will always return if we’ve received as many responses as we have members in dests, regardless of what the RspFilter says.
|
4.3. Asynchronous invocation in MessageDispatcher and RpcDispatcher
By default, a message received by a MessageDispatcher or RpcDispatcher is dispatched into application code by calling method handle() (1) of the RequestHandler interface:
public interface RequestHandler {
Object handle(Message msg) throws Exception;
default void handle(Message request, Response response) throws Exception {
throw new UnsupportedOperationException();
}
}In the case of RpcDispatcher, the handle() method (1) converts the message’s contents into a method call,
invokes the method against the target object and returns the result (or throws an exception). The return value
of handle() is then sent back to the sender of the message.
The invocation is synchronous, ie. done on the thread responsible for dispatching this particular message from the network up the stack all the way into the application. The thread is therefore unusable for the duration of the method invocation.
If the invocation takes a while, e.g. because locks are acquired or the application waits on some I/O, as the current thread is busy, another thread will be used for a different request message. This can quickly lead to the thread pool being exhausted or many messages getting queued if the pool has an associated queue.
Therefore a new way of dispatching messages to the application was devised; the asynchronous invocation API. Method
handle(Request,Response) (2) takes a request message and a Response object.The request message contains the same
information as before (e.g. a method call plus args). The Response argument is used to send a reply (if needed) at
a later time, when processing is done.
public interface Response {
void send(Object reply, boolean is_exception);
void send(Message reply, boolean is_exception);
}Response encapsulates information about the request (e.g. request ID and sender), and has method reply() to
send a response. The is_exception parameter can be set to true if the reply is actually an exception, e.g.
that was thrown when handle() ran application code.
The second method takes a Message which needs to carry the serialized reply in its payload. This method can be used to control the type of message that’s sent out, ie. by setting flags, adding headers and so on.
The advantage of the new API is that it can, but doesn’t have to, be used asynchronously. The default implementation still uses the synchronous invocation style:
public void handle(Message request, Response response) throws Exception {
Object retval=handle(request);
if(response != null)
response.send(retval, false);
}Method handle() is called, which synchronously calls into application code and returns a result, which is
subsequently sent back to the sender of the request message.
However, an application could subclass MessageDispatcher or RpcDispatcher (as done in Infinispan), or it
could set a custom request handler via MessageDispatcher.setRequestHandler(), and implement handle() by
dispatching the processing to a thread from a thread pool. The thread which guided the request message from
the network up to this point would be therefore immediately released and could be used to process other messages.
The response would be sent whenever the invocation of application code is done, and thus the thread from the thread pool would not be blocked on I/O, trying to acquire locks or anything else that blocks in application code.
To set the mode which is used, method MessageDispatcher.asyncDispatching(boolean) can be used. This can be
changed even at runtime, to switch between sync and async invocation style.
Asynchrounous invocation is typically used in conjunction with an application thread pool. The application knows (JGroups doesn’t) which requests can be processed in parallel and which ones can’t. For example, all OOB calls could be dispatched directly to the thread pool, as ordering of OOB requests is not important, but regular requests should be added to a queue where they are processed sequentually.
The main benefit here is that request dispatching (and ordering) is now under application control if the application wants to do that. If not, we can still use synchronous invocation.
A good example where asynchronous invocation makes sense are replicated web sessions. If a cluster node A has 1000 web sessions, then replication of updates across the cluster generates messages from A. Because JGroups delivers messages from the same sender sequentially, even updates to unrelated web sessions are delivered in strict order.
With asynchronous invocation, the application could devise a dispatching strategy which assigns updates to different (unrelated) web sessions to any available thread from the pool, but queues updates to the same session, and processes those by the same thread, to provide ordering of updates to the same session. This would speed up overall processing, as updates to a web session 1 on A don’t have to wait until all updates to an unrelated web session 2 on A have been processed.
|
|
The asynchronous invocation API was added in JGroups 3.3. |
4.4. ReplicatedHashMap
This class was written as a demo of how state can be shared between nodes of a cluster. It has never been heavily tested and is therefore not meant to be used in production.
A ReplicatedHashMap uses a concurrent hashmap internally and allows to create several
instances of hashmaps in different processes. All of these instances have exactly the same state at all
times. When creating such an instance, a cluster name determines which cluster of replicated hashmaps will
be joined. The new instance will then query the state from existing members and update itself before
starting to service requests. If there are no existing members, it will simply start with an empty state.
Modifications such as put(), clear() or
remove() will be propagated in orderly fashion to all replicas. Read-only requests
such as get() will only be invoked on the local hashmap.
Since both keys and values of a hashtable will be sent across the network, they have to be serializable. Putting a non-serializable value in the map will result in an exception at marshalling time.
A ReplicatedHashMap allows to register for notifications, e.g. when data is
added removed. All listeners will get notified when such an event occurs. Notification is always local;
for example in the case of removing an element, first the element is removed in all replicas, which then
notify their listener(s) of the removal (after the fact).
ReplicatedHashMap allow members in a group to share common state across process and machine boundaries.
4.5. ReplCache
ReplCache is a distributed cache which - contrary to ReplicatedHashMap - doesn’t replicate its values to
all cluster members, but just to selected backups.
A put(K,V,R) method has a replication count R which determines
on how many cluster members key K and value V should be stored. When we have 10 cluster members, and R=3,
then K and V will be stored on 3 members. If one of those members goes down, or leaves the cluster, then a
different member will be told to store K and V. ReplCache tries to always have R cluster members store K
and V.
A replication count of -1 means that a given key and value should be stored on all cluster members.
The mapping between a key K and the cluster member(s) on which K will be stored is always deterministic, and is computed using a consistent hash function.
Note that this class was written as a demo of how state can be shared between nodes of a cluster. It has never been heavily tested and is therefore not meant to be used in production.
4.6. Cluster wide locking
LockService can be used to acquire locks on a cluster-wide basis; ie. only one node can acquire a given lock. E.g. if
member B acquires lock L, and member C also tries to acquire L, then C will block until B releases L
(or leaves /crashes)
The new service is implemented as a building block (org.jgroups.blocks.locking.LockService) and a protocol
(CENTRAL_LOCK or CENTRAL_LOCK2). LockService looks up the protocol and talks to it via events. If no locking
protocol is found, LockService won’t start and will throw an exception.
The main abstraction of a distributed lock is an implementation of java.util.concurrent.locks.Lock.
Below is an example of how LockService is typically used:
// locking.xml needs to contain a locking protocol, e.g. CENTRAL_LOCK
JChannel ch=new JChannel("/home/bela/locking.xml");
LockService lock_service=new LockService(ch);
ch.connect("lock-cluster");
Lock lock=lock_service.getLock("mylock"); // gets a cluster-wide lock
lock.lock();
try {
// do something with the locked resource
}
finally {
lock.unlock();
}In the example, we create a channel, then a LockService, then connect the channel. If the channel’s
configuration doesn’t include a locking protocol, an exception will be thrown.
Then we grab a lock named "mylock", which we lock and subsequently unlock. If another member P had already
acquired "mylock", we’d block until P released the lock, or P left the cluster or crashed.
Note that the owner of a lock is always a given thread in a cluster, so the owner is the JGroups address and
the thread ID. This means that different threads inside the same JVM trying to access the same named lock
will compete for it. If thread-22 grabs the lock first, then thread-5 will block until thread-22
releases the lock.
|
|
If we want the lock owner to only be the address (and not the thread-id), then property
use_thread_id_for_lock_owner can be set to false. This means that all threads in a given node can lock or unlock
a given lock. Example: thread T1 locks "lock", but thread T2 can unlock it. This is not the same semantics as
java.util.concurrent.locks.Lock, but nevertheless useful in some scenarios. (Introduced in 3.6)
|
JGroups includes a demo (org.jgroups.demos.LockServiceDemo), which can be used to interactively experiment
with distributed locks. LockServiceDemo -h dumps all command line options.
There are two protocols which provides locking: CENTRAL_LOCK and CENTRAL_LOCK2.
Note that the locking protocol has to be placed at or towards the top of the stack (close to the channel), because it
requires reliable unicasts and multicasts (e.g. provided by UNICAST3 and NAKACK2).
4.6.1. Locking and merges
The following scenario is susceptible to network partitioning and subsequent merging: we have a cluster
view of {A,B,C,D} and then the cluster splits into {A,B} and {C,D}. Assume that B and D now acquire a
lock "mylock". This is what happens (with the locking protocol being CENTRAL_LOCK):
-
There are 2 coordinators: A for
{A,B}and C for{C,D} -
B successfully acquires
"mylock"from A -
D successfully acquires
"mylock"from C -
The partitions merge back into
{A,B,C,D}. Now, only A is the coordinator, but C ceases to be a coordinator -
Problem: D still holds a lock which should actually be invalid! There is no easy way (via the Lock API) to remove the lock from D. We could for example simply release D’s lock on
"mylock", but then there’s no way telling D that the lock it holds is actually stale!
Therefore the recommended solution here is for nodes to listen to MergeView changes if they expect
merging to occur, and re-acquire all of their locks after a merge, e.g.:
Lock l1, l2, l3;
LockService lock_service;
...
public void viewAccepted(View view) {
if(view instanceof MergeView) {
new Thread() {
public void run() {
lock_service.unlockAll();
// stop all access to resources protected by l1, l2 or l3
// every thread needs to re-acquire the locks it holds
}
}.start();
}
}4.6.2. Locking and merges (updated)
With CENTRAL_LOCK2, merging of partitions is handled differently. Contrary to CENTRAL_LOCK, which has the coordinator back up its lock tables to one or more backup members, CENTRAL_LOCK2 doesn’t do this.
Instead, when the current coordinator leaves or crashes, the new coordinator fetches information about locks and pending lock/unlock requests from all members, and then builds its lock table based on this information.
In the above scenario with both B and D holding mylock, in case of a merge (say A becomes the new coordinator), D
will be told that its lock mylock has been revoked. This means that D needs to force-unlock D. This can be done
in the lockRevoked() callback, e.g.:
LockService lock_service;
...
public void lockRevoked(String lock_name, Owner current_owner) {
lock_service.unlockForce(lock_name);
}This is maginally better than CENTRAL_LOCK, but admittedly less than ideal. Given the following code:
Lock lock=lock_service.get("mylock";
lock.lock();
try {
// do something while the lock is held
longRunningAction();
}
finally {
lock.unlock
}When mylock is revoked, longRunningAction() should be stopped immediately, or - even better - its changes should be
undone (like in a transaction). However, this isn’t feasible and would unnecessarily complicate the code.
Here, we see that the Lock abstraction, as easy as it is and as often it is used locally (inside the same JVM),
may not be the best abstraction for a distributed setting!
4.7. Cluster wide task execution
In 2.12, a distributed execution service was added. The new service is implemented as a protocol and is used
via org.jgroups.blocks.executor.ExecutionService.
ExecutionService extends java.util.concurrent.ExecutorService and distributes tasks
submitted to it across the cluster, trying to distribute the tasks to the cluster members as evenly as
possible. When a cluster member leaves or dies, the tasks is was processing are re-distributed to other
members in the cluster.
ExecutionService talks to the executing protocol via events. The main abstraction is an implementation of
java.util.concurrent.ExecutorService. All methods are supported. The restrictions are however that
the callable or runnable must be Serializable, Externalizable or Streamable. Also the result produced
from the future needs to be Serializable, Externalizable or Streamable. If the Callable or Runnable are not,
then an IllegalArgumentException is immediately thrown. If a result is not, then a NotSerializableException
with the name of the class will be returned to the Future as an exception cause.
Below is an example of how ExecutionService is typically used:
// executing.xml needs to have an execution protocol, e.g. CENTRAL_EXECUTOR
JChannel ch = new JChannel("/home/bela/executing.xml");
ExecutionService exec_service = new ExecutionService(ch);
ch.connect("exec-cluster");
Future<Value> future = exec_service.submit(new MyCallable());
try {
Value value = future.get();
// Do something with value
}
catch (InterruptedException e) {
e.printStackTrace();
}
catch (ExecutionException e) {
e.getCause().printStackTrace();
}In the example, we create a channel, then an ExecutionService, then connect the channel. Then we submit our callable giving us a Future. Then we wait for the future to finish returning our value and do something with it. If any exception occurs we print the stack trace of that exception.
The ExecutionService follows the Producer-Consumer Pattern very closely. The ExecutionService is used as the Producer for this Pattern. Therefore the service only passes tasks off to be handled and doesn’t do anything with the actual invocation of those tasks. There is a separate class that can was written specifically as a consumer, which can be ran on any node of the cluster. This class is ExecutionRunner and implements java.lang.Runnable.
A user is required to run one or more instances of a ExecutionRunner on a node of the cluster. By having a thread run one of these runners, that thread has now volunteered to be able to run any task that is submitted to the cluster via an ExecutionService. This allows for any node in the cluster to participate or not participate in the running of these tasks and also any node can optionally run more than 1 ExecutionRunner if this node has additional capacity to do so. A runner will run indefinitely until the thread that is currently running it is interrupted. If a task is running when the runner is interrupted the task will be interrupted.
Below is an example of how simple it is to have a single node start and allow for 10 distributed tasks to be executed simultaneously on it:
int runnerCount = 10;
// locking.xml needs to have a locking protocol
JChannel ch = new JChannel("/home/bela/executing.xml");
ch.connect("exec-cluster");
ExecutionRunner runner = new ExecutionRunner(ch);
ExecutorService service = Executors.newFixedThreadPool(runnerCount);
for (int i = 0; i < runnerCount; ++i) {
// If you want to stop the runner hold onto the future
// and cancel with interrupt.
service.submit(runner);
}In the example, we create a channel, then connect the channel, then an ExecutionRunner. Then we create a java.util.concurrent.ExecutorService that is used to start 10 threads that each thread runs the ExecutionRunner. This allows for this node to have 10 threads actively accept and work on requests submitted via any ExecutionService in the cluster.
Since an ExecutionService does not allow for non serializable class instances to be sent across as tasks there are two utility classes provided to get around this problem. For users that are used to using a CompletionService with an Executor there is an equivalent ExecutionCompletionService provided that allows for a user to have the same functionality. It would have been preferred to allow for the same ExecutorCompletionService to be used, but due to its implementation using a non serializable object the ExecutionCompletionService was implemented to be used instead in conjunction with an ExecutionService.
Also a utility class was designed to help users to submit tasks which use a non serializable class. The Executions class contains a method serializableCallable which allows for a user to pass a constructor of a class that implements Callable and its arguments to then return to a user a Callable that will upon running will automatically create and object from the constructor passing the provided arguments to it and then will call the call method on the object and return it’s result as a normal callable. All the arguments provided must still be serializable and the return object as detailed previously.
JGroups includes a demo (org.jgroups.demos.ExecutionServiceDemo), which can be used to interactively
experiment with a distributed sort algorithm and performance. This is for demonstration purposes and
performance should not be assumed to be better than local.
ExecutionServiceDemo -h dumps all command line options.
There is one protocol which provide executions: CENTRAL_EXECUTOR. The executing protocol has to be placed at or towards the top of the stack (close to the channel).
4.8. Cluster wide atomic counters
Cluster wide counters provide named counters (similar to AtomicLong) which can be changed atomically. Two nodes incrementing the same counter with initial value 10 will see 11 and 12 as results, respectively.
To create a named counter, the following steps have to be taken:
-
✓ Add protocol
COUNTERto the top of the stack configuration -
✓ Create an instance of CounterService
-
✓ Create a new or get an existing named counter
-
✓ Use the counter to increment, decrement, get, set, compare-and-set etc the counter
In the first step, we add COUNTER to the top of the protocol stack configuration:
<config>
...
<MFC max_credits="2M"
min_threshold="0.4" />
<FRAG2 frag_size="60K" />
<COUNTER bypass_bundling="true" timeout="5000" />
</config>Configuration of the COUNTER protocol is described in COUNTER.
Next, we create a CounterService, which is used to create and delete named counters:
ch = new JChannel(props);
CounterService counter_service = new CounterService(ch);
ch.connect("counter-cluster");
Counter counter = counter_service.getOrCreateCounter("mycounter", 1);In the sample code above, we create a channel first, then create the CounterService referencing the channel.
Then we connect the channel and finally create a new named counter "mycounter", with an initial value of 1.
If the counter already exists, the existing counter will be returned and the initial value will be ignored.
CounterService doesn’t consume any messages from the channel over which it is created; instead it grabs a reference to the COUNTER protocols and invokes methods on it directly. This has the advantage that CounterService is non-intrusive: many instances can be created over the same channel. CounterService even co-exists with other services which use the same mechanism, e.g. LockService or ExecutionService (see above).
The returned counter instance implements interface Counter:
package org.jgroups.blocks.atomic;
public interface Counter {
public String getName();
/**
* Gets the current value of the counter
* @return The current value
*/
public long get();
/**
* Sets the counter to a new value
* @param new_value The new value
*/
public void set(long new_value);
/**
* Atomically updates the counter using a CAS operation
*
* @param expect The expected value of the counter
* @param update The new value of the counter
* @return True if the counter could be updated, false otherwise
*/
public boolean compareAndSet(long expect, long update);
/**
* Atomically increments the counter and returns the new value
* @return The new value
*/
public long incrementAndGet();
/**
* Atomically decrements the counter and returns the new value
* @return The new value
*/
public long decrementAndGet();
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the updated value
*/
public long addAndGet(long delta);
}4.8.1. Design
The design of COUNTER is described in detail in CounterService.txt.
In a nutshell, in a cluster the current coordinator maintains a hashmap of named counters. Members send requests (increment, decrement etc) to it, and the coordinator atomically applies the requests and sends back responses.
The advantage of this centralized approach is that - regardless of the size of a cluster - every request has a constant execution cost, namely a network round trip.
A crash or leaving of the coordinator is handled as follows. The coordinator maintains a version for every counter value. Whenever the counter value is changed, the version is incremented. For every request that modifies a counter, both the counter value and the version are returned to the requester. The requester caches all counter values and associated versions in its own local cache.
When the coordinator leaves or crashes, the next-in-line member becomes the new coordinator. It then starts a reconciliation phase, and discards all requests until the reconciliation phase has completed. The reconciliation phase solicits all members for their cached values and versions. To reduce traffic, the request also carries all version numbers with it.
The clients return values whose versions are higher than the ones shipped by the new coordinator. The new coordinator waits for responses from all members or timeout milliseconds. Then it updates its own hashmap with values whose versions are higher than its own. Finally, it stops discarding requests and sends a resend message to all clients in order to resend any requests that might be pending.
There’s another edge case that also needs to be covered: if a client P updates a counter, and both P and the coordinator crash, then the update is lost. To reduce the chances of this happening, COUNTER can be enabled to replicate all counter changes to one or more backup coordinators. The num_backups property defines the number of such backups. Whenever a counter was changed in the current coordinator, it also updates the backups (asynchronously). 0 disables this.
5. Advanced Concepts
This chapter discusses some of the more advanced concepts of JGroups with respect to using it and setting it up correctly.
5.1. Using multiple channels
When using a fully virtual synchronous protocol stack, the performance may not be great because of the larger number of protocols present. For certain applications, however, throughput is more important than ordering, e.g. for video/audio streams or airplane tracking. In the latter case, it is important that airplanes are handed over between control domains correctly, but if there are a (small) number of radar tracking messages (which determine the exact location of the plane) missing, it is not a problem. The first type of messages do not occur very often (typically a number of messages per hour), whereas the second type of messages would be sent at a rate of 10-30 messages/second. The same applies for a distributed whiteboard: messages that represent a video or audio stream have to be delivered as quick as possible, whereas messages that represent figures drawn on the whiteboard, or new participants joining the whiteboard have to be delivered according to a certain order.
The requirements for such applications can be solved by using two separate channels: one for control messages such as group membership, floor control etc and the other one for data messages such as video/audio streams (actually one might consider using one channel for audio and one for video). The control channel might use virtual synchrony, which is relatively slow, but enforces ordering and retransmission, and the data channel might use a simple UDP channel, possibly including a fragmentation layer, but no retransmission layer (losing packets is preferred to costly retransmission).
5.2. Transport protocols
A transport protocol refers to the protocol at the bottom of the protocol stack which is responsible for sending messages to and receiving messages from the network. There are a number of transport protocols in JGroups. They are discussed in the following sections.
A typical protocol stack configuration using UDP is:
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups-4.2.xsd">
<UDP
mcast_port="${jgroups.udp.mcast_port:45588}"
ucast_recv_buf_size="5M"
ucast_send_buf_size="640K"
mcast_recv_buf_size="5M"
mcast_send_buf_size="640K"
max_bundle_size="64K"
ip_ttl="${jgroups.udp.ip_ttl:2}"
enable_diagnostics="true"
thread_pool.min_threads="2"
thread_pool.max_threads="8"
thread_pool.keep_alive_time="5000"/>
<PING />
<MERGE3 max_interval="30000"
min_interval="10000"/>
<FD_SOCK/>
<FD_ALL/>
<VERIFY_SUSPECT timeout="1500" />
<BARRIER />
<pbcast.NAKACK2 use_mcast_xmit="true"
discard_delivered_msgs="true"/>
<UNICAST3 />
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="4M"/>
<pbcast.GMS print_local_addr="true" join_timeout="2000"/>
<UFC max_credits="2M"
min_threshold="0.4"/>
<MFC max_credits="2M"
min_threshold="0.4"/>
<FRAG2 frag_size="60K" />
<pbcast.STATE_TRANSFER />
</config>In a nutshell the properties of the protocols are:
- UDP
-
This is the transport protocol. It uses IP multicasting to send messages to the entire cluster, or individual nodes. Other transports include TCP, TCP_NIO2 and TUNNEL.
- PING
-
This is the discovery protocol. It uses IP multicast (by default) to find initial members. Once found, the current coordinator can be determined and a unicast JOIN request will be sent to it in order to join the cluster.
- MERGE3
-
Will merge sub-clusters back into one cluster, kicks in after a network partition healed.
- FD_SOCK
-
Failure detection based on sockets (in a ring form between members). Generates notification if a member fails
- FD / FD_ALL
-
Failure detection based on heartbeat are-you-alive messages. Generates notification if a member fails
- VERIFY_SUSPECT
-
Double-checks whether a suspected member is really dead, otherwise the suspicion generated from protocol below is discarded
- BARRIER
-
Needed to transfer state; this will block messages that modify the shared state until a digest has been taken, then unblocks all threads. Not needed if no state transfer protocol is present.
- pbcast.NAKACK2
-
Ensures (a) message reliability and (b) FIFO. Message reliability guarantees that a message will be received. If not, the receiver(s) will request retransmission. FIFO guarantees that all messages from sender P will be received in the order P sent them
- UNICAST3
-
Same as NAKACK for unicast messages: messages from sender P will not be lost (retransmission if necessary) and will be in FIFO order (conceptually the same as TCP in TCP/IP)
- pbcast.STABLE
-
Deletes messages that have been seen by all members (distributed message garbage collection)
- pbcast.GMS
-
Membership protocol. Responsible for joining/leaving members and installing new views.
- UFC
-
Unicast Flow Control. Provides flow control between 2 members.
- MFC
-
Multicast Flow Control. Provides flow control between a sender and all cluster members.
- FRAG2
-
Fragments large messages into smaller ones and reassembles them back at the receiver side. For both multicast and unicast messages
- STATE_TRANSFER
-
Ensures that state is correctly transferred from an existing member (usually the coordinator) to a new member.
5.2.1. Message bundling
Message bundling is beneficial when sending many small messages; they are queued until a threshold (number of bytes) has been exceeded. Then, the queued messages are assembled into a message batch (see MessageBatch) and the batch is sent.
At the receiver, the message batch is passed up the stack, so protocols and/or the application can process multiple messages in one shot.
When sending many smaller messages, the ratio between payload and message headers might be small; say we send a "hello" string: the payload here is 7 bytes, whereas the addresses and headers (depending on the stack configuration) might be 30 bytes. However, if we bundle (say) 100 messages, then the payload of the large message is 700 bytes, but the header is still 30 bytes. Thus, we’re able to send more actual data across the wire with a message batch than with many small messages.
|
|
A message batch of 100 messages contains the sender’s and destination address and the cluster name only once.
If the cluster name is 10 bytes, then we save roughly
99*10 + 99 * 18 *2 (assuming non-null destination addresses and IPv4) = 4500 bytes.
|
Message bundling/batching is conceptually similar to TCP’s Nagle algorithm.
A sample configuration is shown below:
<UDP max_bundle_size="64K"/>Here, bundling is enabled (the default). The max accumulated size is 64'000 bytes.
If at time T0, we’re sending 10 smaller messages with an accumulated size of 2'000 bytes, but then send no more messages, then a message batch of 10 will be sent immediately after the 10th message has been sent.
If we send 1000 messages of 100 bytes each, then - after exceeding 64'000 bytes (after ca. 64 messages) - we’ll send the message batch, and this might have taken only 3 ms.
|
|
Since 3.x, message bundling is the default, and it cannot be enabled or disabled anymore (the config
is ignored). However, a message can set the DONT_BUNDLE flag to skip message bundling. This is only recognized
for OOB messages, so if a message needs to skip bundling, it needs to have flags OOB and DONT_BUNDLE set.
|
Message bundling and performance
As with Nagling, message bundling/batching can affect latency. In most scenarios, latency should be small as a message
batch is sent when either max_bundle_size bytes have accumulated, or no more messages are sent. The algorithm for
bundling looks more or less like this:
If enough space in the queue:
queue message, get next message
If max_bundle_size exceeded, or no more message -> send message batch
When the message send rate is high and/or many large messages are sent, latency is more or less the time to fill
max_bundle_size. This should be sufficient for a lot of applications. If not, flags OOB and DONT_BUNDLE can be
used to bypass bundling.
5.2.2. UDP
UDP uses IP multicasting for sending messages to all members of a cluster, and UDP datagrams for unicast messages (sent to a single member). When started, it opens a unicast and multicast socket: the unicast socket is used to send/receive unicast messages, while the multicast socket sends/receives multicast messages. The physical address of the channel will be the address and port number of the unicast socket.
Using UDP and plain IP multicasting
A protocol stack with UDP as transport protocol is typically used with clusters whose members run on the same host or are distributed across a LAN. Note that before running instances in different subnets, an admin has to make sure that IP multicast is enabled across subnets. It is often the case that IP multicast is not enabled across subnets. Refer to section It doesn’t work! for running a test program that determines whether members can reach each other via IP multicast. If this does not work, the protocol stack cannot use UDP with IP multicast as transport. In this case, the stack has to either use UDP without IP multicasting, or use a different transport such as TCP.
Using UDP without IP multicasting
The protocol stack with UDP and PING as the bottom protocols use IP multicasting by default to send messages to all members (UDP) and for discovery of the initial members (PING). However, if multicasting cannot be used, the UDP and PING protocols can be configured to send multiple unicast messages instead of one multicast message.
|
|
Although not as efficient (and using more bandwidth), it is sometimes the only possibility to reach group members. |
To configure UDP to use multiple unicast messages to send a group message instead of using IP
multicasting, the ip_mcast property has to be set to false.
If we disable ip_mcast, we now also have to change the discovery protocol (PING). Because PING requires IP multicasting to be enabled in the transport, we cannot use it. Some of the alternatives are TCPPING (static list of member addresses), TCPGOSSIP (external lookup service), FILE_PING (shared directory), BPING (using broadcasts) or JDBC_PING (using a shared database).
See Initial membership discovery for details on configuration of different discovery protocols.
5.2.3. TCP
TCP is a replacement for UDP as transport in cases where IP multicast cannot be used. This may be the case when operating over a WAN, where routers might discard IP multicast packets. Usually, UDP is used as transport in LANs, while TCP is used for clusters spanning WANs.
The properties for a typical stack based on TCP might look like this (edited for brevity):
<TCP bind_port="7800" />
<TCPPING initial_hosts="${jgroups.tcpping.initial_hosts:HostA[7800],HostB[7801]}"
port_range="1"/>
<VERIFY_SUSPECT timeout="1500" />
<pbcast.NAKACK2 use_mcast_xmit="false"
discard_delivered_msgs="true"/>
<UNICAST3/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="2000"/>- TCP
-
The transport protocol, uses TCP (from TCP/IP) to send unicast and multicast messages. In the latter case, it sends multiple unicast messages.
- TCPPING
-
Discovers the initial membership to determine coordinator. Join request will then be sent to coordinator.
- VERIFY_SUSPECT
-
Double checks that a suspected member is really dead
- pbcast.NAKACK2
-
Reliable and FIFO multicast message delivery
- UNICAST3
-
Reliable unicast message delivery
- pbcast.STABLE
-
Distributed garbage collection of messages seen by all members
- pbcast.GMS
-
Membership services. Takes care of joining and removing new/old members, emits view changes
When using TCP, each message to all of the cluster members is sent as multiple unicast messages (one to each member). Due to the fact that IP multicasting cannot be used to discover the initial members, another mechanism has to be used to find the initial membership. There are a number of alternatives (see Initial membership discovery for a discussion of all discovery protocols):
-
TCPPING: uses a list of well-known group members that it contacts for initial membership
-
TCPGOSSIP: this requires a GossipRouter (see below), which is an external process, acting as a lookup service. Cluster members register with under their cluster name, and new members query the GossipRouter for initial cluster membership information.
5.2.4. TCP_NIO2
This is a TCP/IP based implementation based on non blocking IO (NIO2).
Details at TCP_NIO2.
Using TCP and TCPPING
A protocol stack using TCP and TCPPING looks like this (other protocols omitted):
<TCP bind_port="7800" /> +
<TCPPING initial_hosts="HostA[7800],HostB[7800]"
port_range="2" />The concept behind TCPPING is that some selected cluster members assume the role of well-known hosts
from which the initial membership information can be retrieved. In the example,
HostA and HostB are designated members that will be
used by TCPPING to lookup the initial membership. The property bind_port
in TCP means that each member should try to assign port 7800 for itself.
If this is not possible it will try the next higher port (7801) and so on, until
it finds an unused port.
TCPPING will try to contact both HostA and
HostB, starting at port 7800 and ending at port
7800 + port_range, in the above example ports 7800 -
7802. Assuming that at least one of HostA or
HostB is up, a response will be received. To be absolutely sure to receive
a response, it is recommended to add all the hosts on which members of the cluster will be running
to the configuration.
Using TCP and TCPGOSSIP
TCPGOSSIP uses one or more GossipRouters to (1) register itself and (2) fetch information about already registered cluster members. A configuration looks like this:
<TCP />
<TCPGOSSIP initial_hosts="HostA[5555],HostB[5555]" />The initial_hosts property is a comma-delimited list of GossipRouters.
In the example there are two GossipRouters on HostA and HostB, at port 5555.
A member always registers with all GossipRouters listed, but fetches information from the first available GossipRouter. If a GossipRouter cannot be accessed, it will be marked as failed and removed from the list. A task is then started, which tries to periodically reconnect to the failed process. On reconnection, the failed GossipRouter is marked as OK, and re-inserted into the list.
The advantage of having multiple GossipRouters is that, as long as at least one is running, new members will always be able to retrieve the initial membership.
Note that the GossipRouter should be started before any of the members.
5.2.5. TUNNEL
Firewalls are usually placed at the connection to the internet. They shield local networks from outside attacks by screening incoming traffic and rejecting connection attempts to host inside the firewalls by outside machines. Most firewall systems allow hosts inside the firewall to connect to hosts outside it (outgoing traffic), however, incoming traffic is most often disabled entirely.
Tunnels are host protocols which encapsulate other protocols by multiplexing them at one end and demultiplexing them at the other end. Any protocol can be tunneled by a tunnel protocol.
The most restrictive setups of firewalls usually disable all incoming traffic, and only enable a few selected ports for outgoing traffic. In the solution below, it is assumed that one TCP port is enabled for outgoing connections to the GossipRouter.
JGroups has a mechanism that allows a programmer to tunnel a firewall. The solution involves a GossipRouter, which has to be outside of the firewall, so other members (possibly also behind firewalls) can access it.
The solution works as follows. A channel inside a firewall has to use protocol TUNNEL instead of UDP or TCP as transport. The recommended discovery protocol is PING. Here’s a configuration:
<TUNNEL gossip_router_hosts="HostA[12001]" />
<PING />TUNNEL uses a GossipRouter (outside the firewall) running on HostA at port
12001 for tunneling. Note that it is not recommended to use TCPGOSSIP for discovery if
TUNNEL is used (use PING instead). TUNNEL accepts one or multiple GossipRouters tor tunneling;
they can be listed as a comma delimited list of host[port] elements specified in property
gossip_router_hosts.
TUNNEL establishes a TCP connection to the GossipRouter process (outside the firewall) that accepts messages from members and passes them on to other members. This connection is initiated by the host inside the firewall and persists as long as the channel is connected to a group. A GossipRouter will use the same connection to send incoming messages to the channel that initiated the connection. This is perfectly legal, as TCP connections are fully duplex. Note that, if GossipRouter tried to establish its own TCP connection to the channel behind the firewall, it would fail. But it is okay to reuse the existing TCP connection, established by the channel.
Note that TUNNEL has to be given the hostname and port of the GossipRouter process.
This example assumes a GossipRouter is running on HostA at port12001.
TUNNEL accepts one or multiple router hosts as a comma delimited list of host[port] elements specified in
property gossip_router_hosts.
Any time a message has to be sent, TUNNEL forwards the message to GossipRouter, which distributes it to its destination: if the message’s destination field is null (send to all group members), then GossipRouter looks up the members that belong to that group and forwards the message to all of them via the TCP connections they established when connecting to GossipRouter. If the destination is a valid member address, then that member’s TCP connection is looked up, and the message is forwarded to it.
|
|
To do so, GossipRouter maintains a mapping between cluster names and member addresses, and TCP connections. |
A GossipRouter is not a single point of failure. In a setup with multiple gossip routers, the routers do not communicate among themselves, and a single point of failure is avoided by having each channel simply connect to multiple available routers. In case one or more routers go down, the cluster members are still able to exchange messages through any of the remaining available router instances, if there are any.
For each send invocation, a channel goes through a list of available connections to routers and attempts to send the message on each connection until it succeeds. If a message can not be sent on any of the connections, an exception is raised. The default policy for connection selection is random. However, we provide an plug-in interface for other policies as well.
The GossipRouter configuration is static and is not updated for the lifetime of the channel. A list of available routers has to be provided in the channel’s configuration file.
To tunnel a firewall using JGroups, the following steps have to be taken:
-
✓ Check that a TCP port (e.g. 12001) is enabled in the firewall for outgoing traffic
-
✓ Start the GossipRouter:
java org.jgroups.stack.GossipRouter -port 12001
-
✓ Configure the TUNNEL protocol layer as instructed above.
-
✓ Create a channel
The general setup is shown in Tunneling a firewall:
First, the GossipRouter process is created on host B. Note that host B should be outside the firewall, and all channels in the same group should use the same GossipRouter process. When a channel on host A is created, its TCPGOSSIP protocol will register its address with the GossipRouter and retrieve the initial membership (assume this is C). Now, a TCP connection with the GossipRouter is established by A; this will persist until A crashes or voluntarily leaves the group. When A multicasts a message to the cluster, GossipRouter looks up all cluster members (in this case, A and C) and forwards the message to all members, using their TCP connections. In the example, A would receive its own copy of the multicast message it sent, and another copy would be sent to C.
This scheme allows for example Java applets , which are only allowed to connect back to the host from which they were downloaded, to use JGroups: the HTTP server would be located on host B and the gossip and GossipRouter daemon would also run on that host. An applet downloaded to either A or C would be allowed to make a TCP connection to B. Also, applications behind a firewall would be able to talk to each other, joining a group.
However, there are several drawbacks: first, having to maintain a TCP connection for the duration of the connection might use up resources in the host system (e.g. in the GossipRouter), leading to scalability problems, second, this scheme is inappropriate when only a few channels are located behind firewalls, and the vast majority can indeed use IP multicast to communicate, and finally, it is not always possible to enable outgoing traffic on 2 ports in a firewall, e.g. when a user does not own the firewall.
5.3. The transport in detail
The transport is always the protocol at the bottom of the stack, responsible for sending and receiving messages.
It contains most of the resources, such as the thread pool for handling of incoming messages, sockets for sending and receiving of messages, and thread and socket factories.
The transport is shown in The transport protocol.
The transport consists of a thread pool (java.util.concurrent.ThreadPoolExecutor) which handles all types of messages
(internal, OOB and regular) and is also used by the timer to fire tasks (e.g. retransmission tasks) at fixed or
dynamic intervals.
When a (UDP or TCP) socket receives a message or message batch, it passes the message to the thread pool for processing.
When the thread pool is disabled, then we use the thread of the caller (e.g. multicast or unicast receiver threads or the ConnectionTable) to send the message up the stack and into the application.
Otherwise, the packet will be processed by a thread from the thread pool, which sends the message up the stack. When all current threads are busy, another thread might be created, up to the maximum number of threads defined. Alternatively, the packet might get dropped if the pool is exhausted.
The point of using a thread pool is that the receiver threads should only receive the packets and forward them to the thread pools for processing, because unmarshalling and processing is slower than simply receiving the message and can benefit from parallelization.
5.3.1. Configuration
Here’s an example of the new configuration:
<UDP
thread_naming_pattern="cl"
thread_pool.enabled="true"
thread_pool.min_threads="0"
thread_pool.max_threads="100"
thread_pool.keep_alive_time="20000" />The attributes for the thread pools are prefixed with thread_pool respectively.
The attributes are listed below. They roughly correspond to the options of java.util.concurrent.ThreadPoolExecutor.
| Name | Description |
|---|---|
thread_naming_pattern |
Determines how threads are named that are running from thread pools in concurrent stack. Valid values include any combination of "cl" letters, where "c" includes the cluster name and "l" includes local address of the channel. The default is "cl". |
enabled |
Whether or not to use a thread pool. If set to false, the caller’s thread is used. |
min_threads |
The minimum number of threads to use. |
max_threads |
The maximum number of threads to use. |
keep_alive_time |
Number of milliseconds until an idle thread is removed from the pool |
5.3.2. Message delivery and ordering
A message is considered delivered as soon as the receive() callback returns. While messages are received in a
non-defined order, the reliable protocols (NAKACK2 and UNICAST3) establish an order in which messages are delivered.
Regular messages or message batches from a sender P are delivered in the order in which they were sent. E.g. if P
sent messages 4 and 5, then the application’s receive() callback will be invoked with 4, and when 4 returns, with
message 5. Alternatively, the application might receive a message batch containing messages 4 and 5. When iterating
through that batch, message 4 will be consumed before message 5.
Regular messages from different senders P and Q are delivered in parallel. E.g if P sends 4 and 5 and Q sends 56 and 57,
then the receive() callback might get invoked in parallel for P4 and Q57. Therefore the receive() callbacks
have to be thread-safe.
In contrast, OOB messages are delivered in an undefined order, e.g. messages P4 and P5 might get delivered as P4 → P5 (P4 followed by P5) in some receivers and P5 → P4 in others. It is also possible that P4 is delivered in parallel with P5, each message getting delivered by a different thread.
The only guarantee for both regular and OOB messages is that a message will get delivered exactly once. Dropped messages are retransmitted and duplicate messages are dropped.
Out-of-band messages
OOB messages completely ignore any ordering constraints the stack might have.
This is necessary in cases where we don’t want the message processing to wait until all other messages from the same sender have been processed, e.g. in the heartbeat case: if sender P sends 5 messages and then a response to a heartbeat request received from some other node, then the time taken to process P’s 5 messages might take longer than the heartbeat timeout, so that P might get falsely suspected!
However, if the heartbeat response is marked as OOB, then it will get processed in parallel to the other 5 messages from P and not trigger a false suspicion.
The unit tests UNICAST_OOB_Test and NAKACK_OOB_Test demonstrate how OOB messages influence the ordering,
for both unicast and multicast messages.
5.3.3. Replacing the thread pool and factories
The following thread pools and factories are in TP:
| Name | Description |
|---|---|
Thread pool |
This is the pool for handling incoming messages. It can be fetched using
|
Thread factory |
This is the thread factory ( |
Socket factory |
This is responsible for creation and deletion of sockets. It can be fetched using |
|
|
Note that the thread pool and (thread and socket) factories should be replaced after a channel has been created
and before it is connected (JChannel.connect()).
|
5.3.4. Sharing of thread pools between channels in the same JVM
The thread pool can be shared between instances running inside the same JVM. This can be done by creating an
implementation of Executor, a number of channels and then setting the same executor in all channels via
setThreadPool(Executor e).
The advantage here is that multiple channels running within the same JVM can pool (and therefore save) threads.
The disadvantage is that thread naming will not show to which channel instance an incoming thread belongs to.
5.3.5. Using a custom socket factory
JGroups creates all of its sockets through a SocketFactory, which is located in the transport (TP). The factory has methods to create sockets (Socket, ServerSocket, DatagramSocket and MulticastSocket), close sockets and list all open sockets. Every socket creation method has a service name, which could be for example "jgroups.fd_sock.srv_sock". The service name is used to look up a port (e.g. in a config file) and create the correct socket.
To provide one’s own socket factory, the following has to be done: the code below creates a SocketFactory implementation and sets it in the transport:
JChannel ch;
MySocketFactory factory; // e.g. extends DefaultSocketFactory
ch=new JChannel("config.xml");
ch.setSocketFactory(new MySocketFactory());
ch.connect("demo");5.4. Handling network partitions
Network partitions can be caused by switch, router or network interface crashes, among other things. If we have a cluster {A,B,C,D,E} spread across 2 subnets {A,B,C} and {D,E} and the switch to which D and E are connected crashes, then we end up with a network partition, with subclusters {A,B,C} and {D,E}.
A, B and C can ping each other, but not D or E, and vice versa. We now have 2 coordinators, A and D. Both subclusters operate independently, for example, if we maintain a shared state, subcluster {A,B,C} replicate changes to A, B and C.
This means, that if during the partition, some clients access {A,B,C}, and others {D,E}, then we end up with different states in both subclusters. When a partition heals, the merge protocol (e.g. MERGE3) will notify A and D that there were 2 subclusters and merge them back into {A,B,C,D,E}, with A being the new coordinator and D ceasing to be coordinator.
The question is what happens with the 2 diverged substates ?
There are 2 solutions to merging substates: first we can attempt to create a new state from the 2 substates, and secondly we can shut down all members of the non primary partition, such that they have to re-join and possibly reacquire the state from a member in the primary partition.
In both cases, the application has to handle a MergeView (subclass of View), as shown in the code below:
public void viewAccepted(View view) {
if(view instanceof MergeView) {
MergeView tmp=(MergeView)view;
List<View> subgroups=tmp.getSubgroups();
// merge state or determine primary partition
// run in a separate thread!
}
}It is essential that the merge view handling code run on a separate thread if it needs more than a few milliseconds, or else it would block the calling thread.
The MergeView contains a list of views, each view represents a subgroups and has the list of members which formed this group.
5.4.1. Merging substates
The application has to merge the substates from the various subgroups ({A,B,C} and {D,E}) back into one single state for {A,B,C,D,E}. This task has to be done by the application because JGroups knows nothing about the application state, other than it is a byte buffer.
If the in-memory state is backed by a database, then the solution is easy: simply discard the in-memory state and fetch it (eagerly or lazily) from the DB again. This of course assumes that the members of the 2 subgroups were able to write their changes to the DB. However, this is often not the case, as connectivity to the DB might have been severed by the network partition.
Another solution could involve tagging the state with time stamps. On merging, we could compare the time stamps for the substates and let the substate with the more recent time stamps win.
Yet another solution could increase a counter for a state each time the state has been modified. The state with the highest counter wins.
Again, the merging of state can only be done by the application. Whatever algorithm is picked to merge state, it has to be deterministic.
5.4.2. The primary partition approach
The primary partition approach is simple: on merging, one subgroup is designated as the primary partition and all others as non-primary partitions. The members in the primary partition don’t do anything, whereas the members in the non-primary partitions need to drop their state and re-initialize their state from fresh state obtained from a member of the primary partition.
The code to find the primary partition needs to be deterministic, so that all members pick the same primary partition. This could be for example the first view in the MergeView, or we could sort all members of the new MergeView and pick the subgroup which contained the new coordinator (the one from the consolidated MergeView). Another possible solution could be to pick the largest subgroup, and, if there is a tie, sort the tied views lexicographically (all Addresses have a compareTo() method) and pick the subgroup with the lowest ranked member.
Here’s code which picks as primary partition the first view in the MergeView, then re-acquires the state from the new coordinator of the combined view:
public static void main(String[] args) throws Exception {
final JChannel ch=new JChannel("/home/bela/udp.xml");
ch.setReceiver(new ReceiverAdapter() {
public void viewAccepted(View new_view) {
handleView(ch, new_view);
}
});
ch.connect("x");
private static void handleView(JChannel ch, View new_view) {
if(new_view instanceof MergeView) {
ViewHandler handler=new ViewHandler(ch, (MergeView)new_view);
// requires separate thread as we don't want to block JGroups
handler.start();
}
}
private static class ViewHandler extends Thread {
JChannel ch;
MergeView view;
private ViewHandler(JChannel ch, MergeView view) {
this.ch=ch;
this.view=view;
}
public void run() {
List<View> subgroups=view.getSubgroups();
View tmp_view=subgroups.firstElement(); // picks the first
Address local_addr=ch.getLocalAddress();
if(!tmp_view.getMembers().contains(local_addr)) {
System.out.println("Not member of the new primary partition ("
+ tmp_view + "), will re-acquire the state");
try {
ch.getState(null, 30000);
}
catch(Exception ex) {
}
}
else {
System.out.println("Not member of the new primary partition ("
+ tmp_view + "), will do nothing");
}
}
}The handleView() method is called from viewAccepted(), which is called whenever there is a new view. It spawns a new thread which gets the subgroups from the MergeView, and picks the first subgroup to be the primary partition. Then, if it was a member of the primary partition, it does nothing, and if not, it reaqcuires the state from the coordinator of the primary partition (A).
The downside to the primary partition approach is that work (= state changes) on the non-primary partition is discarded on merging. However, that’s only problematic if the data was purely in-memory data, and not backed by persistent storage. If the latter’s the case, use state merging discussed above.
It would be simpler to shut down the non-primary partition as soon as the network partition is detected, but that a non trivial problem, as we don’t know whether {D,E} simply crashed, or whether they’re still alive, but were partitioned away by the crash of a switch. This is called a split brain syndrome, and means that none of the members has enough information to determine whether it is in the primary or non-primary partition, by simply exchanging messages.
5.4.3. The Split Brain syndrome and primary partitions
In certain situations, we can avoid having multiple subgroups where every subgroup is able to make progress, and on merging having to discard state of the non-primary partitions.
If we have a fixed membership, e.g. the cluster always consists of 5 nodes, then we can run code on a view reception that determines the primary partition. This code
-
assumes that the primary partition has to have at least 3 nodes
-
any cluster which has less than 3 nodes doesn’t accept modfications. This could be done for shared state for example, by simply making the {D,E} partition read-only. Clients can access the {D,E} partition and read state, but not modify it.
-
As an alternative, clusters without at least 3 members could shut down, so in this case D and E would leave the cluster.
The algorithm is shown in pseudo code below:
On initialization:
- Mark the node as read-only
On view change V:
- If V has >= N members:
- If not read-write: get state from coord and switch to read-write
- Else: switch to read-only
Of course, the above mechanism requires that at least 3 nodes are up at any given time, so upgrades have to be done in a staggered way, taking only one node down at a time. In the worst case, however, this mechanism leaves the cluster read-only and notifies a system admin, who can fix the issue. This is still better than shutting the entire cluster down.
5.5. Flushing: making sure every node in the cluster received a message
To change this, we can turn on virtual synchrony (by adding FLUSH to the top of the stack), which guarantees that
-
A message M sent in V1 will be delivered in V1. So, in the example above, M1 would get delivered in view V1; by A, B and C, but not by D.
-
The set of messages seen by members in V1 is the same for all members before a new view V2 is installed. This is important, as it ensures that all members in a given view see the same messages. For example, in a group {A,B,C}, C sends 5 messages. A receives all 5 messages, but B doesn’t. Now C crashes before it can retransmit the messages to B. FLUSH will now ensure, that before installing V2={A,B} (excluding C), B gets C’s 5 messages. This is done through the flush protocol, which has all members reconcile their messages before a new view is installed. In this case, A will send C’s 5 messages to B.
Sometimes it is important to know that every node in the cluster received all messages up to a certain point,
even if there is no new view being installed. To do this (initiate a manual flush), an application programmer
can call JChannel.startFlush() to start a flush and JChannel.stopFlush() to terminate it.
JChannel.startFlush() flushes all pending messages out of the system. This stops all senders (calling
JChannel.down() during a flush will block until the flush has completed)[2].
When startFlush() returns, the caller knows that (a) no messages will get sent anymore until stopFlush() is
called and (b) all members have received all messages sent before startFlush() was called.
JChannel.stopFlush() terminates the flush protocol, no blocked senders can resume sending messages.
Note that the FLUSH protocol has to be present on top of the stack, or else the flush will fail.
5.6. Large clusters
This section is a collection of best practices and tips and tricks for running large clusters on JGroups.
By large clusters, we mean several hundred nodes in a cluster. These recommendations are captured in
udp-largecluster.xml which is shipped with JGroups.
|
|
This is work-in-progress, and udp-largecluster.xml is likely to see changes in the future.
|
5.7. STOMP support
STOMP is a JGroups protocol which implements the STOMP
protocol. Transactions and acks have not been implemented yet.
Adding the STOMP protocol to a configuration means that
-
Clients written in different languages can subscribe to destinations, send messages to destinations, and receive messages posted to (subscribed) destinations. This is similar to JMS topics.
-
Clients don’t need to join any cluster; this allows for light weight clients, and we can run many of them.
-
Clients can access a cluster from a remote location (e.g. across a WAN).
-
STOMP clients can send messages to cluster members, and vice versa.
The location of a STOMP protocol in a stack is shown in STOMP in a protocol stack.
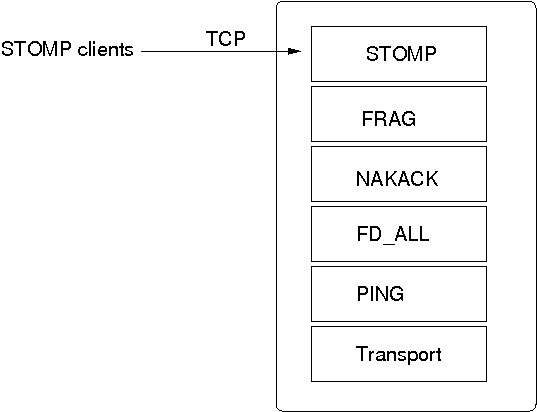
The STOMP protocol should be near the top of the stack.
A STOMP instance listens on a TCP socket for client connections. The port and bind address of the server socket can be defined via properties.
A client can send SUBSCRIBE commands for various destinations. When a SEND for a given destination is received, STOMP adds a header to the message and broadcasts it to all cluster nodes. Every node then in turn forwards the message to all of its connected clients which have subscribed to the same destination. When a destination is not given, STOMP simply forwards the message to all connected clients.
Traffic can be generated by clients and by servers. In the latter case, we could for example have code executing in the address space of a JGroups (server) node. In the former case, clients use the SEND command to send messages to a JGroups server and receive messages via the MESSAGE command. If there is code on the server which generates messages, it is important that both client and server code agree on a marshalling format, e.g. JSON, so that they understand each other’s messages.
Clients can be written in any language, as long as they understand the STOMP protocol. Note that the JGroups STOMP protocol implementation sends additional information (e.g. INFO) to clients; non-JGroups STOMP clients should simply ignore them.
JGroups comes with a STOMP client (org.jgroups.client.StompConnection) and a demo (StompDraw). Both need to be started with the address and port of a JGroups cluster node. Once they have been started, the JGroups STOMP protocol will notify clients of cluster changes, which is needed so client can failover to another JGroups server node when a node is shut down. E.g. when a client connects to C, after connection, it’ll get a list of endpoints (e.g. A,B,C,D). When C is terminated, or crashes, the client automatically reconnects to any of the remaining nodes, e.g. A, B, or D. When this happens, a client is also re-subscribed to the destinations it registered for.
The JGroups STOMP protocol can be used when we have clients, which are either not in the same network segment as the JGroups server nodes, or which don’t want to become full-blown JGroups server nodes. STOMP architecture shows a typical setup.
There are 4 nodes in a cluster. Say the cluster is in a LAN, and communication is via IP multicasting (UDP as transport). We now have clients which do not want to be part of the cluster themselves, e.g. because they’re in a different geographic location (and we don’t want to switch the main cluster to TCP), or because clients are frequently started and stopped, and therefore the cost of startup and joining wouldn’t be amortized over the lifetime of a client. Another reason could be that clients are written in a different language, or perhaps, we don’t want a large cluster, which could be the case if we for example have 10 JGroups server nodes and 1000 clients connected to them.
In the example, we see 9 clients connected to every JGroups cluster node. If a client connected to node A sends a message to destination /topics/chat, then the message is multicast from node A to all other nodes (B, C and D). Every node then forwards the message to those clients which have previously subscribed to /topics/chat.
When node A crashes (or leaves) the JGroups STOMP clients (org.jgroups.client.StompConnection) simply pick another server node and connect to it.
For more information about STOMP see the blog entry at http://belaban.blogspot.com/2010/10/stomp-for-jgroups.html.
5.8. Bridging between remote clusters
In 2.12, the RELAY protocol was added to JGroups (for the properties see RELAY). It allows for bridging of remote clusters. For example, if we have a cluster in New York (NYC) and another one in San Francisco (SFO), then RELAY allows us to bridge NYC and SFO, so that multicast messages sent in NYC will be forwarded to SFO and vice versa.
The NYC and SFO clusters could for example use IP multicasting (UDP as transport), and the bridge could use TCP as transport. The SFO and NYC clusters don’t even need to use the same cluster name.
Relaying between different clusters shows how the two clusters are bridged.
The cluster on the left side with nodes A (the coordinator), B and C is called "NYC" and use IP multicasting (UDP as transport). The cluster on the right side ("SFO") has nodes D (coordinator), E and F.
The bridge between the local clusters NYC and SFO is essentially another cluster with the coordinators (A and D) of the local clusters as members. The bridge typically uses TCP as transport, but any of the supported JGroups transports could be used (including UDP, if supported across a WAN, for instance).
Only a coordinator relays traffic between the local and remote cluster. When A crashes or leaves, then the next-in-line (B) takes over and starts relaying.
Relaying is done via the RELAY protocol added to the top of the stack. The bridge is configured with the bridge_props property, e.g. bridge_props="/home/bela/tcp.xml". This creates a JChannel inside RELAY.
Note that property "site" must be set in both subclusters. In the example above, we could set site="nyc" for the NYC subcluster and site="sfo" for the SFO subcluster.
The design is described in detail in JGroups/doc/design/RELAY.txt (part of the source distribution). In a nutshell, multicast messages received in a local cluster are wrapped and forwarded to the remote cluster by a relay (= the coordinator of a local cluster). When a remote cluster receives such a message, it is unwrapped and put onto the local cluster.
JGroups uses subclasses of UUID (PayloadUUID) to ship the site name with an address. When we see an address with site="nyc" on the SFO side, then RELAY will forward the message to the SFO subcluster, and vice versa. When C multicasts a message in the NYC cluster, A will forward it to D, which will re-broadcast the message on its local cluster, with the sender being D. This means that the sender of the local broadcast will appear as D (so all retransmit requests got to D), but the original sender C is preserved in the header. At the RELAY protocol, the sender will be replaced with the original sender ( nodeC) having site="nyc". When node F wants to reply to the sender of the multicast, the destination of the message will be C, which is intercepted by the RELAY protocol and forwarded to the current relay (D). D then picks the correct destination © and sends the message to the remote cluster, where A makes sure C (the original sender) receives it.
An important design goal of RELAY is to be able to have completely autonomous clusters, so NYC doesn’t for example have to block waiting for credits from SFO, or a node in the SFO cluster doesn’t have to ask a node in NYC for retransmission of a missing message.
5.8.1. Views
RELAY presents a global view to the application, e.g. a view received by nodes could be {D,E,F,A,B,C}. This view is the same on all nodes, and a global view is generated by taking the two local views, e.g. A|5 {A,B,C} and D|2 {D,E,F}, comparing the coordinators' addresses (the UUIDs for A and D) and concatenating the views into a list. So if D’s UUID is greater than A’s UUID, we first add D’s members into the global view ({D,E,F}), and then A’s members.
Therefore, we’ll always see all of A’s members, followed by all of D’s members, or the other way round.
To see which nodes are local and which ones remote, we can iterate through the addresses (PayloadUUID) and use the site (PayloadUUID.getPayload()) name to for example differentiate between "nyc" and "sfo".
5.8.2. Configuration
To setup a relay, we need essentially 3 XML configuration files: 2 to configure the local clusters and 1 for the bridge.
To configure the first local cluster, we can copy udp.xml from the JGroups distribution and add RELAY on top of it: <RELAY bridge_props="/home/bela/tcp.xml" />. Let’s say we call this config relay.xml.
The second local cluster can be configured by copying relay.xml to relay2.xml. Then change the mcast_addr and/or mcast_port, so we actually have 2 different cluster in case we run instances of both clusters in the same network. Of course, if the nodes of one cluster are run in a different network from the nodes of the other cluster, and they cannot talk to each other, then we can simply use the same configuration.
The site property needs to be configured in relay.xml and relay2.xml, and it has to be different. For example, relay.xml could use site="nyc" and relay2.xml could use site="sfo".
The bridge is configured by taking the stock tcp.xml and making sure both local clusters can see each other through TCP.
5.9. Relaying between multiple sites (RELAY2)
|
|
RELAY2 was added to JGroups in the 3.2 release. |
Similar to Bridging between remote clusters, RELAY2 provides clustering between sites. However, the differences to RELAY are:
-
Clustering can be done between multiple sites. Currently (3.2), sites have to be directly reachable. In 3.3, hierarchical setups of sites will be implemented.
-
Virtual (global) views are not provided anymore. If we have clusters SFO={A,B,C} and LON={X,Y,Z}, then both clusters are completed autonomous and don’t know about each other’s existence.
-
Not only unicasts, but also multicasts can be routed between sites (configurable).
To use RELAY2, it has to be placed at the top of the configuration, e.g.:
<relay.RELAY2 site="LON" config="/home/bela/relay2.xml"
relay_multicasts="true" />The above configuration has a site name which will be used to route messages between sites. To do that, addresses contain the site-ID, so we always know which site the address is from. E.g. an address A1:LON in the SFO site is not local, but will be routed to the remote site LON.
The relay_multicasts property determines whether or not multicast messages (with dest = null) are relayed to the other sites, or not. When we have a site LON, connected to sites SFO and NYC, if a multicast message is sent in site LON, and relay_multicasts is true, then all members of sites SFO and NYC will receive the message.
The config property points to an XML file which defines the setup of the sites, e.g.:
<RelayConfiguration xmlns="urn:jgroups:relay:4.2"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:jgroups:relay:4.2 http://jgroups.org/schema/relay-4.2.xsd">
<sites>
<site name="lon">
<bridges>
<bridge config="/home/bela/global.xml" name="global"/>
</bridges>
</site>
<site name="nyc">
<bridges>
<bridge config="/home/bela/global.xml" name="global"/>
</bridges>
</site>
<site name="sfo">
<bridges>
<bridge name="global" config="/home/bela/global.xml"/>
</bridges>
</site>
</sites>
</RelayConfiguration>This defines 3 sites LON, SFO and NYC. All the sites are connected to a global cluster (bus) "global" (defined by /home/bela/global.xml). All inter-site traffic will be sent via this global cluster (which has to be accessible by all of the sites). Intra-site traffic is sent via the cluster that’s defined by the configuration of which RELAY2 is the top protocol.
The above configuration is not mandatory, ie. instead of a global cluster, we could define separate clusters between LON and SFO and LON and NYC. However, in such a setup, due to lack of hierarchical routing, NYC and SFO wouldn’t be able to send each other messages; only LON would be able to send message to SFO and NYC.
5.9.1. Relaying of multicasts
If relay_multicasts is true then any multicast received by the site master of a site (ie. the coordinator of the local cluster, responsible for relaying of unicasts and multicasts) will relay the multicast to all connected sites. This means that - beyond setting relay_multicasts - nothing has to be done in order to relay multicasts across all sites.
A recipient of a multicast message which originated from a different site will see that the sender’s address is not a UUID, but a subclass (SiteUUID) which is the UUID plus the site suffix, e.g. A1:SFO. Since a SiteUUID is a subclass of a UUID, both types can be mixed and matched, placed into hashmaps or lists, and they implement compareTo() and equals() correctly.
When a reply is to be sent to the originator of the multicast message, Message.getSrc() provides the target address for the unicast response message. This is also a SiteUUID, but the sender of the response neither has to know nor take any special action to send the response, as JGroups takes care of routing the response back to the original sender.
5.9.2. Relaying of unicasts
As discussed above, relaying of unicasts is done transparently. However, if we don’t have a target address (e.g. as a result of reception of a multicast), there is a special address SiteMaster which identifies the site master; the coordinator of a local cluster responsible for relaying of messages.
Class SiteMaster is created with the name of a site, e.g. new SiteMaster("LON"). When a unicast with destination SiteMaster("LON") is sent, then we relay the message to the current site master of LON. If the site master changes, messages will get relayed to a different node, which took over the role of the site master from the old (perhaps crashed) site master.
Sometimes only certain members of a site should become site masters; e.g. the more powerful boxes (as routing needs some additional CPU power), or multi-homed hosts which are connected to the external network (over which the sites are connected with each other).
To do this, RELAY2 can generate special addresses which contain the knowledge about whether a member should be skipped when selecting a site master from a view, or not. If can_become_site_master is set to false in RELAY2, then the selection process will skip that member. However, if all members in a given view are marked with can_become_site_master=false, then the first member of the view will get picked.
When we have all members in a view marked with can_become_site_master=false, e.g. {B,C,D}, then B is the site master. If we now start a member A with can_become_site_master=true, then B will stop being the site master and A will become the new site master.
5.9.3. Invoking RPCs across sites
Invoking RPCs across sites is more or less transparent, except for the case when we cannot reach a member of a remote site. If we want to invoke method foo() in A1, A2 (local) and SiteMaster("SFO"), we could write the following code:
List<Address> dests=new ArrayList<Address>(view.getMembers());
dests.add(new SiteMaster("SFO"));
RspList<Object> rsps;
rsps=disp.callRemoteMethods(dests, call,
new RequestOptions(ResponseMode.GET_ALL, 5000).setAnycasting(true));
for(Rsp rsp: rsps.values()) {
if(rsp.wasUnreachable())
System.out.println("<< unreachable: " + rsp.getSender());
else
System.out.println("<< " + rsp.getValue() + " from " + rsp.getSender());
}First, we add the members (A1 and A2) of the current (local) view to the destination set. Then we add the
special address SiteMaster("SFO") which acts as a placeholder for the current coordinator of the SFO site.
Next, we invoke the call with dests as target set and block until responses from all A1, A2 and SiteMaster("SFO") have been received, or until 5 seconds have elapsed.
Next, we check the response list. And here comes the bit that’s new in 3.2: if a site is unreachable, a Rsp has an additional field "unreachable", which means that we could not reach the site master of SFO for example. Note that this is not necessarily an error, as a site maybe currently down, but the caller now has the option of checking on this new status field.
5.9.4. Configuration
Let’s configure an example which consists of 3 sites SFO, LON and NYC and 2 members in each site. First we define the configuration for the local cluster (site) SFO. To do this, we could for example copy udp.xml from the JGroups distro (and name it sfo.xml) and add RELAY2 to the top (as shown above). RELAY2’s config property points to relay2.xml as shown above as well. The relay2.xml file defines a global cluster with global.xml, which uses TCP and MPING for the global cluster (copy for example tcp.xml to create global.xml)
Now copy sfo.xml to lon.xml and nyc.xml. The RELAY2 configuration stays the same for lon.xml and nyc.xml, but the multicast address and/or multicast port has to be changed in order to create 3 separate local clusters. Therefore, modify both lon.xml and nyc.xml and change mcast_port and / or mcast_addr in UDP to use separate values, so the clusters don’t interfere with each other.
To test whether we have 3 different clusters, start the Draw application (shipped with JGroups):
java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./sfo.xml -name sfo1 java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./sfo.xml -name sfo2 java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./lon.xml -name lon1 java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./lon.xml -name lon2 java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./nyc.xml -name nyc1 java -Djgroups.bind_addr=127.0.0.1 org.jgroups.demos.Draw -props ./nyc.xml -name nyc2
We should now have 3 local clusters (= sites) of 2 instances each. When RELAY2.relay_multicasts is true, if you draw in one instance, we should see the drawing in all 6 instances. This means that relaying of multicasting between sites works. If this doesn’t work, run a few Draw instances on global.xml, to see if they find each other.
Note that the first member of each cluster always joins the global cluster (defined by global.xml) too. This is necessary to relay messages between sites.
To test unicasts between sites, you can use the org.jgroups.demos.RelayDemoRpc program: start it as follows:
java org.jgroups.demos.RelayDemoRpc -props ./sfo.xml -name sfo1
Start 2 instances in 3 sites and then use
mcast lon sfo nyc
to invoke RPCs on all local members and site masters SFO, NYC and LON. If one of the sites is down, you’ll get a message stating the site is unreachable.
5.10. Daisychaining
Daisychaining refers to a way of disseminating messages sent to the entire cluster.
The idea behind it is that it is inefficient to broadcast a message in clusters where IP multicasting is not available. For example, if we only have TCP available (as is the case in most clouds today), then we have to send a broadcast (or group) message N-1 times. If we want to broadcast M to a cluster of 10, we send the same message 9 times.
Example: if we have {A,B,C,D,E,F}, and A broadcasts M, then it sends it to B, then to C, then to D etc. If we have a 1 GB switch, and M is 1GB, then sending a broadcast to 9 members takes 9 seconds, even if we parallelize the sending of M. This is due to the fact that the link to the switch only sustains 1GB / sec. (Note that I’m conveniently ignoring the fact that the switch will start dropping packets if it is overloaded, causing TCP to retransmit, slowing things down)…
Let’s introduce the concept of a round. A round is the time it takes to send or receive a message. In the above example, a round takes 1 second if we send 1 GB messages. In the existing N-1 approach, it takes X * (N-1) rounds to send X messages to a cluster of N nodes. So to broadcast 10 messages a the cluster of 10, it takes 90 rounds.
The idea is that, instead of sending a message to N-1 members, we only send it to our neighbor, which forwards it to its neighbor, and so on. For example, in {A,B,C,D,E}, D would broadcast a message by forwarding it to E, E forwards it to A, A to B, B to C and C to D. We use a time-to-live field, which gets decremented on every forward, and a message gets discarded when the time-to-live is 0.
The advantage is that, instead of taxing the link between a member and the switch to send N-1 messages, we distribute the traffic more evenly across the links between the nodes and the switch. Let’s take a look at an example, where A broadcasts messages m1 and m2 in cluster {A,B,C,D}, --> means sending:
5.10.1. Traditional N-1 approach
-
Round 1: A(m1) --> B
-
Round 2: A(m1) --> C
-
Round 3: A(m1) --> D
-
Round 4: A(m2) --> B
-
Round 5: A(m2) --> C
-
Round 6: A(m2) --> D
It takes 6 rounds to broadcast m1 and m2 to the cluster.
5.10.2. Daisychaining approach
-
Round 1: A(m1) --> B
-
Round 2: A(m2) --> B || B(m1) --> C
-
Round 3: B(m2) --> C || C(m1) --> D
-
Round 4: C(m2) --> D
In round 1, A send m1 to B.
In round 2, A sends m2 to B, but B also forwards m1 (received in round 1) to C.
In round 3, A is done. B forwards m2 to C and C forwards m1 to D (in parallel, denoted by ``||`).
In round 4, C forwards m2 to D.
5.10.3. Switch usage
Let’s take a look at this in terms of switch usage: in the N-1 approach, A can only send 125MB/sec, no matter how many members there are in the cluster, so it is constrained by the link capacity to the switch. (Note that A can also receive 125MB/sec in parallel with today’s full duplex links).
So the link between A and the switch gets hot.
In the daisychaining approach, link usage is more even: if we look for example at round 2, A sending to B and B sending to C uses 2 different links, so there are no constraints regarding capacity of a link. The same goes for B sending to C and C sending to D.
In terms of rounds, the daisy chaining approach uses X + (N-2) rounds, so for a cluster size of 10 and broadcasting 10 messages, it requires only 18 rounds, compared to 90 for the N-1 approach!
5.10.4. Performance
To measure performance of DAISYCHAIN, a performance test (test.Perf) was run, with 4 nodes connected to a 1 GB switch; and every node sending 1 million 8K messages, for a total of 32GB received by every node. The config used was tcp.xml.
The N-1 approach yielded a throughput of 73 MB/node/sec, and the daisy chaining approach 107MB/node/sec!
5.10.5. Configuration
DAISYCHAIN can be placed directly on top of the transport, regardless of whether it is UDP or TCP, e.g.
<TCP .../>
<DAISYCHAIN .../>
<TCPPING .../>|
|
Daisychaining is experimental. While results show that performance for multicast messages (= messages to all cluster nodes) is excellent, it has never been tested extensively. |
5.11. Tagging messages with flags
A message can be tagged with a selection of flags, which alter the way certain protocols treat the message. This is done as follows:
Message msg=new Message().setFlag(Message.Flag.OOB, Message.Flag.NO_FC);Here we tag the message to be OOB (out of band) and to bypass flow control.
The advantage of tagging messages is that we don’t need to change the configuration, but instead can override it on a per-message basis.
The available flags are:
- Message.OOB
-
This tags a message as out-of-band, which will get it processed by the out-of-band thread pool at the receiver’s side. Note that an OOB message does not provide any ordering guarantees, although OOB messages are reliable (no loss) and are delivered only once. See Out-of-band messages for details.
- Message.DONT_BUNDLE
-
This flag causes the transport not to bundle the message, but to send it immediately. See Message bundling and performance for a discussion of the DONT_BUNDLE flag with respect to performance of blocking RPCs.
- Message.NO_FC
-
This flag bypasses any flow control protocol (see Flow control) for a discussion of flow control protocols.
- Message.NO_RELIABILITY
-
When sending unicast or multicast messages, some protocols (
UNICAST3,NAKACK2) add sequence numbers to the messages in order to (1) deliver them reliably and (2) in order.
If we don’t want reliability, we can tag the message with flagNO_RELIABILITY. This means that a message tagged with this flag may not be received, may be received more than once, or may be received out of order.
A message tagged withNO_RELIABILITYwill simply bypass reliable protocols such asUNICAST3andNAKACK2.
For example, if we send multicast message M1, M2 (NO_RELIABILITY), M3 and M4, and the starting sequence number is #25, then M1 will have seqno #25, M3 will have #26 and M4 will have #27. We can see that we don’t allocate a seqno for M2 here. - Message.NO_TOTAL_ORDER
-
If we use a total order configuration with SEQUENCER (SEQUENCER), then we can bypass SEQUENCER (if we don’t need total order for a given message) by tagging the message with flag
NO_TOTAL_ORDER. - Message.NO_RELAY
-
If we use RELAY (see Bridging between remote clusters) and don’t want a message to be relayed to the other site(s), then we can tag the message with NO_RELAY.
- Message.RSVP
-
When this flag is set, a message send will block until the receiver (unicast) or receivers (multicast) have acked reception of the message, or until a timeout occurs. See Synchronous messages for details.
- Message.RSVP_NB
-
This is the same as RSVP, but doesn’t block the sender of a message (invoker of an RPC). The call therefore returns immediately, but RSVP will resend the message until it has received all acks, or the timeout kicked in.
- Message.DONT_LOOPBACK
-
If this flag is set and the message is a multicast message (dest == null), then the transport by default (1) multicasts the message, (2) loops it back up the stack (on a separate thread) and (3) discards the multicast when received.
When DONT_LOOPBACK is set, the message will be multicast, but it will not be looped back up the stack. This is useful for example when the sender doesn’t want to receive its own multicast. Contrary to JChannel.setDiscardOwnMessages(), this flag can be set per message and the processing is done at the transport level rather than the JChannel level.
An example is the Discovery protocol: when sending a discovery request, the sender is only interested in responses from other members and therefore doesn’t need to receive its own discovery multicast request.
Note that this is a transient flag, so Message.setTransientFlag() has to be used instead of Message.setFlag()
|
|
Note that DONT_LOOPBACK does not make any sense for unicast messages,
as the sender of a message sent to itself will never receive it.
|
5.12. Performance tests
There are a number of performance tests shipped with JGroups. The section below discusses MPerf and UPerf.
5.12.1. MPerf
MPerf is a test which measures multicast performance. This doesn’t mean IP multicast performance, but point-to-multipoint performance. Point-to-multipoint means that we measure performance of one-to-many messages; in other words, messages sent to all cluster members.
MPerf is dynamic; it doesn’t need a setup file to define the number of senders, number of messages to be sent and message size.
Instead, all the configuration needed by an instance of MPerf is an XML stack configuration, and configuration changes done in one member are automatically broadcast to all other members.
MPerf can be started as follows:
java -cp $CLASSPATH org.jgroups.tests.perf.MPerf -props ./fast.xml
This assumes that we’re using IPv4 addresses (otherwise IPv6 addresses are used) and the JGroups JAR on the classpath.
A screen shot of MPerf looks like this (could be different, depending on the JGroups version):
[belasmac] /Users/bela$ mperf.sh -props ~/fast.xml -name A ----------------------- MPerf ----------------------- Date: Mon Sep 05 14:26:55 CEST 2016 Run by: bela JGroups version: 4.0.0-SNAPSHOT ------------------------------------------------------------------- GMS: address=A, cluster=mperf, physical address=127.0.0.1:52344 ------------------------------------------------------------------- ** [A|0] (1) [A] [1] Send [2] View [3] Set num msgs (1000000) [4] Set msg size (1KB) [5] Set threads (10) [6] New config (/Users/bela/fast.xml) [7] Number of senders (all) [o] Toggle OOB (false) [x] Exit this [X] Exit all [c] Cancel sending
We’re starting MPerf with -props ~/fast.xml and -name A. The -props option
points to a JGroups configuration file, and -name gives the member the name "A".
A few instances of MPerf can now be started and each instance should join the same cluster.
MPerf can then be run by pressing [1]. In this case, every member in the cluster (in the example, we have members A and B) will send 1 million 1K messages. Once all messages have been received, MPerf will write a summary of the performance results to stdout:
1 [1] Send [2] View [3] Set num msgs (1000000) [4] Set msg size (1KB) [5] Set threads (10) [6] New config (/Users/bela/fast.xml) [7] Number of senders (all) [o] Toggle OOB (false) [x] Exit this [X] Exit all [c] Cancel sending -- sending 1000000 msgs ++ sent 100000 -- received 200000 msgs (217 ms, 921658.99 msgs/sec, 921.66MB/sec) ++ sent 200000 ++ sent 300000 -- received 400000 msgs (225 ms, 888888.89 msgs/sec, 888.89MB/sec) ++ sent 400000 ++ sent 500000 -- received 600000 msgs (228 ms, 877192.98 msgs/sec, 877.19MB/sec) ++ sent 600000 ++ sent 700000 -- received 800000 msgs (277 ms, 722021.66 msgs/sec, 722.02MB/sec) ++ sent 800000 ++ sent 900000 -- received 1000000 msgs (412 ms, 485436.89 msgs/sec, 485.44MB/sec) ++ sent 1000000 -- received 1200000 msgs (305 ms, 655737.7 msgs/sec, 655.74MB/sec) -- received 1400000 msgs (294 ms, 680272.11 msgs/sec, 680.27MB/sec) -- received 1600000 msgs (228 ms, 877192.98 msgs/sec, 877.19MB/sec) -- received 1800000 msgs (223 ms, 896860.99 msgs/sec, 896.86MB/sec) -- received 2000000 msgs (237 ms, 843881.86 msgs/sec, 843.88MB/sec) Results: A: 2000000 msgs, 2GB received, time=2646ms, msgs/sec=755857.9, throughput=755.86MB B: 2000000 msgs, 2GB received, time=2642ms, msgs/sec=757002.27, throughput=757MB =============================================================================== Average/node: 2000000 msgs, 2GB received, time=2644ms, msgs/sec=756429.65, throughput=756.43MB Average/cluster: 4000000 msgs, 4GB received, time=2644ms, msgs/sec=1512859.3, throughput=1.51GB ================================================================================
In the sample run above, we see member A’s screen. A sends 1 million messages and waits for its 1 million and the 1 million messages from B to be received before it dumps some stats to stdout. The stats include the number of messages and bytes received, the time, the message rate and throughput averaged over the 2 members. It also shows the aggregated performance over the entire cluster.
In the sample run above (both processes on the same box), we got an average 756 MB of data per member per second, and an aggregated 1.5 GB per second for the entire cluster (A and B in this case).
Parameters such as the number of messages to be sent, the message size and the number of threads to be used to send the messages can be configured by pressing the corresponding numbers. After pressing return, the change will be broadcast to all cluster members, so that we don’t have to go to each member and apply the same change. Also, new members started, will fetch the current configuration and apply it.
For example, if we set the message size in A to 2000 bytes, then the change would be sent to B, which would apply it as well. If we started a third member C, it would also have a configuration with a message size of 2000.
Another feature is the ability to restart all cluster members with a new configuration. For example, if
we modified ./fast.xml, we could select [6] to make all cluster members disconnect and
close their existing channels and start a new channel based on the modified fast.xml configuration.
The new configuration file doesn’t even have to be accessible on all cluster members; only on the member which makes the change. The file contents will be read by that member, converted into a byte buffer and shipped to all cluster members, where the new channel will then be created with the byte buffer (converted into an input stream) as config.
Being able to dynamically change the test parameters and the JGroups configuration makes MPerf suited to be run in larger clusters; unless a new JGroups version is installed, MPerf will never have to be restarted manually.
5.12.2. UPerf
UPerf is used to measure point-to-point (= unicast) communication between members. Start a few members like this:
java -cp $CLASSPATH org.jgroups.tests.perf.UPerf -props ./fast.xml
They will form a cluster. When [1] is pressed, every node will invoke 20000 synchronous RPCs on other members, each
time randomly selecting a member from the cluster. This will be done by 25 threads, but both number of RPCs and sender
threads can be changed dynamically across the entire cluster at runtime.
With an 80% chance, a request will mimic a GET which is a small request returning a (by default) 1K response. With a 20%
chance, the request is a PUT which is a 1K request and a small response. The read-write ration can be changed via [r].
GETs and PUTs mimic a distributed cache where GETs query information from the cache and PUT update information.
When done, every member sends its results back to the node on which the test was started, which then tallies the results, computes averages etc and prints the result of this round to stdout.
Here’s a sample run on member A:
[1] Invoke RPCs [6] Sender threads (25) [7] Num msgs (20000) [8] Msg size (1KB) [s] Sync (true) [o] OOB (true) [b] Msg bundling (true) [a] Anycast count (2) [r] Read percentage (0.80) [l] local gets (false) [d] print details (false) [i] print invokers (false) [v] View [x] Exit [X] Exit all 1 invoking 20000 RPCs of 1KB, sync=true, oob=true, msg_bundling=true ......... done (in 877 ms) ======================= Results: =========================== D: 23121.39 reqs/sec (15813 gets, 4187 puts, get RTT 971.37 us, put RTT 1495.74 us) A: 22805.02 reqs/sec (15826 gets, 4174 puts, get RTT 992.44 us, put RTT 1541.44 us) B: 24449.88 reqs/sec (15807 gets, 4193 puts, get RTT 873.63 us, put RTT 1551.84 us) C: 22371.36 reqs/sec (15826 gets, 4174 puts, get RTT 937.02 us, put RTT 1755.55 us) Throughput: 23161.55 reqs/sec/node (23.16MB/sec) Roundtrip: gets avg = 932.40 us, puts avg = 1646.17 us
This run was on a cluster consisting of {A,B,C,D} and the test was initiated on member A. When everyone is done, the results for A, B, C and D are printed individually, then averages for throughout and round-trip times are computed and also printed to stdout.
In this round, every node managed to invoke roughly 23'000 sync RPCs per second on randomly selected other members. The average GET time was slightly under 1 ms and PUT was roughly 1.6 ms.
5.13. Ergonomics
Ergonomics is similar to the dynamic setting of optimal values for the JVM, e.g. garbage collection, memory sizes etc. In JGroups, ergonomics means that we try to dynamically determine and set optimal values for protocol properties. Examples are thread pool size, flow control credits, heartbeat frequency and so on.
There is an ergonomics property which can be enabled or disabled for every protocol.
The default is true. To disable it, set it to false, e.g.:
<UDP... />
<PING ergonomics="false"/>Here we leave ergonomics enabled for UDP (the default is true), but disable it for PING.
Ergonomics is work-in-progress, and will be implemented over multiple releases.
5.14. Supervising a running stack
SUPERVISOR (SUPERVISOR) provides a rule based fault detection and correction protocol. It allows for rules to be installed, which are periodically invoked. When invoked, a condition can be checked and corrective action can be taken to fix the problem. Essentially, SUPERVISOR acts like a human administrator, except that condition checking and action triggering is done automatically.
An example of a rule is org.jgroups.protocols.rules.CheckFDMonitor: invoked periodically, it checks if the monitor task in FD is running when the membership is 2 or more and - if not - restarts it. The sections below show how to write the rule and how to invoke it.
All rules to be installed in SUPERVISOR are listed in an XML file, e.g. rules.xml:
<rules xmlns="urn:jgroups:rules:4.2">
<rule name="rule1" class="org.jgroups.protocols.rules.CheckFDMonitorRule"
interval="1000"/>
</rules>There is only one rule "rule1" present, which is run every second. The name of the class implementing the rule is "org.jgroups.protocols.rules.CheckFDMonitorRule", and its implementation is:
public class CheckFDMonitor extends Rule {
protected FD fd;
public String name() {return "sample";}
public String description() {
return "Starts FD.Monitor if membership > 1 and monitor isn't running";
}
public void init() {
super.init();
fd=(FD)sv.getProtocolStack().findProtocol(FD.class);
if(fd == null) {
log.info("FD was not found, uninstalling myself (sample)");
sv.uninstallRule("sample");
}
}
public boolean eval() {
return sv.getView() != null && sv.getView().size() > 1
&& !fd.isMonitorRunning();
}
public String condition() {
View view=sv.getView();
return "Membership is " + (view != null? view.size() : "n/a") +
", FD.Monitor running=" + fd.isMonitorRunning();
}
public void trigger() throws Throwable {
System.out.println(sv.getLocalAddress() + ": starting failure detection");
fd.startFailureDetection();
}
}CheckFDMonitor extends abstract class Rule which sets a reference to SUPERVISOR and the log when the rule has been installed.
Method name() needs to return a unique name by which the rule can be uninstalled later if necessary.
Description() should provide a meaningful description (used by JMX).
In init(), a reference to FD is set by getting the protocol stack from the SUPERVISOR (sv). If not found, e.g. because there is no FD protocol present in a given stack, the rule uninstalls itself.
Method eval() is called every second. It checks that the monitor task in FD is running (when the membership is 2 or more) and, if not, returns true. In that case, method trigger() will get called by the code in the Rule superclass and it simply restarts the stopped monitor task.
Note that rules can be installed and uninstalled dynamically at runtime, e.g. via probe.sh:
probe.sh op=SUPERVISOR.installRule["myrule", 1000,"org.jgroups.protocols.rules.CheckFDMonitor"]
probe.sh op=SUPERVISOR.uninstallRule["myrule"]
probe.sh op=SUPERVISOR.dumpRules
5.15. Probe
Probe is the Swiss Army Knife of JGroups; it allows to fetch information about the members running in a cluster, get and set properties of the various protocols, and invoke methods in all cluster members.
Probe can even insert protocols into running cluster members, or remove/replace existing protocols. Note that this doesn’t make sense though with stateful protocols such as NAKACK. But this feature is helpful, it could be used for example to insert a diagnostics or stats protocol into a running system. When done, the protocol can be removed again.
Probe is a script (probe.sh in the bin directory of the source
distribution) that can be invoked on any of the hosts in same network in which a cluster is running. The probe.sh script
essentially calls org.jgroups.tests.Probe which is part of the JGroups JAR.
Otherwise, probe can be run as follows:
java -cp jgroups.jar org.jgroups.tests.Probe
|
|
Probe by default uses IP multicasting to send probe requests to all cluster nodes. However, if IP multicasting
is not available or disabled in a network, probe can also be given the address of a single member
via the -addr option. That member then returns the addresses of the other cluster members, and probe
sends the request to all members individually.
|
The way probe works is that every stack has an additional multicast socket that by default listens on 224.0.75.75:7500 for diagnostics requests from probe. The configuration is located in the transport protocol (e.g. UDP), and consists of the following properties:
| Name | Description |
|---|---|
enable_diagnostics |
Whether or not to enable diagnostics (default: true). When enabled, this will create a MulticastSocket and we have one additional thread listening for probe requests. When disabled, we’ll have neither the thread nor the socket created. |
diag_enable_udp |
Use a multicast socket to listen for probe requests |
diag_enable_tcp |
Use a TCP socket to listen for probe requests (ignored if enable_diagnostics is false) |
diagnostics_addr |
The multicast address which the MulticastSocket should join. The default is
|
diagnostics_bind_addr |
Bind address for diagnostic probing. Used when diag_enable_tcp is true") |
diagnostics_port |
The port on which the MulticastSocket should listen. The default is |
Probe is extensible; by implementing a ProbeHandler and registering it with the transport (TP.registerProbeHandler()), any protocol, or even applications can register functionality to be invoked via probe. Refer to the javadoc for details.
To get information about the cluster members running in the local network, we can use the following probe command:
[belasmac] /Users/bela$ probe.sh -- sending probe on /224.0.75.75:7500 #1 (100 bytes): local_addr=B physical_addr=127.0.0.1:52060 view=[A|1] (2) [A, B] cluster=draw version=4.0.0-SNAPSHOT #2 (100 bytes): local_addr=A physical_addr=127.0.0.1:60570 view=[A|1] (2) [A, B] cluster=draw version=4.0.0-SNAPSHOT 2 responses (2 matches, 0 non matches) [belasmac] /Users/bela$
This gets us 2 responses, from A and B. "A" and "B" are the logical names, but we also see the UUIDs.
They’re both in the same cluster ("draw") and both have the same view
([A|1] [A, B]). The physical address and the version of both members is also shown.
Note that probe.sh -help lists the command line options.
To fetch all of the JMX information from all protocols, we can invoke probe jmx.
However, this dumps all of the JMX attributes from all protocols of all cluster members, so make sure to pipe the output into a file and awk and sed it for legibility!
However, we can also JMX information from a specific protocol, e.g. FRAG2 (slightly edited>:
[linux]/home/bela$ probe.sh jmx=FRAG2
-- send probe on /224.0.75.75:7500
#1 (318 bytes):
local_addr=B [88588976-5416-b054-ede9-0bf8d4b56c02]
cluster=DrawGroupDemo
physical_addr=192.168.1.5:35841
jmx=FRAG2={id=5, level=off, num_received_msgs=131, frag_size=60000,
num_sent_msgs=54, stats=true, num_sent_frags=0,
name=FRAG2, ergonomics=true, num_received_frags=0}
view=[A|1] [A, B]
version=3.0.0.Beta1
#2 (318 bytes):
local_addr=A [1a1f543c-2332-843b-b523-8d7653874de7]
cluster=DrawGroupDemo
physical_addr=192.168.1.5:43283
jmx=FRAG2={id=5, level=off, num_received_msgs=131, frag_size=60000,
num_sent_msgs=77, stats=true, num_sent_frags=0,
name=FRAG2, ergonomics=true, num_received_frags=0}
view=[A|1] [A, B]
version=3.0.0.Beta1
2 responses (2 matches, 0 non matches)
[linux]/home/bela$
We can also get information about specific properties in a given protocol:
[belasmac] /Users/bela$ probe.sh jmx=NAKACK2.xmit
-- sending probe on /224.0.75.75:7500
#1 (597 bytes):
local_addr=A [ip=127.0.0.1:63259, version=4.0.0-SNAPSHOT, cluster=draw, 2 mbr(s)]
NAKACK2={xmit_from_random_member=false, xmit_interval=500, xmit_reqs_received=0, xmit_reqs_sent=0, xmit_rsps_received=0, xmit_rsps_sent=0, xmit_table_capacity=204800, xmit_table_max_compaction_time=30000, xmit_table_missing_messages=0, xmit_table_msgs_per_row=2000, xmit_table_num_compactions=0, xmit_table_num_current_rows=100, xmit_table_num_moves=0, xmit_table_num_purges=1, xmit_table_num_resizes=0, xmit_table_num_rows=100, xmit_table_resize_factor=1.2, xmit_table_undelivered_msgs=0, xmit_task_running=true}
#2 (597 bytes):
local_addr=B [ip=127.0.0.1:62737, version=4.0.0-SNAPSHOT, cluster=draw, 2 mbr(s)]
NAKACK2={xmit_from_random_member=false, xmit_interval=500, xmit_reqs_received=0, xmit_reqs_sent=0, xmit_rsps_received=0, xmit_rsps_sent=0, xmit_table_capacity=204800, xmit_table_max_compaction_time=30000, xmit_table_missing_messages=0, xmit_table_msgs_per_row=2000, xmit_table_num_compactions=0, xmit_table_num_current_rows=100, xmit_table_num_moves=0, xmit_table_num_purges=1, xmit_table_num_resizes=0, xmit_table_num_rows=100, xmit_table_resize_factor=1.2, xmit_table_undelivered_msgs=0, xmit_task_running=true}
2 responses (2 matches, 0 non matches)
[belasmac] /Users/bela$
This returns all JMX attributes that start with "xmit" in all NAKACK2 protocols of
all cluster members. We can also pass a list of attributes:
[belasmac] /Users/bela$ probe.sh jmx=NAKACK2.xmit,num
-- sending probe on /224.0.75.75:7500
#1 (646 bytes):
local_addr=A [ip=127.0.0.1:63259, version=4.0.0-SNAPSHOT, cluster=draw, 2 mbr(s)]
NAKACK2={num_messages_received=115, num_messages_sent=26, xmit_from_random_member=false, xmit_interval=500, xmit_reqs_received=0, xmit_reqs_sent=0, xmit_rsps_received=0, xmit_rsps_sent=0, xmit_table_capacity=204800, xmit_table_max_compaction_time=30000, xmit_table_missing_messages=0, xmit_table_msgs_per_row=2000, xmit_table_num_compactions=0, xmit_table_num_current_rows=100, xmit_table_num_moves=0, xmit_table_num_purges=1, xmit_table_num_resizes=0, xmit_table_num_rows=100, xmit_table_resize_factor=1.2, xmit_table_undelivered_msgs=0, xmit_task_running=true}
#2 (646 bytes):
local_addr=B [ip=127.0.0.1:62737, version=4.0.0-SNAPSHOT, cluster=draw, 2 mbr(s)]
NAKACK2={num_messages_received=115, num_messages_sent=89, xmit_from_random_member=false, xmit_interval=500, xmit_reqs_received=0, xmit_reqs_sent=0, xmit_rsps_received=0, xmit_rsps_sent=0, xmit_table_capacity=204800, xmit_table_max_compaction_time=30000, xmit_table_missing_messages=0, xmit_table_msgs_per_row=2000, xmit_table_num_compactions=0, xmit_table_num_current_rows=100, xmit_table_num_moves=0, xmit_table_num_purges=1, xmit_table_num_resizes=0, xmit_table_num_rows=100, xmit_table_resize_factor=1.2, xmit_table_undelivered_msgs=0, xmit_task_running=true}
2 responses (2 matches, 0 non matches)
[belasmac] /Users/bela$
This returns all attributes of NAKACK2 that start with "xmit" or "num".
To invoke an operation, e.g. to set the logging level in all UDP protocols from "warn" to "trace", we
can use probe.sh op=UPD.setLevel["trace"]. This raises the logging level in all
UDP protocols of all cluster members, which is useful to diagnose a running system.
Operation invocation uses reflection, so any method defined in any protocol can be invoked. This is a powerful tool to get diagnostics information from a running cluster.
For further information, refer to the command line options of probe (probe.sh -h).
5.15.1. Looking at details of RPCs with probe
Probe can also be used to inspect for every node P:
-
the number of unicast RPCs invoked (sync or async)
-
the number of multicast RPCs invoked (sync or async)
-
the number of anycast RPCs invoked (sync or async)
For sync RPCs, it is also possible to get the min/max/avg times for RPCs to a given destination.
Since taking the times for all sync RPCs takes time (2x System.nanoTime() for each RPC), this is disabled by default
and has to be enabled (assuming we have 4 nodes running):
probe.sh rpcs-enable-details
From now on, timings for sync RPCs will be taken (async RPCs are not timed and therefore
not affected by the timing costs). To disable this, probe rpcs-disable-details can be called.
To get RPC stats, rpcs and rpcs-details can be used:
[belasmac] /Users/bela/JGroups$ probe.sh rpcs rpcs-details -- sending probe on /224.0.75.75:7500 #1 (481 bytes): local_addr=C [ip=127.0.0.1:55535, version=3.6.8-SNAPSHOT, cluster=uperf, 4 mbr(s)] uperf: sync multicast RPCs=0 uperf: async unicast RPCs=0 uperf: async multicast RPCs=0 uperf: sync anycast RPCs=67480 uperf: async anycast RPCs=0 uperf: sync unicast RPCs=189064 rpcs-details= D: async: 0, sync: 130434, min/max/avg (ms): 0.13/924.88/2.613 A: async: 0, sync: 130243, min/max/avg (ms): 0.11/926.35/2.541 B: async: 0, sync: 63346, min/max/avg (ms): 0.14/73.94/2.221 #2 (547 bytes): local_addr=A [ip=127.0.0.1:65387, version=3.6.8-SNAPSHOT, cluster=uperf, 4 mbr(s)] uperf: sync multicast RPCs=5 uperf: async unicast RPCs=0 uperf: async multicast RPCs=0 uperf: sync anycast RPCs=67528 uperf: async anycast RPCs=0 uperf: sync unicast RPCs=189200 rpcs-details= <all>: async: 0, sync: 5, min/max/avg (ms): 2.11/9255.10/4917.072 C: async: 0, sync: 130387, min/max/avg (ms): 0.13/929.71/2.467 D: async: 0, sync: 63340, min/max/avg (ms): 0.13/63.74/2.469 B: async: 0, sync: 130529, min/max/avg (ms): 0.13/929.71/2.328 #3 (481 bytes): local_addr=B [ip=127.0.0.1:51000, version=3.6.8-SNAPSHOT, cluster=uperf, 4 mbr(s)] uperf: sync multicast RPCs=0 uperf: async unicast RPCs=0 uperf: async multicast RPCs=0 uperf: sync anycast RPCs=67255 uperf: async anycast RPCs=0 uperf: sync unicast RPCs=189494 rpcs-details= C: async: 0, sync: 130616, min/max/avg (ms): 0.13/863.93/2.494 A: async: 0, sync: 63210, min/max/avg (ms): 0.14/54.35/2.066 D: async: 0, sync: 130177, min/max/avg (ms): 0.13/863.93/2.569 #4 (482 bytes): local_addr=D [ip=127.0.0.1:54944, version=3.6.8-SNAPSHOT, cluster=uperf, 4 mbr(s)] uperf: sync multicast RPCs=0 uperf: async unicast RPCs=0 uperf: async multicast RPCs=0 uperf: sync anycast RPCs=67293 uperf: async anycast RPCs=0 uperf: sync unicast RPCs=189353 rpcs-details= C: async: 0, sync: 63172, min/max/avg (ms): 0.13/860.72/2.399 A: async: 0, sync: 130342, min/max/avg (ms): 0.13/862.22/2.338 B: async: 0, sync: 130424, min/max/avg (ms): 0.13/866.39/2.350
The example output shows stats for members C, A, B and D. When looking at the output of member A, we can see that A
-
invoked 5 sync multicast RPCs
-
invoked 67528 sync anycasts (RPCs to a subset of the cluster, sent as a number of unicasts)
-
invoked 189200 sync unicast RPCs
-
sent 5 sync multicast RPCs which took an average of 4.9 seconds and a max of 9 seconds. The reason is that these were multicast RPCs in UPerf which started the test on each node and waited until it got results from all nodes. So these times are essentially the times it took the individual tests to run
-
invoked 63340 sync unicast RPCs on D, which took a min of 0.13 ms, a max of 63.74 ms and an average of 2.469 ms per RPC.
To reset the numbers, probe.sh rpcs-reset can be called.
5.15.2. Using probe with TCP
Probe uses IP multicasting by default. To enable TCP, diag_enable_tcp has to be set to true in the transport
(and optionally diag_enable_udp to false).
Probe can then be started by pointing it to the address of one member,
using the -addr argument, e.g.: probe.sh -addr 192.168.1.105 -port 7500 (note that port 7500 can be omitted, as
it is the default). In this mode, probe will ask the member running at 192.168.1.105:7500 for a list of all other
members, and then send the request to all of the returned members.
5.16. Analyzing wire-format packets
When using a packet analyzer such as Wireshark, tshark or tcpdump, the output is either a PCAP file (e.g. submitted by customers for post-mortem analysis) or a live stream of raw network packets.
Each packet has a number of headers before the data part which contains the JGroups message (or message batch). E.g. a UDP packet has an ethernet-, IP- and datagram header; a TCP message contains ethernet and IP headers plus the TCP information.
To see the JGroups messages, the ParseMessages program parses the data section of a UDP datagram packet or a
TCP or TCP_NIO2 stream and prints the JGroups messages plus its headers. It can be passed a file, or it can read from
stdin and thus be piped to a packet analyzer and print JGroups data in real-time.
5.16.1. tshark
tshark is the command-line version of wireshark. To capture UDP packets for the configuration below, which has nodes binding to the loopback (127.0.0.1) device and ports starting from 7800, the following command can be used:
<config>
<UDP
bind_addr="127.0.0.1" bind_port="7800"
mcast_addr="228.2.2.2"
mcast_port="${jgroups.udp.mcast_port:45588}">
...
</config>tshark -l -i en0 -i lo0 -T fields -e data udp and portrange 7800-7801 > jgroups-udp.data
This captures the data portion only (-T fields -e data) on the loopback and en0 devices and only captures packets
sent to or being sent from ports 7800 and 7801.
To print the packets offline, java org.jgroups.tests.ParseMessages -file jgroups-udp.data can be used. This would look
like this (edited):
[belasmac] /Users/bela$ jt ParseMessages -file bela.dump6
1: [B to 192.168.1.105:7800, 33 bytes, flags=OOB|DONT_BUNDLE|INTERNAL], hdrs: TCPPING: [GET_MBRS_REQ cluster=draw initial_discovery=true], TP: [cluster=draw]
2: [A to B, 33 bytes, flags=OOB|DONT_BUNDLE|INTERNAL], hdrs: TCPPING: [GET_MBRS_RSP cluster=null initial_discovery=false], TP: [cluster=draw]
3: [B to A, 0 bytes, flags=OOB|INTERNAL], hdrs: GMS: GmsHeader[JOIN_REQ]: mbr=B, UNICAST3: DATA, seqno=1, first, TP: [cluster=draw]
4: [A to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_SOCK: I_HAVE_SOCK, mbr=A, sock_addr=192.168.1.105:9000, TP: [cluster=draw]
5: batch to B from A (1 messages):
1: [33 bytes, flags=OOB|DONT_BUNDLE|INTERNAL], hdrs: TCPPING: [GET_MBRS_RSP cluster=null initial_discovery=false]
6: batch to B from A (1 messages):
1: [0 bytes, flags=INTERNAL], hdrs: FD_SOCK: WHO_HAS_SOCK, mbr=B
7: [A to <all>, 57 bytes], hdrs: GMS: GmsHeader[VIEW], NAKACK2: [MSG, seqno=1], TP: [cluster=draw]
8: [A to B, 61 bytes, flags=INTERNAL], hdrs: GMS: GmsHeader[JOIN_RSP], UNICAST3: DATA, seqno=1, first, TP: [cluster=draw]
9: [B to A, 0 bytes, flags=INTERNAL], hdrs: FD_SOCK: I_HAVE_SOCK, mbr=B, sock_addr=192.168.1.105:9001, TP: [cluster=draw]
10: [B to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_SOCK: I_HAVE_SOCK, mbr=B, sock_addr=192.168.1.105:9001, TP: [cluster=draw]
11: [B to A, 0 bytes, flags=INTERNAL], hdrs: FD_SOCK: GET_CACHE, TP: [cluster=draw]
12: [A to B, 54 bytes, flags=INTERNAL], hdrs: FD_SOCK: GET_CACHE_RSP, TP: [cluster=draw]
13: [B to A, 0 bytes, flags=OOB|INTERNAL], hdrs: GMS: GmsHeader[VIEW_ACK], UNICAST3: DATA, seqno=2, TP: [cluster=draw]
14: [A to B, 0 bytes, flags=INTERNAL], hdrs: UNICAST3: ACK, seqno=2, ts=1, TP: [cluster=draw]
15: [B to A, 0 bytes, flags=INTERNAL], hdrs: UNICAST3: ACK, seqno=1, ts=1, TP: [cluster=draw]
16: [A to <all>, 0 bytes, flags=OOB|INTERNAL], hdrs: NAKACK2: [HIGHEST_SEQNO, seqno=1], TP: [cluster=draw]
17: [A to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw]
18: [B to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw]
19: [B to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=1], TP: [cluster=draw]
...
45: [B to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=27], TP: [cluster=draw]
46: [A to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=2], TP: [cluster=draw]
...
70: [A to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=25], TP: [cluster=draw]
71: [A to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw]
72: [B to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw]
73: [A to <all>, 0 bytes, flags=OOB|INTERNAL], hdrs: NAKACK2: [HIGHEST_SEQNO, seqno=25], TP: [cluster=draw]
74: [B to A, 0 bytes, flags=OOB], hdrs: GMS: GmsHeader[LEAVE_REQ]: mbr=B, UNICAST3: DATA, seqno=3, TP: [cluster=draw]
75: [A to B, 0 bytes, flags=OOB|NO_RELIABILITY|INTERNAL], hdrs: GMS: GmsHeader[LEAVE_RSP], TP: [cluster=draw]
This shows a typical conversation between A (coordinator) and B: B sends a discovery request, finds A and asks it to join
(JOIN_REQ). A then multicasts (A to <all>) a view (VIEW) to all members, and sends a JOIN_RSP to B.
Later, B leaves by sending a LEAVE_REQ to A and A responds with a LEAVE_RSP message back to B.
Instead of redirecting the output to a file, it could be piped into ParseMessages:
tshark -l -i en0 -i lo0 -T fields -e data udp and portrange 7800-7801 | java org.jgroups.tests.ParseMessages.
|
|
When using TCP or TCP_NIO2 (e.g. tshark -l -i en0 -i lo0 -T fields -e data tcp and portrange 7800-7801),
ParseMessages has to be started with command line option -tcp. This ensures that the length preceding each TCP
JGroups message is not interpreted as something else (e.g. the version). Also, on connection establishment, a cookie
and the local address is sent to the remote peer, and this additional data is also parsed correctly with the
-tcp option.
|
5.16.2. Wireshark
When we have captured a number of packets in wireshark, we can select "File" → "Export Specified Packets...":
Here, we can export selected number of packets, or all packets. In the example, the exported packets will be written to
a file called jgroups-tcp.pcapng.
To parse this file and extract only the data sections, tshark can be used:
[belasmac] /Users/bela$ tshark -r jgroups-tcp.pcapng -Tfields -edata|jt ParseMessages -tcp 1: [21e26d56-2928-7008-1168-0fcf2d2f2b9d to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=118], TP: [cluster=draw] ... 32: [21e26d56-2928-7008-1168-0fcf2d2f2b9d to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=149], TP: [cluster=draw] 33: [21e26d56-2928-7008-1168-0fcf2d2f2b9d to <all>, 0 bytes, flags=OOB|INTERNAL], hdrs: NAKACK2: [HIGHEST_SEQNO, seqno=149], TP: [cluster=draw] 34: [21e26d56-2928-7008-1168-0fcf2d2f2b9d to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 35: [89a4b2f9-c15e-d276-88a5-a01f8cbde58a to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw]
The -r options reads packets from the given input file and the -Tfields -edata options extract the data portion
(containing the JGroups messages) only. This is piped to ParseMessages (with the -tcp option, as the wireshark
data was captured from a TCP connection), which prints the JGroups messages to stdout.
5.16.3. tcpdump
tcpdump can be used with the -w <filename> command line option to save all captured packets to a file in PCAPNG
(wireshark/libpcap) format.
In the example below (edited), however, we’re piping (options -U -w -) the captured packets to
tshark which extracts the JGroups portion and in turn pipes this to ParseMessages:
[belasmac] /Users/bela$ sudo tcpdump -n -U -i lo0 -w - tcp and portrange 7800-7801 |tshark -l -r - -Tfields -edata|jt ParseMessages -tcp tcpdump: listening on lo0, link-type NULL (BSD loopback), capture size 262144 bytes 1: [c0b6a011-16f9-699d-dd8c-68f6cc880ddd to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 2: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 3: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=426], TP: [cluster=draw] 4: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 0 bytes, flags=OOB|INTERNAL], hdrs: NAKACK2: [HIGHEST_SEQNO, seqno=426], TP: [cluster=draw] 9: [c0b6a011-16f9-699d-dd8c-68f6cc880ddd to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 10: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 11: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=427], TP: [cluster=draw] 12: [c0b6a011-16f9-699d-dd8c-68f6cc880ddd to 43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c, 44 bytes, flags=OOB|NO_RELIABILITY|INTERNAL], hdrs: STABLE: [STABLE_GOSSIP] view-id= [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c|1], TP: [cluster=draw] 13: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 0 bytes, flags=OOB|INTERNAL], hdrs: NAKACK2: [HIGHEST_SEQNO, seqno=427], TP: [cluster=draw] 14: [c0b6a011-16f9-699d-dd8c-68f6cc880ddd to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 15: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 0 bytes, flags=INTERNAL], hdrs: FD_ALL: heartbeat, TP: [cluster=draw] 16: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=428], TP: [cluster=draw] 17: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=429], TP: [cluster=draw] 18: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=430], TP: [cluster=draw] 19: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=431], TP: [cluster=draw] 20: [43c0d32e-a9ee-cb3d-578d-4af5fcd5c72c to <all>, 13 bytes], hdrs: NAKACK2: [MSG, seqno=432], TP: [cluster=draw] 54 packets captured 134 packets received by filter 0 packets dropped by kernel
5.17. Determining the coordinator and controlling view generation
In 3.4 the membership change algorithm was made pluggable; now application code can be called to determine how a new view is created. This is done for both regular views, e.g. caused by joins, leaves or crashes, and for merge views.
The tenet that the coordinator is always the first member of a view has not changed, but because the view generation can be done by application code, that code essentially also controls which member should be the coordinator.
This can be used to for example pin the coordinatorship to only certain beefy servers. Another example is to make sure that only one of the previous coordinators becomes the new coordinator after a merge. This reduces the frequency with which the coordinator moves around and thus increases stability for singleton services (services which are started only on one node in a given cluster).
To do this, interface MembershipChangePolicy has to be implemented:
public interface MembershipChangePolicy {
List<Address> getNewMembership(final Collection<Address> current_members,
final Collection<Address> joiners,
final Collection<Address> leavers,
final Collection<Address> suspects);
List<Address> getNewMembership(final Collection<Collection<Address>> subviews);
}The first method is called whenever a regular view needs to be created. Parameter current_members
is a list of the current members in the view. Joiners is the list of new members,
leavers the members which want to leave the cluster and suspects the members which
were suspected to have crashed.
The default policy adds the joiners to the end of the current members and removes suspected and leaving members.
The second method accepts a list of membership lists; each list represents a subview that needs to get
merged into a new MergeView. For example, we could have {A,B,C}, {M,N,O,P} and
{X,Y,Z}. A, M and X are the respective coordinators of the subviews and the task of the code
is to determine the single coordinator which will be coordinator of the merged
view. The default implementation adds all subview coordinators to a sorted set, takes the first (say M),
adds it to the resulting list and then adds the subviews in turn. This could result in a MergeView like
{M,A,B,C,N,O,P,X,Y,Z}.
|
|
Ordering and duplicate elements
In both regular and merge views, it is important that there are no duplicate members. It is entirely
possible to get overlapping subviews in the case of a merge, for instance:
{A,B,C}, {C,D} and {C,D}. This cannot
result in C or D being present in the resulting merge view multiple times.
|
A MembershipChangePolicy can be set in GMS via property membership_change_policy,
which accepts the fully qualified classname of the implementation of MembershipChangePolicy. There is
also a setter, setMembershipChangePolicy() which can be used to set the change policy
programmatically.
The following example shows how to pin coordinatorship to a certain subset of nodes in a cluster.
Beefy nodes need to be marked as such, and this is done by using a special address, generated by an address generator (see Generating custom addresses) in JChannel:
if(beefy)
channel.setAddressGenerator(new AddressGenerator() {
public Address generateAddress() {
return PayloadUUID.randomUUID(channel.getName(), "beefy");
}
});
}First we check if the current node that’s about to be started needs to be marked as beefy. This would typically be passed to the instance via a command flag. If so, we grab the current channel (before it is started) and set an AddressGenerator which simply creates a subclass of UUID, a PayloadUUID.
The MembershipChangePolicy now knows if a node is beefy or not by checking if the node’s
address is a PayloadUUID (versus a regular UUID).
A possible implementation of MembershipChangePolicy is shown below:
public List<Address> getNewMembership(final Collection<Address> current_members,
final Collection<Address> joiners,
final Collection<Address> leavers,
final Collection<Address> suspects) {
Membership retval=new Membership();
// add the beefy nodes from the current membership first
for(Address addr: current_members) {
if(addr instanceof PayloadUUID)
retval.add(addr);
}
// then from joiners
for(Address addr: joiners) {
if(addr instanceof PayloadUUID)
retval.add(addr);
}
// then add all non-beefy current nodes
retval.add(current_members);
// finally the non-beefy joiners
retval.add(joiners);
retval.remove(leavers);
retval.remove(suspects);
return retval.getMembers();
}The idea is simple: we want beefy servers to be the first elements of a view. However, when a new beefy server joins, it should not become the new coordinator if the current coordinator already is a beefy server, but add itself to the end of the beefy servers, in front of non-beefy servers.
First we create a Membership, which is an ordered list without duplicates. We then iterate through
the current membership and add the beefy servers to the list. The same is done with beefy joiners.
After that, we simply add all other current members (duplicates are suppressed by Membership)
and joiners and remove suspected and leaving members.
The effect of this is that - while there are beefy servers in a view - the oldest beefy server will be the coordinator, then the second-oldest and so on. When no beefy servers are left, the oldest non-beefy server will be coordinator. When a beefy server joins again, it will become coordinator, taking the coordinatorship away from the previous non-beefy server.
5.18. ForkChannels: light-weight channels to piggy-back messages over an existing channel
A ForkChannel is a subclass of JChannel (JChannel) implementing only a subset of methods (unimplemented methods throw an UnsupportedOperationException). It is a light-weight channel, referencing a JChannel (main channel), and it is cheap to create a ForkChannel, connect to a cluster, disconnect from it and close the channel.
A ForkChannel can be forked off of an existing stack (hence the name) and can add its own protocols to the newly created fork stack. Fork stacks can be created declaratively (at main channel creation time) or dynamically using the programmatic API.
The main use case for ForkChannels are
-
No need to configure and create a separate channel, but use of an existing JChannel (e.g. grabbed from Infinispan or WildFly) for private communication. Example: if we’re running an Infinispan cache in a cluster and need the cluster nodes to communicate with each other, then we can create a ForkChannel to do that. The main channel used by Infinispan does not see the communication going on over the private fork channel, and vice versa. This is because a fork channel is given a unique ID and that ID is used to deliver messages sent by it only to fork channels with the same ID.
-
If we cannot for some reason modify the main stack’s configuration, we can create a fork channel and a corresponding fork stack and add the protocols we need to that fork stack. Example: an application needs a fork stack with COUNTER (a distributed atomic counter) on top. To do so, it can create a fork stack with COUNTER and a fork channel connecting to that stack, and it will now have distributed atomic counter capabilities on its fork stack, which is not available in the main stack.
The architecture is shown in Architecture of a ForkChannel.
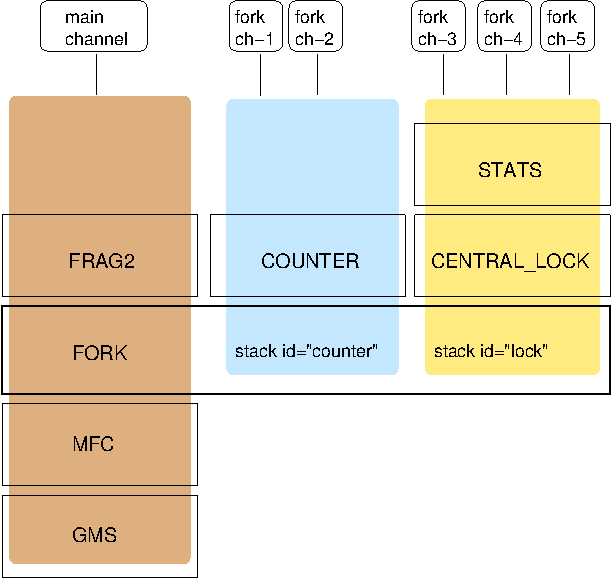
In the example, a main channel and 5 fork channels are shown. They are all running in the same JVM.
The brown stack to the left is the main stack and it has the main channel connected to it. Not all protocols are shown, but we’ve listed the GMS, MFC, FORK and FRAG2 protocols. The FORK protocol needs to be present in the main stack, or else fork stacks can not be created.
The FORK protocol of the main stack contains 2 fork stacks: "counter" and "lock". These are fork stack IDs and are used when creating a fork channel to determine whether fork channels share the same fork stack, or not.
The blue stack in the middle is a fork-stack with fork stack ID "counter". It adds protocol COUNTER to the protocols provided by the main stack. Therefore a message passing down through fork stack "counter" will pass through protocols COUNTER, FORK, MFC and GMS.
Fork channels have an ID, too, e.g. "fork-ch1". The combination of fork stack ID and fork channel ID is used to demultiplex incoming messages. For example, if fork channel 2 sends a message, it’ll pass through COUNTER and into FORK. There, a header is added to the message, containing fork channel ID="fork-ch2" and fork stack ID="counter". Then the message passes down the main stack, through MFC, GMS and so on.
When the message is received, it passes up the reverse order: first GMS, then MFC, then it is received by FORK. If there is no header, FORK passes the message up the main stack, where it passes through FRAG2 and ends up in the main channel. If a header is present, the fork stack ID is used to find the correct fork-stack ("counter"). If no fork stack is found, a warning message is logged. The message then passes through COUNTER. Finally, the fork channel ID ("fork-ch2") is used to find the right fork channel and the message is passed to it.
Note that a fork stack can have more than 1 protocol; for example the yellow fork stack on the right side has 2 protocols. A fork stack can also have 0 protocols. In that case, it is only used to have a private channel for communication, and no additional protocols are required on top of the main stack.
Fork channels sharing the same fork stack also share state. For example, fork channels fork-ch1 and fork-ch2 share COUNTER, which means they will see each other’s increments and decrements of the same counter. If fork stack "lock" also had a COUNTER protocol, and fork-ch1 anf fork-ch4 accessed a counter with the same name, they would still not see each other’s changes, as they’d have 2 different COUNTER protocols.
5.18.1. Configuration
Fork stacks can be created programmatically or declaratively. Let’s take a look at the latter first. The XML fragment below shows this:
...
<MFC max_credits="2M" min_threshold="0.4"/>
<FORK config="/home/bela/fork-stacks.xml" />
<FRAG2 frag_size="60K" />
...FORK refers to an external file to configure its fork stacks:
<fork-stacks xmlns="fork-stacks">
<fork-stack id="counter">
<config>
<COUNTER bypass_bundling="true"/>
</config>
</fork-stack>
<fork-stack id="lock">
<config>
<CENTRAL_LOCK num_backups="2"/>
<STATS/>
</config>
</fork-stack>
</fork-stacks>The file fork-stacks.xml defines 2 fork stacks: "counter" and "lock". Each fork-stack element has an id attribute which defines the fork stack’s ID. Note that all fork stacks have to have unique IDs.
After the fork-stack element, the child element starting with config is a regular JGroups XML config file schema, where protocols are defined from bottom to top. For example, fork stack "lock" defines that CENTRAL_LOCK is the first protocol on top of FORK for the given fork stack, and STATS is on top of CENTRAL_LOCK.
When FORK is initialized, it will create the 2 fork stacks. When fork channels are created (see the next section), they can pick one of the 2 existing fork stacks to be created over, or they can dynamically create new fork stacks.
5.18.2. Creation of fork channels
A fork channel is created by instantiating a new ForkChannel object:
JChannel main_ch=new JChannel("/home/bela/udp.xml").name("A");
ForkChannel fork_ch=new ForkChannel(main_ch, "lock", "fork-ch4",
new CENTRAL_LOCK(), new STATS());
main_ch.connect("cluster");
fork_ch.connect("bla");First the main channel is created. Note that udp.xml may or may not contain FORK, but for this example, we assume it is present.
Then the ForkChannel is created. It is passed the main channel, the fork stack ID ("lock") and the fork channel ID ("fork-ch4"), plus a list of already instantiated protocols (CENTRAL_LOCK and STATS). If FORK already contains a fork stack with ID="lock", the existing fork stack will be used, or else a new one will be created with protocols CENTRAL_LOCK and STATS. Then a new fork channel with ID="fork-ch4" will be added to the top of fork stack "lock". An exception will be thrown if a fork channel with the same ID already exists.
The main channel then calls connect(), and - after this - the ForkChannel also calls connect(). (Note that the
latter’s connect argument (the cluster name)) is ignored as fork channels have the same cluster name as the
main channel they reference. The local address, name, view and state are also the same.
|
|
A fork channel’s connect() must be called after the main channel has been connected. If this is not the case,
ForkChannel.connect() will throw an exception.
|
The lifetime of a fork channel is always dominated by the main channel: if the main channel is closed, all fork channels atttached to it are in closed state, too, and trying to send a message will throw an exception.
The example above showed the simplified constructor, which requires the FORK protocol to be present in the stack. There’s another constructor which allows for FORK to be created dynamically if not present:
public ForkChannel(final Channel main_channel,
String fork_stack_id, String fork_channel_id,
boolean create_fork_if_absent,
int position,
Class<? extends Protocol> neighbor,
Protocol ... protocols) throws Exception;In addition to passing the main channel, the fork stack and channel IDs and the list of protocols, this constructor also allows a user to create FORK in the main stack if not present. To do so, create_fork_if_absent has to be set to true (else an exception is thrown if FORK is not found), and the neighbor protocol (e.g. FRAG2.class) has to be defined, plus the position (ProtocolStack.ABOVE/BELOW) relative to the neighbor protocol has to be defined as well.
The design of FORK / ForkChannel is discussed in more detail in FORK.txt
6. List of Protocols
This chapter describes the most frequently used protocols, and their configuration. Ergonomics (Ergonomics) strives to reduce the number of properties that have to be configured, by dynamically adjusting them at run time, however, this is not yet in place.
Meanwhile, we recommend that users should copy one of the predefined configurations (shipped with JGroups), e.g.
udp.xml or tcp.xml, and make only minimal changes to it.
This section is work in progress; we strive to update the documentation as we make changes to the code.
6.1. Properties availabe in every protocol
The table below lists properties that are available in all protocols, as they’re defined in the superclass of all protocols, org.jgroups.stack.Protocol.
| Name | Description |
|---|---|
stats |
Whether the protocol should collect protocol-specific runtime statistics. What those
statistics are (or whether they even exist) depends on the particular protocol.
See the |
ergonomics |
Turns on ergonomics. See Ergonomics for details. |
id |
Gives the protocol a different ID if needed so we can have multiple instances of it in the same stack |
6.2. System properties
The table below lists system properties which can be used to override attribute values, mostly in protocols. For example, if we have a config like this:
<UDP bind_addr="127.0.0.1" />, then the bind address will be 127.0.0.1. However, if we run the system with -Djgroups.bind_addr=1.2.3.4 (see below),
the bind address will be 1.2.3.4.
Note that if we use our own variables, like this:
<UDP bind_addr="${my.bind_addr:127.0.0.1}" />, then system property my.bind_addr takes precedence over jgroups.bind_addr. In the above case, the actual bind
address chosen will be:
System properties |
Bind address picked |
|
|
|
|
none |
|
| Name | Description |
|---|---|
jgroups.bind_addr |
The network interface to be used. Example: |
jgroups.external_addr |
The external bind address to be used. Overrides |
jgroups.external_port |
The external port to be used by the transport. |
jgroups.tcp.client_bind_addr |
The network interface client sockets in TCP should bind to. Overrides |
jgroups.tcpping.initial_hosts |
The list of initial hosts in TCPPING |
jgroups.udp.mcast_addr |
The multicast address used by UDP |
jgroups.udp.mcast_port |
The multicast port used by UDP |
jgroups.udp.ip_ttl |
The TTL used by UDP |
jgroups.mping.mcast_addr |
The multicast address used by MPING |
jgroups.mping.mcast_port |
The multicast port used by MPING |
jgroups.mping.ip_ttl |
The TTL used by MPING |
jgroups.conf.magic_number_file |
The file where the mappings between IDs and classes are defined.
Default: |
jgroups.conf.protocol_id_file |
The file where the mappings between IDs and protocols are defined.
Default: |
jgroups.name_cache.max_elements |
The max number of elements in the NameCache which holds mappings between addresses and logical names |
jgroups.name_cache.max_age |
The max age (in milliseconds) a mapping between address and logical name is kept in the NameCache. Not that elements are only evicted if there’s not enough room. |
jgroups.ipmcast.prefix |
Needed if an IPv4 multicast address is used in an IPv6 system. The prefix (default: |
jgroups.use.jdk_logger |
If true, the JDK logger ( |
jgroups.log_class |
The fully qualified name of a class implementing a logger to be used. See Logging for details. |
jgroups.msg.default_headers |
System prop for defining the default number of headers in a Message (default: 4). |
6.3. Transport
TP is the base class for all transports, e.g. UDP and TCP. All of the properties
defined here are inherited by the subclasses. The properties for TP are:
| Name | Description |
|---|---|
bind_addr |
The bind address which should be used by this transport. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL, NON_LOOPBACK, match-interface, match-host, match-address |
bind_port |
The port to which the transport binds. Default of 0 binds to any (ephemeral) port. See also port_range |
bundler_capacity |
The max number of elements in a bundler if the bundler supports size limitations |
bundler_num_spins |
Number of spins before a real lock is acquired |
bundler_type |
The type of bundler used ("ring-buffer", "transfer-queue" (default), "sender-sends" or "no-bundler") or the fully qualified classname of a Bundler implementation |
bundler_wait_strategy |
The wait strategy for a RingBuffer |
diag_enable_tcp |
Use a TCP socket to listen for probe requests (ignored if enable_diagnostics is false) |
diag_enable_udp |
Use a multicast socket to listen for probe requests (ignored if enable_diagnostics is false) |
diagnostics_addr |
Multicast address for diagnostic probing. Used when diag_enable_udp is true |
diagnostics_bind_addr |
Bind address for diagnostic probing. Used when diag_enable_tcp is true |
diagnostics_bind_interfaces |
Comma delimited list of interfaces (IP addresses or interface names) that the diagnostics multicast socket should bind to |
diagnostics_passcode |
Authorization passcode for diagnostics. If specified every probe query will be authorized |
diagnostics_port |
Port for diagnostic probing. Default is 7500 |
diagnostics_port_range |
The number of ports to be probed for an available port (TCP) |
diagnostics_ttl |
TTL of the diagnostics multicast socket |
drop_when_full |
When the queue is full, senders will drop a message rather than wait until space is available (https://issues.redhat.com/browse/JGRP-2765). Currently only applicable to TransferQueueBundler |
enable_diagnostics |
Switch to enable diagnostic probing. Default is true |
external_addr |
Use "external_addr" if you have hosts on different networks, behind firewalls. On each firewall, set up a port forwarding rule (sometimes called "virtual server") to the local IP (e.g. 192.168.1.100) of the host then on each host, set "external_addr" TCP transport parameter to the external (public IP) address of the firewall. |
external_port |
Used to map the internal port (bind_port) to an external port. Only used if > 0 |
level |
Sets the level |
log_discard_msgs |
whether or not warnings about messages from different groups are logged |
log_discard_msgs_version |
whether or not warnings about messages from members with a different version are discarded |
logical_addr_cache_expiration |
Time (in ms) after which entries in the logical address cache marked as removable can be removed. 0 never removes any entries (not recommended) |
logical_addr_cache_max_size |
Max number of elements in the logical address cache before eviction starts |
logical_addr_cache_reaper_interval |
Interval (in ms) at which the reaper task scans logical_addr_cache and removes entries marked as removable. 0 disables reaping. |
loopback_copy |
Whether or not to make a copy of a message before looping it back up. Don’t use this; might get removed without warning |
loopback_separate_thread |
Loop back the message on a separate thread or use the current thread. Don’t use this; might get removed without warning |
max_bundle_size |
Maximum number of bytes for messages to be queued until they are sent |
message_processing_policy |
The fully qualified name of a class implementing MessageProcessingPolicy |
msg_processing_max_buffer_size |
Max number of messages buffered for consumption of the delivery thread in MaxOneThreadPerSender. 0 creates an unbounded buffer |
port_range |
The range of valid ports: [bind_port .. bind_port+port_range ]. 0 only binds to bind_port and fails if taken |
receive_interfaces |
Comma delimited list of interfaces (IP addresses or interface names) to receive multicasts on |
receive_on_all_interfaces |
If true, the transport should use all available interfaces to receive multicast messages |
spawn_thread_on_full_pool |
When an internal message cannot be processed because of a full internal pool, a new thread is created to process the message. Setting this value to false disables this, and the message will be discarded (like regular messages) |
suppress_time_different_cluster_warnings |
Time during which identical warnings about messages from a member from a different cluster will be suppressed. 0 disables this (every warning will be logged). Setting the log level to ERROR also disables this. |
suppress_time_different_version_warnings |
Time during which identical warnings about messages from a member with a different version will be suppressed. 0 disables this (every warning will be logged). Setting the log level to ERROR also disables this. |
thread_dump_path |
Path to which the thread dump will be written. Ignored if null |
thread_dumps_threshold |
The number of times a thread pool needs to be full before a thread dump is logged |
thread_naming_pattern |
Thread naming pattern for threads in this channel. Valid values are "pcl": "p": includes the thread name, e.g. "Incoming thread-1", "UDP ucast receiver", "c": includes the cluster name, e.g. "MyCluster", "l": includes the local address of the current member, e.g. "192.168.5.1:5678" |
thread_pool_enabled |
Enable or disable the thread pool |
thread_pool_keep_alive_time |
Timeout in milliseconds to remove idle threads from pool |
thread_pool_max_threads |
Maximum thread pool size for the thread pool |
thread_pool_min_threads |
Minimum thread pool size for the thread pool |
time_service_interval |
Interval (in ms) at which the time service updates its timestamp. 0 disables the time service |
use_common_fork_join_pool |
If true, the common fork-join pool will be used; otherwise a custom ForkJoinPool will be created |
use_fibers |
Create fibers (if true) or regular threads (if false). This requires Java 15/Loom. If not present, use_fibers will be set to false and regular threads will be created. Note that the ThreadFactoryneeds to support this (DefaultThreadFactory does) |
use_fork_join_pool |
If enabled, a ForkJoinPool will be used rather than a ThreadPoolExecutor |
use_ip_addrs |
Use IP addresses (IpAddressUUID) instead of UUIDs as addresses. This is currently not compatible with RELAY2: disable if RELAY2 is used. |
who_has_cache_timeout |
Timeout (in ms) to determine how long to wait until a request to fetch the physical address for a given logical address will be sent again. Subsequent requests for the same physical address will therefore be spaced at least who_has_cache_timeout ms apart |
bind_addr can be set to the address of a network interface, e.g. 192.168.1.5.
It can also be set for the entire stack using system property -Djgroups.bind_addr, which
provides a value for bind_addr unless it has already been set in the XML config.
The following special values are also recognized for bind_addr:
- GLOBAL
-
Picks a global IP address if available. If not, falls back to a SITE_LOCAL IP address.
- SITE_LOCAL
-
Picks a site local (non routable) IP address, e.g. from the
192.168.0.0or10.0.0.0address range. - LINK_LOCAL
-
Picks a link-local IP address, from
169.254.1.0through169.254.254.255. - NON_LOOPBACK
-
Picks any non loopback address.
- LOOPBACK
-
Pick a loopback address, e.g.
127.0.0.1. - match-interface
-
Pick an address which matches a pattern against the interface name, e.g.
match-interface:eth.\* - match-address
-
Pick an address which matches a pattern against the host address, e.g.
match-address:192.168.\* - match-host
-
Pick an address which matches a pattern against the host name, e.g.
match-host:linux.\* - custom
-
Use custom code to pick the bind address. The value after
customneeds to be the fully qualified name of a class implementingSupplier<InetAddress>, e.g. bind_addr="custom:com.acme.BindAddressPicker". An example of setting the bind address in UDP to use a site local address is:
<UDP bind_addr="SITE_LOCAL" />This will pick any address of any interface that’s site-local, e.g. a 192.168.x.x or
10.x.x.x address.
Since 4.0, it is possible to define a list of addresses in bind_addr. Each entry of the list will be tried and the
first entry that works will be used. Example:
<UDP bind_addr="match-interface:eth2,10.5.5.5,match-interface:en.\*,127.0.0.1" />This would try to bind to eth2 first. If not found, then an interface with address 10.5.5.5 would be tried,
then an interface starting with en would be tried. If still not found, we’d bind to 127.0.0.1.
6.3.1. UDP
UDP uses IP multicast for sending messages to all members of a group and UDP datagrams for unicast messages (sent to a single member). When started, it opens a unicast and multicast socket: the unicast socket is used to send/receive unicast messages, whereas the multicast socket sends and receives multicast messages. The channel’s physical address will be the address and port number of the unicast socket. A protocol stack with UDP as transport protocol is typically used with clusters whose members run in the same subnet. If running across subnets, an admin has to ensure that IP multicast is enabled across subnets. It is often the case that IP multicast is not enabled across subnets. In such cases, the stack has to either use UDP without IP multicasting or other transports such as TCP.
| Name | Description |
|---|---|
disable_loopback |
If true, disables IP_MULTICAST_LOOP on the MulticastSocket (for sending and receiving of multicast packets). IP multicast packets send on a host P will therefore not be received by anyone on P. Use with caution. |
ip_mcast |
Multicast toggle. If false multiple unicast datagrams are sent instead of one multicast. Default is true |
ip_ttl |
The time-to-live (TTL) for multicast datagram packets. Default is 8 |
mcast_group_addr |
The multicast address used for sending and receiving packets |
mcast_port |
The multicast port used for sending and receiving packets. Default is 7600 |
mcast_receiver_threads |
Number of multicast receiver threads, all reading from the same MulticastSocket. If de-serialization is slow, increasing the number of receiver threads might yield better performance. |
mcast_recv_buf_size |
Receive buffer size of the multicast datagram socket |
mcast_send_buf_size |
Send buffer size of the multicast datagram socket |
suppress_time_out_of_buffer_space |
Suppresses warnings on Mac OS (for now) about not enough buffer space when sending a datagram packet |
tos |
Traffic class for sending unicast and multicast datagrams. Default is 0 |
ucast_receiver_threads |
Number of unicast receiver threads, all reading from the same DatagramSocket. If de-serialization is slow, increasing the number of receiver threads might yield better performance. |
ucast_recv_buf_size |
Receive buffer size of the unicast datagram socket |
ucast_send_buf_size |
Send buffer size of the unicast datagram socket |
6.3.2. TCP
Specifying TCP in your protocol stack tells JGroups to use TCP to send messages between cluster members. Instead of using a multicast bus, the cluster members create a mesh of TCP connections. For example, while UDP sends 1 IP multicast packet when sending a message to a cluster of 10 members, TCP needs to send the message 9 times. It sends the same message to the first member, to the second member, and so on (excluding itself as the message is looped back internally).
This is slow, as the cost of sending a group message is O(n) with TCP, where it is O(1) with UDP. As the cost of sending a group message with TCP is a function of the cluster size, it becomes higher with larger clusters.
|
|
We recommend to use UDP for larger clusters, whenever possible |
| Name | Description |
|---|---|
client_bind_addr |
The address of a local network interface which should be used by client sockets to bind to. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
client_bind_port |
The local port a client socket should bind to. If 0, an ephemeral port will be picked. |
conn_expire_time |
Max time connection can be idle before being reaped (in ms) |
defer_client_bind_addr |
If true, client sockets will not explicitly bind to bind_addr but will defer to the native socket |
linger |
SO_LINGER in msec. Default of -1 disables it |
max_length |
The max number of bytes a message can have. If greater, an exception will be thrown. 0 disables this |
peer_addr_read_timeout |
Max time to block on reading of peer address |
reaper_interval |
Reaper interval in msec. Default is 0 (no reaping) |
recv_buf_size |
Receiver buffer size in bytes |
send_buf_size |
Send buffer size in bytes |
sock_conn_timeout |
Max time allowed for a socket creation in connection table |
tcp_nodelay |
Should TCP no delay flag be turned on |
| Name | Description |
|---|---|
buffered_input_stream_size |
Size of the buffer of the BufferedInputStream in TcpConnection. A read always tries to read ahead as much data as possible into the buffer. 0: default size |
buffered_output_stream_size |
Size of the buffer of the BufferedOutputStream in TcpConnection. Smaller messages are buffered until this size is exceeded or flush() is called. Bigger messages are sent immediately. 0: default size |
log_accept_error |
Log a warning (or not) when ServerSocket.accept() throws an exception |
6.3.3. TCP_NIO2
TCP_NIO2 is similar to TCP, but uses NIO (= Non blocking IO) to send messages to and receive messages from members. Contrary to TCP, it doesn’t use 1 thread per connection, but handles accepts, connects, reads and writes in a single thread.
All of these operations are guaranteed to never block.
For example, if a read is supposed to receive 1000 bytes and only reveived 700, the read reads the 700 bytes, saves them somewhere and later - when the remaining 300 bytes have been received - is notified to complete the read and then returns the 1000 bytes to the application.
Using a single thread is not a problem, as operations will never block. The only potentially blocking operation, namely delivering messages up to the application, is done via the regular or OOB thread pools, as usual.
While TCP and TCP_NIO2 both have the N-1 problem of sending cluster wide messages (contrary to UDP), TCP_NIO2 is able to handle a larger number of connections than TCP, as it doesn’t use the thread-per-connection model, and - contrary to TCP, but similar to UDP - it doesn’t block when sending or receiving messages.
| Name | Description |
|---|---|
client_bind_addr |
The address of a local network interface which should be used by client sockets to bind to. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
client_bind_port |
The local port a client socket should bind to. If 0, an ephemeral port will be picked. |
conn_expire_time |
Max time connection can be idle before being reaped (in ms) |
defer_client_bind_addr |
If true, client sockets will not explicitly bind to bind_addr but will defer to the native socket |
linger |
SO_LINGER in msec. Default of -1 disables it |
max_length |
The max number of bytes a message can have. If greater, an exception will be thrown. 0 disables this |
peer_addr_read_timeout |
Max time to block on reading of peer address |
reaper_interval |
Reaper interval in msec. Default is 0 (no reaping) |
recv_buf_size |
Receiver buffer size in bytes |
send_buf_size |
Send buffer size in bytes |
sock_conn_timeout |
Max time allowed for a socket creation in connection table |
tcp_nodelay |
Should TCP no delay flag be turned on |
| Name | Description |
|---|---|
copy_on_partial_write |
If true, a partial write will make a copy of the data so a buffer can be reused |
max_send_buffers |
The max number of outgoing messages that can get queued for a given peer connection (before dropping them). Most messages will get retransmitted; this is mainly used at startup, e.g. to prevent dropped discovery requests or responses (sent unreliably, without retransmission). |
reader_idle_time |
Number of ms a reader thread on a given connection can be idle (not receiving any messages) until it terminates. New messages will start a new reader |
6.3.4. TUNNEL
TUNNEL is described in TUNNEL.
| Name | Description |
|---|---|
gossip_router_hosts |
A comma-separated list of GossipRouter hosts, e.g. HostA[12001],HostB[12001] |
reconnect_interval |
Interval in msec to attempt connecting back to router in case of torn connection. Default is 5000 msec |
tcp_nodelay |
Should TCP no delay flag be turned on |
use_nio |
Whether to use blocking (false) or non-blocking (true) connections. If GossipRouter is used, this needs to be false; if GossipRouterNio is used, it needs to be true |
6.4. Initial membership discovery
The task of the discovery is to find an initial membership, which is used to determine the current coordinator. Once a coordinator is found, the joiner sends a JOIN request to the coord.
Discovery is also called periodically by MERGE2 (see [MERGE2]), to see if we have
diverging cluster membership information.
6.4.1. Discovery
Discovery is the superclass for all discovery protocols and therefore its
properties below can be used in any subclass.
Discovery sends a discovery request, and waits for num_initial_members discovery
responses, or timeout ms, whichever occurs first, before returning. Note that
break_on_coord_rsp="true" will return as soon as we have a response from a coordinator.
| Name | Description |
|---|---|
async_discovery |
If true then the discovery is done on a separate timer thread. Should be set to true when discovery is blocking and/or takes more than a few milliseconds |
async_discovery_use_separate_thread_per_request |
If enabled, use a separate thread for every discovery request. Can be used with or without async_discovery |
break_on_coord_rsp |
Return from the discovery phase as soon as we have 1 coordinator response |
discovery_rsp_expiry_time |
Expiry time of discovery responses in ms |
max_members_in_discovery_request |
Max size of the member list shipped with a discovery request. If we have more, the mbrs field in the discovery request header is nulled and members return the entire membership, not individual members |
max_rank_to_reply |
The max rank of this member to respond to discovery requests, e.g. if max_rank_to_reply=2 in {A,B,C,D,E}, only A (rank 1) and B (rank 2) will reply. A value ⇐ 0 means everybody will reply. This attribute is ignored if TP.use_ip_addrs is false. |
num_discovery_runs |
The number of times a discovery process is executed when finding initial members (https://issues.jboss.org/browse/JGRP-2317) |
return_entire_cache |
Whether or not to return the entire logical-physical address cache mappings on a discovery request, or not. |
send_cache_on_join |
When a new node joins, and we have a static discovery protocol (TCPPING), then send the contents of the discovery cache to new and existing members if true (and we’re the coord). Addresses JGRP-1903 |
stagger_timeout |
If greater than 0, we’ll wait a random number of milliseconds in range [0..stagger_timeout] before sending a discovery response. This prevents traffic spikes in large clusters when everyone sends their discovery response at the same time |
use_disk_cache |
If a persistent disk cache (PDC) is present, combine the discovery results with the contents of the disk cache before returning the results |
Discovery and local caches
Besides finding the current coordinator in order to send a JOIN request to it, discovery also fetches information about members and adds it to its local caches. This information includes the logical name, UUID and IP address/port of each member. When discovery responses are received, the information in it will be added to the local caches.
Since 3.5 it is possible to define this information in a single file, with each line providing information about one member. The file contents look like this:
m1.1 1 10.240.78.26:7800 T m2.1 2 10.240.122.252:7800 F m3.1 3 10.240.199.15:7800 F
This file defines information about 3 members m1.1, m2.1 and m3.1. The first element ("m1.1") is the
logical name. Next comes the UUID (1), followed by the IP address and port (10.240.78.26:7800).
T means that the member is the current coordinator.
Methods dumpCache() can be used to write the current contents of any member to a file (in the above
format) and addToCache() can be used to add the contents of a file to any member. These operations
can for example be invoked via JMX or probe.sh.
Refer to the section on FILE_PING for more information on how to use these files to speed up
the discovery process.
6.4.2. PING
Initial (dirty) discovery of members. Used to detect the coordinator (oldest member), by mcasting PING requests to an IP multicast address. Each member responds with a packet {C, A}, where C=coordinator’s address and A=own address. After N milliseconds or M replies, the joiner determines the coordinator from the responses, and sends a JOIN request to it (handled by GMS). If nobody responds, we assume we are the first member of a group. Unlike TCPPING, PING employs dynamic discovery, meaning that the member does not have to know in advance where other cluster members are. PING uses the IP multicasting capabilities of the transport to send a discovery request to the cluster. It therefore requires UDP as transport.
6.4.3. TCPPING
TCPPING is used with TCP as transport, and uses a static list of cluster members’s addresses. See Using TCP and TCPPING for details.
| Name | Description |
|---|---|
initial_hosts_str |
Comma delimited list of hosts to be contacted for initial membership. Ideally, all members should be listed. If this is not possible, send_cache_on_join and / or return_entire_cache can be set to true |
max_dynamic_hosts |
max number of hosts to keep beyond the ones in initial_hosts |
port_range |
Number of additional ports to be probed for membership. A port_range of 0 does not probe additional ports. Example: initial_hosts=A[7800] port_range=0 probes A:7800, port_range=1 probes A:7800 and A:7801 |
|
|
It is recommended to include the addresses of all cluster members in initial_hosts.
|
6.4.4. TCPGOSSIP
TCPGOSSIP uses an external GossipRouter to discover the members of a cluster. See Using TCP and TCPGOSSIP for details.
| Name | Description |
|---|---|
initial_hosts |
Comma delimited list of hosts to be contacted for initial membership |
reconnect_interval |
Interval (ms) by which a disconnected stub attempts to reconnect to the GossipRouter |
sock_conn_timeout |
Max time for socket creation. Default is 1000 msec |
use_nio |
Whether to use blocking (false) or non-blocking (true) connections. If GossipRouter is used, this needs to be false; if GossipRouterNio is used, it needs to be true |
6.4.5. MPING
MPING (=Multicast PING) uses IP multicast to discover the initial membership. It can be used with all
transports, but usually is used in combination with TCP. TCP usually requires TCPPING, which has to list
all cluster members explicitly, but MPING doesn’t have this requirement. The typical use case for this
is when we want TCP as transport, but multicasting for discovery so we don’t have to define a static
list of initial hosts in TCPPING
MPING uses its own multicast socket for discovery. Properties bind_addr (can also
be set via -Djgroups.bind_addr=), mcast_addr and
mcast_port can be used to configure it.
Note that MPING requires a separate thread listening on the multicast socket for discovery requests.
| Name | Description |
|---|---|
bind_addr |
Bind address for multicast socket. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
bind_interface_str |
The interface (NIC) which should be used by this transport |
ip_ttl |
Time to live for discovery packets. Default is 8 |
mcast_addr |
Multicast address to be used for discovery |
mcast_port |
Multicast port for discovery packets. Default is 7555 |
receive_interfaces |
List of interfaces to receive multicasts on |
receive_on_all_interfaces |
If true, the transport should use all available interfaces to receive multicast messages |
send_interfaces |
List of interfaces to send multicasts on |
send_on_all_interfaces |
Whether send messages are sent on all interfaces. Default is false |
6.4.6. FILE_PING
FILE_PING can be used instead of GossipRouter in cases where no external process is desired.
Since 3.5, the way FILE_PING performs discovery has changed. The following paragraphs describe the new mechanism to discover members via FILE_PING or subclasses (e.g. S3_PING GOOGLE_PING or GOOGLE_PING2), so this applies to all cloud-based stores as well. Instead of storing 1 file per member in the file system or cloud store, we only store 1 file for all members. This has the advantage, especially in cloud stores, that the number of reads is not a function of the cluster size, e.g. we don’t have to perform 1000 reads for member discovery in a 1000 node cluster, but just a single read.
This is important as the cost of 1000 times the round trip time of a (REST) call to the cloud store is certainly higher that the cost of a single call. There may also be a charge for calls to the cloud, so a reduced number of calls lead to reduced charges for cloud store access, especially in large clusters.
The current coordinator is always in charge of writing the file; participants never write it, but only read it. When there is a split and we have multiple coordinator, we may also have multiple files.
The name of a file is always UUID.logical_name.list, e.g. 0000-0000-000000000001.m1.1.list, which has
a UUID of 1, a logical name of "m1.1" and the suffix ".list".
Removing a member which crashed or left gracefully
When we have view {A,B,C,D} (A being the coordinator), the file 2f73fcac-aecb-2a98-4300-26ca4b1016d2.A.list might
have the following contents:
C c0a6f4f8-a4a3-60c1-8420-07c81c0256d6 192.168.1.168:7802 F D 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e 192.168.1.168:7803 F A 2f73fcac-aecb-2a98-4300-26ca4b1016d2 192.168.1.168:7800 T B c6afa01d-494f-f340-c0db-9795102ac2a3 192.168.1.168:7801 F
It shows the 4 members with their UUIDs, IP addreses and ports, and the coordinator (A). When we now make C leave (gracefully, or by killing it), the file should have 3 lines, but it doesn’t:
C c0a6f4f8-a4a3-60c1-8420-07c81c0256d6 192.168.1.168:7802 F D 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e 192.168.1.168:7803 F A 2f73fcac-aecb-2a98-4300-26ca4b1016d2 192.168.1.168:7800 T B c6afa01d-494f-f340-c0db-9795102ac2a3 192.168.1.168:7801 F
Indeed, the entry for C is still present! Why?
The reason is that the entry for C is marked as removable, but the entry is not removed straight away, because that would require a call to the store, which might be expensive, or cost money. For instance, if the backend store is cloud based, then the REST call to the cloud store might cost money.
Therefore, removable members are only removed when the logical cache size exceeds its capacity. The capacity is defined
in TP.logical_addr_cache_max_size. Alternatively, if TP.logical_addr_cache_reaper_interval is greater than 0,
then a reaper task will scan the logical cache every logical_addr_cache_reaper_interval milliseconds and remove
elements marked as removable and older than TP.logical_addr_cache_expiration milliseconds.
We can look at the logical cache with JMX or probe (slightly edited):
[belasmac] /Users/bela/jgroups-azure$ probe.sh uuids #1 (338 bytes): local_addr=A [ip=192.168.1.168:7800, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=A uuids=3 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (9 secs old) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (5 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (1 secs old) #2 (338 bytes): local_addr=B [ip=192.168.1.168:7801, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=B uuids=3 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (1 secs old) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (5 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (2 secs old) #3 (339 bytes): local_addr=D [ip=192.168.1.168:7803, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=D uuids=3 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (1 secs old) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (11 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (1 secs old) 3 responses (3 matches, 0 non matches)
This shows that the reaper must have removed the stale entry for C already.
If we start C again and then kill it again and immediately look at the file, then the contents are:
D 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e 192.168.1.168:7803 F A 2f73fcac-aecb-2a98-4300-26ca4b1016d2 192.168.1.168:7800 T B c6afa01d-494f-f340-c0db-9795102ac2a3 192.168.1.168:7801 F C 5b36fe23-b151-6859-3953-97addfa2534d 192.168.1.168:7802 F
We can see that C is still present.
|
|
If we restart C a couple of time, the file will actually list multiple Cs. However, each entry is is different, as only the logical name is the same, but the actual addresses (UUIDs) are different. |
Running probe immediately after restarting C, before the reaper kicks in, it indeed shows the old C as being removable:
[belasmac] /Users/bela/jgroups-azure$ probe.sh uuids #1 (423 bytes): local_addr=A [ip=192.168.1.168:7800, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=A uuids=4 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (5 secs old) C: 5b36fe23-b151-6859-3953-97addfa2534d: 192.168.1.168:7802 (5 secs old, removable) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (9 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (11 secs old) #2 (423 bytes): local_addr=B [ip=192.168.1.168:7801, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=B uuids=4 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (15 secs old) C: 5b36fe23-b151-6859-3953-97addfa2534d: 192.168.1.168:7802 (5 secs old, removable) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (9 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (5 secs old) #3 (424 bytes): local_addr=D [ip=192.168.1.168:7803, version=4.0.0-SNAPSHOT, cluster=draw, 3 mbr(s)] local_addr=D uuids=4 elements: A: 2f73fcac-aecb-2a98-4300-26ca4b1016d2: 192.168.1.168:7800 (15 secs old) C: 5b36fe23-b151-6859-3953-97addfa2534d: 192.168.1.168:7802 (5 secs old, removable) D: 9db6cf43-138c-d7cb-8eb3-2aa4e7cb5f7e: 192.168.1.168:7803 (5 secs old) B: c6afa01d-494f-f340-c0db-9795102ac2a3: 192.168.1.168:7801 (11 secs old) 3 responses (3 matches, 0 non matches)
Here, we can see that C is marked as removable. Once its entry is 60 seconds old (logical_addr_cache_expiration), then
the reaper (if configured to run) will remove the element on its next run.
Configuration with a preconfigured bootstrap file
To speed up the discovery process when starting a large cluster, a predefined bootstrap file can be used. Every node then needs to have an entry in the file and its UUID and IP address:port needs to be the same as in the file. For example, when using the following bootstrap file:
m1.1 1 10.240.78.26:7800 T m2.1 2 10.240.122.252:7800 F m3.1 3 10.240.199.15:7800 F
, the member called "m1.1" needs to have a UUID of 1, and needs to run on host 10.240.78.26 on port 7800. The UUID can be injected via an AddressGenerator (see UPerf for an example). When a member starts, it loads the bootstrap file, which contains information about all other members, and thus (ideally) never needs to run a discovery process. In the above example, the new joiner also knows that the current coordinator (marked with a T) is m1.1, so it can send its JOIN request to that node. When the coordinator changes, or members not listed in the file join, the current coordinator writes the file again, so all members have access to the updated information when needed.
If a bootstrap discovery file is to be used, it needs to be placed into the file system or cloud store in the correct location and with the right name (see the Discovery section for naming details).
The design is discussed in more detail in CloudBasedDiscovery.txt
Removal of zombie files
By default, a new coordinator C never removes a file created by an old coordinator A. E.g. in {A,B,C,D} (with
coordinator A), if C becomes coordinator on a split {A,B} | {C,D}, then C doesn’t remove A's file, as there
is no way for C to know whether A crashed or whether A was partitioned away.
Every coordinator P installs a shutdown hook which removes P's file on termination. However, this doesn’t apply
to a process killed ungracefully, e.g. by kill -9. In this case, no shutdown hook will get called. If we had view
{A,B,C}, and A was killed via kill -9, and B takes over, we’d have files A.list and B.list.
To change this, attribute remove_old_coords_on_view_change can be set to true. In this case, files created by old
coordinators will be removed. In the scenario above, where A crashed, B would remove A.list.
However, if we have a split between {A,B} and {C,D}, C would remove A.list. To prevent this, every coordinator
writes its file again on a view change that has left members or in which the coordinator changed.
There is still a case which can end up with a zombie file that’s never removed: when we have a single member A and
it is killed via kill -9. In this case, file A.list will never get cleaned up and subsequent joiners will ask
A to join, up to GMS.max_join_attempts times.
Zombie cleanup can be solved by setting remove_all_files_on_view_change to true. In this case, a coordinator
removes all files on a view change that has members leaving or changes the coordinator.
|
|
Setting remove_old_coords_on_view_change or remove_all_files_on_view_change to true generates more traffic
to the file system or cloud store. If members are always shut down gracefully, or never killed via kill -9, then
it is recommended to set both attributes to false.
|
| Name | Description |
|---|---|
info_writer_max_writes_after_view |
The max number of times my own information should be written to the storage after a view change |
info_writer_sleep_time |
Interval (in ms) at which the info writer should kick in |
location |
The absolute path of the shared file |
register_shutdown_hook |
If set, a shutdown hook is registered with the JVM to remove the local address from the store. Default is true |
remove_all_data_on_view_change |
If true, on a view change, the new coordinator removes all data except its own |
remove_old_coords_on_view_change |
If true, on a view change, the new coordinator removes files from old coordinators |
update_store_on_view_change |
Change the backend store when the view changes. If off, then the file is only changed on joins, but not on leaves. Enabling this will increase traffic to the backend store. |
write_data_on_find |
When a non-initial discovery is run, and InfoWriter is not running, write the data to disk (if true). JIRA: https://issues.jboss.org/browse/JGRP-2288 |
6.4.7. JDBC_PING
JDBC_PING uses a DB to store information about cluster nodes used for discovery. All cluster nodes are supposed to be able to access the same DB.
When a node starts, it queries information about existing members from the database, determines the coordinator and then asks the coord to join the cluster. It also inserts information about itself into the table, so others can subsequently find it.
When a node P has crashed, the current coordinator removes P’s information from the DB. However, if there is a network split, then this can be problematic, as crashed members cannot be told from partitioned-away members.
For instance, if we have {A,B,C,D}, and the split creates 2 subclusters {A,B} and {C,D},
then A would remove {C,D} because it thinks they crashed, and - likewise - C would remove {A,B}.
To solve this, every member re-inserts its information into the DB after a view change. So when C and D's view
changes from {A,B,C,D} to {C,D}, both sides of the split re-insert their information.
Ditto for the other side of the network split.
The re-insertion is governed by attributes info_writer_max_writes_after_view and info_writer_sleep_time: the former
defines the number of times re-insertion should be done (in a timer task) after each view change and the latter is the
sleep time (in ms) between re-insertions.
The value of this is that dead members are removed from the DB (because they cannot do re-insertion), but network splits are handled, too.
Another attribute clear_table_on_view_change governs how zombies are handled. Zombies are table entries for members
which crashed, but weren’t removed for some reason. E.g. if we have a single member A and kill it (via kill -9), then
it won’t get removed from the table.
If clear_table_on_view_change is set to true, then the coordinator clears the table after a view change (instead of
only removing the crashed members), and everybody re-inserts its own information. This attribute can be set to true if
automatic removal of zombies is desired. However, it is costly, therefore if no zombies ever occur (e.g. because processes
are never killed with kill -9), or zombies are removed by a system admin, then it should be set to false.
|
|
Processes killed with kill -3 are removed from the DB as a shutdown handler will be called on kill -3 (but not on kill -9). |
| Name | Description |
|---|---|
clear_sql |
SQL to clear the table |
connection_driver |
The JDBC connection driver name |
connection_password |
The JDBC connection password |
connection_url |
The JDBC connection URL |
connection_username |
The JDBC connection username |
contains_sql |
Finds a given entry by its address and cluster name, used to implement a contains() |
datasource_jndi_name |
To use a DataSource registered in JNDI, specify the JNDI name here. This is an alternative to all connection_* configuration options: if this property is not empty, then all connection relatedproperties must be empty. |
delete_single_sql |
SQL used to delete a row. Customizable, but keep the order of parameters and pick compatible types: 1)Own Address, as String 2)Cluster name, as String |
initialize_sql |
If not empty, this SQL statement will be performed at startup.Customize it to create the needed table on those databases which permit table creation attempt without losing data, such as PostgreSQL and MySQL (using IF NOT EXISTS). To allow for creation attempts, errors performing this statement will be loggedbut not considered fatal. To avoid any DDL operation, set this to an empty string. |
insert_single_sql |
SQL used to insert a new row. Customizable, but keep the order of parameters and pick compatible types: 1)Own Address, as String 2)Cluster name, as String 3)Serialized PingData as byte[] |
select_all_pingdata_sql |
SQL used to fetch all node’s PingData. Customizable, but keep the order of parameters and pick compatible types: only one parameter needed, String compatible, representing the Cluster name. Must return a byte[], the Serialized PingData as it was stored by the insert_single_sql statement. Must select primary keys subsequently for cleanup to work properly |
6.4.8. BPING
BPING uses UDP broadcasts to discover other nodes. The default broadcast address (dest) is 255.255.255.255, and should be replaced with a subnet specific broadcast, e.g. 192.168.1.255.
| Name | Description |
|---|---|
bind_port |
Port for discovery packets |
dest |
Target address for broadcasts. This should be restricted to the local subnet, e.g. 192.168.1.255 |
port_range |
Sends discovery packets to ports 8555 to (8555+port_range) |
6.4.9. RACKSPACE_PING
RACKSPACE_PING uses Rackspace Cloud Files Storage to discover initial members. Each node writes a small object in a shared Rackspace container. New joiners read all addresses from the container and ping each of the elements of the resulting set of members. When a member leaves, it deletes its corresponding object.
This objects are stored under a container called jgroups, and each node will write an object name after the cluster name, plus a "/" followed by the address, thus simulating a hierarchical structure.
| Name | Description |
|---|---|
apiKey |
Rackspace API access key |
container |
Name of the root container |
region |
Rackspace region, either UK or US |
username |
Rackspace username |
6.4.10. S3_PING
S3_PING uses Amazon S3 to discover initial members. New joiners read all addresses from this bucket and ping each of the elements of the resulting set of members. When a member leaves, it deletes its corresponding file.
It’s designed specifically for members running on Amazon EC2, where multicast traffic is not allowed and thus MPING or PING will not work. When Amazon RDS is preferred over S3, or if a shared database is used, an alternative is to use JDBC_PING.
Each instance uploads a small file to an S3 bucket and each instance reads the files out of this bucket to determine the other members.
There are three different ways to use S3_PING, each having its own tradeoffs between security and ease-of-use. These are described in more detail below:
-
Private buckets, Amazon AWS credentials given to each instance
-
Public readable and writable buckets, no credentials given to each instance
-
Public readable but private writable buckets, pre-signed URLs given to each instance Pre-signed URLs are the most secure method since writing to buckets still requires authorization and you don’t have to pass Amazon AWS credentials to every instance. However, they are also the most complex to setup.
Here’s a configuration example for private buckets with credentials given to each instance:
<S3_PING location="my_bucket" access_key="access_key"
secret_access_key="secret_access_key" timeout="2000"
num_initial_members="3"/>Here’s an example for public buckets with no credentials:
<S3_PING location="my_bucket"/>And finally, here’s an example for public readable buckets with pre-signed URLs:
<S3_PING pre_signed_put_url="http://s3.amazonaws.com/my_bucket/DemoCluster/node1?AWSAccessKeyId=access_key&Expires=1316276200&Signature=it1cUUtgCT9ZJyCJDj2xTAcRTFg%3D"
pre_signed_delete_url="http://s3.amazonaws.com/my_bucket/DemoCluster/node1?AWSAccessKeyId=access_key&Expires=1316276200&Signature=u4IFPRq%2FL6%2FAohykIW4QrKjR23g%3D"
/>| Name | Description |
|---|---|
access_key |
The access key to AWS (S3) |
host |
The name of the AWS server |
port |
The port at which AWS is listening |
pre_signed_delete_url |
When non-null, we use this pre-signed URL for DELETEs |
pre_signed_put_url |
When non-null, we use this pre-signed URL for PUTs |
prefix |
When non-null, we set location to prefix-UUID |
secret_access_key |
The secret access key to AWS (S3) |
skip_bucket_existence_check |
Skip the code which checks if a bucket exists in initialization |
use_ssl |
Whether or not to use SSL to connect to host:port |
6.4.11. AWS_PING
This is a protocol written by Meltmedia, which uses the AWS API. It is not part of JGroups, but can be downloaded at https://github.com/meltmedia/jgroups-aws.
6.4.12. Native S3 PING
This implementation by Zalando uses the AWS SDK. It is not part of JGroups, but can be found at https://github.com/zalando/jgroups-native-s3-ping. This protocols works with JGroups versions 3.x.
There’s a refactored version of AWS_PING that was ported (in 2017) to run on JGroups 4.x at https://github.com/jgroups-extras/native-s3-ping.
6.4.13. GOOGLE_PING
GOOGLE_PING is a subclass of S3_PING and inherits most of the functionality. It uses Google Cloud Storage to store information about individual members.
The snippet below shows a sample config:
<GOOGLE_PING
location="jgroups-bucket"
access_key="GXXXXXX"
secret_access_key="YYYYYY"
timeout="2000" num_initial_members="3"/>This will use a bucket "jgroups-bucket" or create one if it doesn’t exist, then create another folder under it with the cluster name, and finally use 1 object per member in that location for member info.
|
|
GOOGLE_PING has been deprecated and GOOGLE_PING2 should be used instead.
|
6.4.14. GOOGLE_PING2
GOOGLE_PING2 is the successor to GOOGLE_PING and uses Google’s
client library to access Google Compute Storage. It is the recommended way to access GCS and the project is hosted at
https://github.com/jgroups-extras/jgroups-google.
6.4.15. DNS_PING
DNS_PING uses DNS A or SRV entries to perform discovery. Initially this protocol was designed for
Kubernetes and OpenShift but it suitable for any type of DNS discovery.
|
|
In order to enable DNS discovery for application deployed on Kubernetes/OpenShift one must create a Governing Headless Service with proper selectors covering desired pods. The service will ensure that DNS entries are populated as soon as pods are in Ready state. |
The snippet below shows a sample config:
<dns.DNS_PING
dns_address="192.168.0.17"
dns_query="jgroups-dns-ping.myproject.svc.cluster.local" />This will turn on DNS discovery using the DNS server at address 192.168.0.17 and DNS query
jgroups-dns-ping.myproject.svc.cluster.local using DNS A records.
The dns_address parameter is optional and when it’s missing, the protocol will use the default DNS resolver configured
on the machine.
The dns_query parameter is mandatory. It is used for querying the DNS Server and obtaining information about the
cluster members. The svc.cluster.local part is specific to Kubernetes and OpenShift and might be omitted.
It is also possible to use SRV entries for discovery as shown below:
<dns.DNS_PING
dns_query="_ping._tcp.jgroups-dns-ping.myproject.svc.cluster.local"
dns_record_type="SRV" />Kubernetes SRV entries are created using the following scheme: _my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.local.
When the above example is used in Kubernetes or OpenShift, [DNS_PING] will form a cluster of all the pods governed
by a service named jgroups-dns-ping in namespace myproject, which exposes a TCP port named ping.
Here’s an example of a YAML file which shows how to run a service and a pod using DNS_PING:
apiVersion: v1
items:
- apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
labels:
run: jgrp
name: jgrp
spec:
replicas: 3
template:
metadata:
labels:
run: jgrp
deploymentConfig: jgrp
spec:
containers:
- image: belaban/jgroups
command: ["chat.sh"]
args: ["-props dns-ping.xml -o"]
env:
- name: DNS_QUERY
value: "_ping._tcp.jgrp.default.svc.cluster.local."
- name: DNS_RECORD_TYPE
value: SRV
# - name: DNS_ADDRESS
# value: 10.96.0.10
# - name: DNS_PROBE_TRANSPORT_PORTS
# value: "true"
name: jgrp
kind: List
metadata: {}
---
apiVersion: v1
kind: Service
metadata:
annotations:
service.alpha.kubernetes.io/tolerate-unready-endpoints: "true"
name: jgrp
labels:
run: jgrp
spec:
publishNotReadyAddresses: true
clusterIP: None
ports:
- name: ping
port: 7800
protocol: TCP
targetPort: 7800
selector:
deploymentConfig: jgrp
---Configuration dns_ping.xml sets up DNS_PING as follows:
<TCP bind_port="7800" .../>
<dns.DNS_PING
dns_query=""
async_discovery_use_separate_thread_per_request="true"
probe_transport_ports=""
num_discovery_runs="1"
dns_address=""
dns_record_type=""/>
...The DNS_QUERY system property (overriding the dns_query attribute) is defined in the Yaml as
_ping._tcp.jgrp.default.svc.cluster.local., which corresponds to the port (7800) advertized in the ports section:
_ping is the port name, _tcp the protocol, jgrp the project and default the namespace.
As can also be seen in the Yaml file, DNS_RECORD_TYPE is set to SRV, overriding the default type of A.
|
|
If the ports section does not list the correct port (corresponding to the transport’s port, TCP.bind_port),
DNS_PING will not be able to find any cluster members. However, in this case, we can make DNS_PING probe members
at the transport’s port (plus port_range) by setting probe_transport_ports to true.
|
For more information, please refer to Kubernetes DNS Admin Guide.
|
|
Note that both [KUBE_PING] and [DNS_PING] can be used in Kubernetes/OpenShift. The main difference between them is that [KUBE_PING] uses Kubernetes API for discovery whereas [DNS_PING] uses DNS entries. Having said that, [DNS_PING] should be used together with a Governing Service, which makes it perfect fit for Stateful Sets. |
A working example of using this protocol might be found in https://github.com/slaskawi/jgroups-dns-ping-example.
| Name | Description |
|---|---|
dns_address |
DNS Address. This property will be assembled with the dns:// prefix. If this is specified, A records will be resolved through DnsContext. |
dns_context_factory |
DNS Context Factory. Used when DNS_PING is configured to use SRV record types and when using A types with a specific dns_address. |
dns_query |
A comma-separated list of DNS queries for fetching members |
dns_record_type |
DNS Record type |
probe_transport_ports |
For SRV records returned by the DNS query, the non-0 ports returned by DNS areused. If this attribute is true, then the transport ports will also be used. Ignored for A records. |
6.4.16. SWIFT_PING
SWIFT_PING uses Openstack Swift to discover initial members. Each node writes a small object in a shared container. New joiners read all addresses from the container and ping each of the elements of the resulting set of members. When a member leaves, it deletes its corresponding object.
These objects are stored under a container called jgroups (by default), and each node will write an object name after the cluster name, plus a "/" followed by the address, thus simulating a hierarchical structure.
Currently only Openstack Keystone authentication is supported. Here is a sample configuration block:
<SWIFT_PING timeout="2000"
num_initial_members="3"
auth_type="keystone_v_2_0"
auth_url="http://localhost:5000/v2.0/tokens"
username="demo"
password="password"
tenant="demo" />| Name | Description |
|---|---|
auth_type |
Authentication type |
auth_url |
Authentication url |
container |
Name of the root container |
password |
Password |
tenant |
Openstack Keystone tenant name |
username |
Username |
6.4.17. KUBE_PING
This Kubernetes-based discovery protocol can be used with OpenShift [2] and uses Kubernetes to discover cluster
members. KUBE_PING is hosted on jgroups-extras; refer to [1] for details.
6.4.18. AZURE_PING
This is a discovery protocol that allows cluster nodes to run on the Azure cloud [1]. For details refer to [2].
6.4.19. PDC - Persistent Discovery Cache
The Persistent Discovery Cache can be used to cache the results of the discovery process persistently. E.g. if we have TCPPING.initial_hosts configured to include only members A and B, but have a lot more members, then other members can bootstrap themselves and find the right coordinator even when neither A nor B are running.
An example of a TCP-based stack configuration is:
<TCP />
<PDC cache_dir="/tmp/jgroups" />
<TCPPING timeout="2000" num_initial_members="20"
initial_hosts="192.168.1.5[7000]" port_range="0"
return_entire_cache="true"
use_disk_cache="true" />| Name | Description |
|---|---|
cache_dir |
The absolute path of the directory for the disk cache. The mappings will be stored as individual files in this directory |
6.4.20. MULTI_PING
This discovery protocol allows for multiple discovery protocols to be used in a configuration. MULTI_PING adds
all discovery protocols underneath it in the stack to a list at initialization time.
When a discovery request is
received from above, all discovery protocols in the list are contacted, either sequentially
(async_discovery=false) or in parallel (async_discovery=true).
A sample configuration is shown below:
<TCP ... />
<TCPPING initial_hosts="127.0.0.1[7800]" port_range="0"/>
<PING />
<MPING/>
<FILE_PING/>
<MULTI_PING async_discovery="true"/>
<MERGE3/>
...6.5. Merging after a network partition
If a cluster gets split for some reasons (e.g. network partition), this protocol merges the subclusters
back into one cluster. It is only run by the coordinator (the oldest member in a cluster), which
periodically multicasts its presence and view information. If another coordinator (for the same cluster)
receives this message, it will initiate a merge process. Note that this merges subgroups
{A,B} and {C,D,E} back into {A,B,C,D,E},
but it does not merge state. The application has to handle the callback to merge
state. See Handling network partitions for suggestion on merging states.
Following a merge, the coordinator of the merged group can shift from the typical case of
"the coordinator is the member who has been up the longest." During the merge process, the coordinators
of the various subgroups need to reach a common decision as to who the new coordinator is.
In order to ensure a consistent result, each coordinator combines the addresses of all the members
in a list and then sorts the list. The first member in the sorted list becomes the coordinator.
The sort order is determined by how the address implements the interface. Then JGroups compares based
on the UUID. So, take a hypothetical case where two machines were running, with one machine running
three separate cluster members and the other two members. If communication between the machines were cut,
the following subgroups would form:
{A,B} and {C,D,E}
Following the merge, the new view would be: {C,D,A,B,E}, with C being the new coordinator.
Note that "A", "B" and so on are just logical names, attached to UUIDs, but the actual sorting is done
on the actual UUIDs.
6.5.1. MERGE3
If a cluster gets split for some reasons (e.g. network partition), this protocol merges the subclusters back into one cluster.
All members periodically send an INFO message with their address (UUID), logical name, physical address and ViewId. The ViewId (ViewId) is used to see if we have diverging views among the cluster members: periodically, every coordinator looks at the INFO messages received so far and checks if there are any inconsistencies.
If inconsistencies are found, the merge leader will be the member with the lowest address (UUID).
The merge leader then asks the senders of the inconsistent ViewIds for their full views. Once received,
it simply passes a MERGE event up the stack, where the merge will be handled (by GMS) in exactly the same
way as if MERGE2 has generated the MERGE event.
The advantages of MERGE3 are:
-
Sending of INFO messages is spread out over time, preventing message peaks which might cause packet loss. This is especially important in large clusters.
-
Only 1 merge should be running at any time. There are no competing merges going on.
-
An INFO message carries the logical name and physical address of a member. This allows members to update their logical/physical address caches.
-
On the downside,
MERGE3has constant (small) traffic by all members. -
MERGE3was written for an IP multicast capable transport (UDP), but it also works with other transports (such asTCP), although it isn’t as efficient onTCPas onUDP.
Example
<MERGE3 max_interval="10000" min_interval="5000" check_interval="15000"/>This means that every member sends out an INFO message at a random interval in range [5000 .. 10000] ms. Every
15 seconds (check_interval), every coordinator checks if it received a ViewId differing from its own, and initiates
a merge if true.
-
We have subclusters
{A,B,C},{D,E}and{F}. The subcluster coordinators areA,DandF -
The network partition now heals
-
Dchecks its received ViewIds, and sees entries from itself andA-
Since broadcasting of INFO messages is unreliable (as
MERGE3is underneathNAKACK2in the stack), the last INFO message fromFmight have been dropped
-
-
DorAinitiates a merge, which results in view{A,B,C,D,E} -
A bit later, on the next check,
Fsees that its ViewId diverges from the ViewId sent in an INFO message byC -
FandAinitiate a new merge which results in merge view{A,B,C,D,E,F}
Increasing check_interval decreases the chance of partial merges (as shown above), but doesn’t entirely eliminate them:
members are not started at exactly the same time, and therefore their check intervals overlap.
If a member’s interval elapsed just after receiving INFO messages from a subset of the subclusters
(e.g. briefly after a partition healed), then we will still have a partial merge.
| Name | Description |
|---|---|
check_interval |
Interval (in ms) after which we check for view inconsistencies |
max_interval |
Interval (in milliseconds) when the next info message will be sent. A random value is picked from range [1..max_interval] |
max_participants_in_merge |
The max number of merge participants to be involved in a merge. 0 sets this to unlimited. |
min_interval |
Minimum time in ms before sending an info message |
only_coords_run_consistency_checker |
If true, only coordinators periodically check view consistency, otherwise everybody runs this task (https://issues.jboss.org/browse/JGRP-2092). Might get removed without notice. |
6.6. Failure Detection
The task of failure detection is to probe members of a group and see whether they are alive. When a member is suspected of having failed, then a SUSPECT message is sent to all nodes of the cluster. It is not the task of the failure detection layer to exclude a crashed member (this is done by the group membership protocol, GMS), but simply to notify everyone that a node in the cluster is suspected of having crashed.
The SUSPECT message is handled by the GMS protocol of the current coordinator only; all other members ignore it.
6.6.1. FD
Failure detection based on a logical ring and heartbeat messages.
Members form a logical ring; e.g. in view {A,B,C,D}, A pings B, which pings C, which pings D, which pings A.
Pinging means sending a heartbeat.
Each member sends this heartbeat every timeout ms to the neighbor to its right. When a member receives a heartbeat, it
sends back an ack. When the ack is received the timestamp of when a member last heard from its neighbor is reset.
When a member doesn’t receive any heartbeat acks from its neighbor for timeout * max_tries ms,
that member is declared suspected, and will be excluded by GMS.
This is done by FD multicasting a SUSPECT(P) message which is handled by the current coordinator by double-checking
the health of P (using VERIFY_SUSPECT) and - if P still doesn’t reply - by excluding P from the membership.
Note that setting msg_counts_as_heartbeat in P to true causes the timestamp of P in the pinging member to be
reset.
Example
<FD timeout="3000" max_tries="4" />-
The membership is
{A,B,C,D,E}. -
Now C and D crash at the same time
-
B’s next heartbeats won’t get an ack
-
After roughly 12 seconds (4 * 3 secs), B suspects C
-
B now starts sending heartbeats to D
-
-
A (the coordinator) handles the
SUSPECT(C)message from B and usesVERIFY_SUSPECTto double-check that C is really dead -
After
VERIFY_SUSPECT.timeoutms, A creates a new view{A,B,D,E}excluding C -
After ca. 12 seconds, B sends a
SUSPECT(D)message to the coordinator, which eventually also excludesD
| Name | Description |
|---|---|
max_tries |
Number of times to send an are-you-alive message |
msg_counts_as_heartbeat |
Treat messages received from members as heartbeats. Note that this means we’re updating a value in a hashmap every time a message is passing up the stack through FD, which is costly. |
timeout |
Timeout to suspect a node P if neither a heartbeat nor data were received from P. |
6.6.2. FD_ALL
Failure detection based on simple heartbeat protocol. Every member periodically multicasts a heartbeat. Every member also maintains a table of all members (minus itself). When data or a heartbeat from P are received, we reset the timestamp for P to the current time. Periodically, we check for expired members whose timestamp is greater than the timeout, and suspect those.
Example
<FD_ALL timeout="12000" interval="3000" timeout_check_interval="2000"/>-
The membership is
{A,B,C,D,E}. -
Every member broadcasts a heartbeat every 3 seconds. When received, the sender’s timestamp in the table is set to the current time
-
Every member also checks every 2 seconds if any member’s timestamp exceeds the timeout and suspects that member if this is the case
-
Now C and D crash at the same time
-
After roughly 12-13 seconds,
Abroadcasts aSUSPECT(C,D)message -
The coordinator (
A) usesVERIFY_SUSPECTto double check ifCandDare dead -
Acreates a new view{A,B,E}which excludesCandD
|
|
Contrary to FD which suspects adjacent crashed members C and D one by one, FD_ALL suspects C and D in
constant time. FD takes N * (timeout * max_tries) ms, whereas FD_ALL takes timeout ms
|
| Name | Description |
|---|---|
timeout_check_interval |
Interval at which the HEARTBEAT timeouts are checked |
use_time_service |
Uses TimeService to get the current time rather than calling System.nanoTime(). |
6.6.3. FD_ALL2
Similar to FD_ALL, but doesn’t use any timestamps. Instead, a boolean flag is associated with each
member. When a message or heartbeat (sent every interval ms) from P is received, P’s flag is set to true.
The heartbeat checker checks every timeout ms for members whose flag is false, suspects those, and
- when done - resets all flags to false again.
The times it takes to suspect a member are the same as for FD_ALL
6.6.4. FD_ALL3
Failure detection protocol which maintains a bitmap of timeout / interval bits (e.g. timeout=60000,
interval=10000 → 6 bits), initialized to 1, for each member. The timeout check task also maintains
an index which is incremented every time it is invoked and the bit at the index is set to 0.
When a heartbeat or a message is received, the bit at the current index is set to 1.
When the timeout check task detects that all bits are 0, the member will be suspected.
6.6.5. FD_SOCK
Failure detection protocol based on a ring of TCP sockets created between cluster members, similar to FD but
not using heartbeat messages.
Each member in a cluster connects to its neighbor (the last member connects to the first), thus forming a ring.
Member B is suspected when its neighbor A detects abnormal closing of its TCP socket
(presumably due to a crash of B). However, if B is about to leave gracefully, it lets its neighbor A
know, so that A doesn’t suspect B.
===== Example
* The membership is {A,B,C,D,E}.
* Members C and D are killed at the same time
* B notices that C abnormally closed its TCP socket and broadcasts a SUSPECT(C) message
* The current coordinator (A) asks VERIFY_SUSPECT to double check that C is dead
* Meanwhile, B tries to create a TCP socket to the next-in-line (D) but fails. It therefore broadcasts a
SUSPECT(D) message
* A also handles this message and asks VERIFY_SUSPECT to double check if D is dead
* After VERIFY_SUSPECT can’t verify that C and D are still alive, A creates a new view
{A,B,E} and installs it
* The time taken for FD_SOCK to suspect a member is very small (a few ms)
|
|
It is recommended to use FD_SOCK and FD or FD_ALL together in the same stack: FD_SOCK detects killed
nodes immediately, and FD_ALL (with a higher timeout) detects hung members or kernel panics / crashed switches
(which don’t close the TCP connection) after the timeout.
|
| Name | Description |
|---|---|
bind_addr |
The NIC on which the ServerSocket should listen on. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
cache_max_age |
Max age (in ms) an element marked as removed has to have until it is removed |
cache_max_elements |
Max number of elements in the cache until deleted elements are removed |
client_bind_port |
Start port for client socket. Default value of 0 picks a random port |
external_addr |
Use "external_addr" if you have hosts on different networks, behind firewalls. On each firewall, set up a port forwarding rule (sometimes called "virtual server") to the local IP (e.g. 192.168.1.100) of the host then on each host, set "external_addr" TCP transport parameter to the external (public IP) address of the firewall. |
external_port |
Used to map the internal port (bind_port) to an external port. Only used if > 0 |
get_cache_timeout |
Timeout for getting socket cache from coordinator |
keep_alive |
Whether to use KEEP_ALIVE on the ping socket or not. Default is true |
num_tries |
Number of attempts coordinator is solicited for socket cache until we give up |
port_range |
Number of ports to probe for start_port and client_bind_port |
sock_conn_timeout |
Max time in millis to wait for ping Socket.connect() to return |
start_port |
Start port for server socket. Default value of 0 picks a random port |
suspect_msg_interval |
Interval for broadcasting suspect messages |
6.6.6. FD_HOST
To detect the crash or freeze of entire hosts and all of the cluster members running on them, FD_HOST
can be used. It is not meant to be used in isolation, as it doesn’t detect crashed members on the
local host, but in conjunction with other failure detection protocols, such as FD_ALL or FD_SOCK.
FD_HOST can be used when we have multiple cluster members running on a physical box. For example,
if we have members {A,B,C,D} running on host 1 and {M,N,O,P} running on host 2, and host 1 is
powered down, then A, B, C and D are suspected and removed from the cluster together, typically
in one view change.
By default, FD_HOST uses InetAddress.isReachable() to perform liveness checking of other hosts, but
if property cmd is set, then any script or command can be used. FD_HOST will launch the command and
pass the IP address ot the host to be checked as argument. Example: cmd="ping -c 3".
A typical failure detection configuration would look like this:
...
<FD_SOCK/>
<FD_ALL timeout="60000" interval="20000"/>
<FD_HOST interval="10000" timeout="35000" />
...If we have members {A,B,C} on host 192.168.1.3, {M,N,O} on 192.168.1.4 and {X,Y,Z} on 192.168.1.5, then
the behavior is as follows:
| Scenario | Behavior |
|---|---|
Any member (say |
|
Member |
|
Host |
Since this is a graceful shutdown, the OS closes all sockets. |
The power supply to host |
|
Member |
Since this is a graceful leave, none of the failure detection protocols kick in |
| Name | Description |
|---|---|
check_timeout |
Max time (in ms) that a liveness check for a single host can take |
cmd |
The command used to check a given host for liveness. Example: "ping". If null, InetAddress.isReachable() will be used by default |
interval |
The interval (in ms) at which the hosts are checked for liveness |
timeout |
Max time (in ms) after which a host is suspected if it failed all liveness checks |
use_time_service |
Uses TimeService to get the current time rather than System.currentTimeMillis. Might get removed soon, don’t use ! |
6.6.7. VERIFY_SUSPECT
Verifies that a suspected member is really dead by pinging that member one last time before excluding it, and dropping the suspect message if the member does respond.
VERIFY_SUSPECT tries to minimize false suspicions.
The protocol works as follows: it catches SUSPECT events traveling up the stack. Then it verifies that the suspected member is really dead. If yes, it passes the SUSPECT event up the stack, otherwise it discards it. VERIFY_SUSPECT Has to be placed somewhere above the failure detection protocol and below the GMS protocol (receiver of the SUSPECT event). Note that SUSPECT events may be reordered by this protocol.
| Name | Description |
|---|---|
bind_addr |
Interface for ICMP pings. Used if use_icmp is true The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
num_msgs |
Number of verify heartbeats sent to a suspected member |
timeout |
Number of millisecs to wait for a response from a suspected member |
use_icmp |
Use InetAddress.isReachable() to verify suspected member instead of regular messages |
use_mcast_rsps |
Send the I_AM_NOT_DEAD message back as a multicast rather than as multiple unicasts (default is false) |
6.7. Reliable message transmission
6.7.1. NAKACK2
NAKACK2 provides reliable delivery and FIFO (= First In First Out) properties for messages sent to all nodes in a cluster.
It performs lossless and FIFO delivery of multicast messages, using negative acks. E.g. when receiving P:1, P:3, P:4, a receiver delivers only P:1, and asks P for retransmission of message 2, queuing P3-4. When P2 is finally received, the receiver will deliver P2-4 to the application.
Reliable delivery means that no message sent by a sender will ever be lost, as all messages are numbered with sequence numbers (by sender) and retransmission requests are sent to the sender of a message if that sequence number is not received.
|
|
Note that NAKACK2 can also be configured to send retransmission requests for M to anyone in the cluster, rather than only to the sender of M. |
FIFO order means that all messages from a given sender are received in exactly the order in which they were sent.
| Name | Description |
|---|---|
become_server_queue_size |
Size of the queue to hold messages received after creating the channel, but before being connected (is_server=false). After becoming the server, the messages in the queue are fed into up() and the queue is cleared. The motivation is to avoid retransmissions (see https://issues.jboss.org/browse/JGRP-1509 for details). 0 disables the queue. |
discard_delivered_msgs |
Should messages delivered to application be discarded |
log_discard_msgs |
discards warnings about promiscuous traffic |
log_not_found_msgs |
If false, trashes warnings about retransmission messages not found in the xmit_table (used for testing) |
max_batch_size |
The max size of a message batch when delivering messages. 0 is unbounded |
max_rebroadcast_timeout |
Timeout to rebroadcast messages. Default is 2000 msec |
max_xmit_req_size |
Max number of messages to ask for in a retransmit request. 0 disables this and uses the max bundle size in the transport |
resend_last_seqno |
If enabled, multicasts the highest sent seqno every xmit_interval ms. This is skipped if a regular message has been multicast, and the task aquiesces if the highest sent seqno hasn’t changed for resend_last_seqno_max_times times. Used to speed up retransmission of dropped last messages (JGRP-1904) |
resend_last_seqno_max_times |
Max number of times the last seqno is resent before acquiescing if last seqno isn’t incremented |
suppress_time_non_member_warnings |
Time during which identical warnings about messages from a non member will be suppressed. 0 disables this (every warning will be logged). Setting the log level to ERROR also disables this. |
use_mcast_xmit |
Retransmit retransmit responses (messages) using multicast rather than unicast |
use_mcast_xmit_req |
Use a multicast to request retransmission of missing messages |
xmit_from_random_member |
Ask a random member for retransmission of a missing message. Default is false |
xmit_interval |
Interval (in milliseconds) at which missing messages (from all retransmit buffers) are retransmitted |
xmit_table_max_compaction_time |
Number of milliseconds after which the matrix in the retransmission table is compacted (only for experts) |
xmit_table_msgs_per_row |
Number of elements of a row of the matrix in the retransmission table; gets rounded to the next power of 2 (only for experts). The capacity of the matrix is xmit_table_num_rows * xmit_table_msgs_per_row |
xmit_table_num_rows |
Number of rows of the matrix in the retransmission table (only for experts) |
xmit_table_resize_factor |
Resize factor of the matrix in the retransmission table (only for experts) |
6.7.2. UNICAST3
UNICAST3 provides reliable delivery and FIFO (= First In First Out) properties for point-to-point messages between a sender and a receiver.
Reliable delivery means that no message sent by a sender will ever be lost, as all messages are numbered with sequence numbers (by sender) and retransmission requests are sent to the sender of a message if that sequence number is not received. UNICAST3 uses a mixture of positive and negative acks (similar to NAKACK2). This reduces the communication overhead required for sending an ack for every message.
FIFO order means that all messages from a given sender are received in exactly the order in which they were sent.
On top of a reliable transport, such as TCP, UNICAST3 is not really needed. However, concurrent delivery of messages from the same sender is prevented by UNICAST3 by acquiring a lock on the sender’s retransmission table, so unless concurrent delivery is desired, UNICAST3 should not be removed from the stack even if TCP is used.
Details of UNICAST3’s design can be found here: UNICAST3
| Name | Description |
|---|---|
ack_threshold |
Send an ack immediately when a batch of ack_threshold (or more) messages is received. Otherwise send delayed acks. If 1, ack single messages (similar to UNICAST) |
conn_close_timeout |
Time (in ms) until a connection marked to be closed will get removed. 0 disables this |
conn_expiry_timeout |
Time (in milliseconds) after which an idle incoming or outgoing connection is closed. The connection will get re-established when used again. 0 disables connection reaping. Note that this creates lingering connection entries, which increases memory over time. |
level |
Sets the level |
log_not_found_msgs |
If true, trashes warnings about retransmission messages not found in the xmit_table (used for testing) |
max_batch_size |
The max size of a message batch when delivering messages. 0 is unbounded |
max_retransmit_time |
Max number of milliseconds we try to retransmit a message to any given member. After that, the connection is removed. Any new connection to that member will start with seqno #1 again. 0 disables this |
max_xmit_req_size |
Max number of messages to ask for in a retransmit request. 0 disables this and uses the max bundle size in the transport |
sync_min_interval |
Min time (in ms) to elapse for successive SEND_FIRST_SEQNO messages to be sent to the same sender |
xmit_interval |
Interval (in milliseconds) at which messages in the send windows are resent |
xmit_table_max_compaction_time |
Number of milliseconds after which the matrix in the retransmission table is compacted (only for experts) |
xmit_table_msgs_per_row |
Number of elements of a row of the matrix in the retransmission table; gets rounded to the next power of 2 (only for experts). The capacity of the matrix is xmit_table_num_rows * xmit_table_msgs_per_row |
xmit_table_num_rows |
Number of rows of the matrix in the retransmission table (only for experts) |
xmit_table_resize_factor |
Resize factor of the matrix in the retransmission table (only for experts) |
6.7.3. RSVP
The RSVP protocol is not a reliable delivery protocol per se, but augments reliable protocols such as NAKACK, UNICAST or UNICAST2. It should be placed somewhere above these in the stack.
| Name | Description |
|---|---|
ack_on_delivery |
When true, we pass the message up to the application and only then send an ack. When false, we send an ack first and only then pass the message up to the application. |
resend_interval |
Interval (in milliseconds) at which we resend the RSVP request. Needs to be < timeout. 0 disables it. |
throw_exception_on_timeout |
Whether an exception should be thrown when the timeout kicks in, and we haven’t yet received all acks. An exception would be thrown all the way up to JChannel.send(). If we use RSVP_NB, this will be ignored. |
timeout |
Max time in milliseconds to block for an RSVP’ed message (0 blocks forever). |
6.8. Message stability
To serve potential retransmission requests, a member has to store received messages until it is known that every member in the cluster has received them. Message stability for a given message M means that M has been seen by everyone in the cluster.
The stability protocol periodically (or when a certain number of bytes have been received) initiates a consensus protocol, which multicasts a stable message containing the highest message numbers for a given member. This is called a digest.
When everyone has received everybody else’s stable messages, a digest is computed which consists of the minimum sequence numbers of all received digests so far. This is the stability vector, and contain only message sequence numbers that have been seen by everyone.
This stability vector is the broadcast to the group and everyone can remove messages from their retransmission tables whose sequence numbers are smaller than the ones received in the stability vector. These messages can then be garbage collected.
6.8.1. STABLE
STABLE garbage collects messages that have been seen by all members of a cluster. Each member has to store all messages because it may be asked to retransmit. Only when we are sure that all members have seen a message can it be removed from the retransmission buffers. STABLE periodically gossips its highest and lowest messages seen. The lowest value is used to compute the min (all lowest seqnos for all members), and messages with a seqno below that min can safely be discarded.
Note that STABLE can also be configured to run when N bytes have been received. This is recommended when sending messages at a high rate, because sending stable messages based on time might accumulate messages faster than STABLE can garbage collect them.
| Name | Description |
|---|---|
desired_avg_gossip |
Average time to send a STABLE message |
max_bytes |
Maximum number of bytes received in all messages before sending a STABLE message is triggered |
send_stable_msgs_to_coord_only |
Wether or not to send the STABLE messages to all members of the cluster, or to the current coordinator only. The latter reduces the number of STABLE messages, but also generates more work on the coordinator |
stability_delay |
Delay before stability message is sent |
6.9. Group Membership
Group membership takes care of joining new members, handling leave requests by existing members, and handling SUSPECT messages for crashed members, as emitted by failure detection protocols. The algorithm for joining a new member is essentially:
- loop
- find initial members (discovery)
- if no responses:
- become singleton group and break out of the loop
- else:
- determine the coordinator (oldest member) from the responses
- send JOIN request to coordinator
- wait for JOIN response
- if JOIN response received:
- install view and break out of the loop
- else
- sleep for 5 seconds and continue the loop
6.9.1. pbcast.GMS
| Name | Description |
|---|---|
all_clients_retry_timeout |
Time (in ms) to wait for another discovery round when all discovery responses were clients. A timeout of 0 means don’t wait at all. |
install_view_locally_first |
Whether or not to install a new view locally first before broadcasting it (only done at the coord ). Set to true automatically if a state transfer protocol is detected |
join_timeout |
Join timeout |
leave_timeout |
Max time (in ms) to wait for a LEAVE response after a LEAVE req has been sent to the coord |
log_collect_msgs |
Logs failures for collecting all view acks if true |
log_view_warnings |
Logs warnings for reception of views less than the current, and for views which don’t include self |
max_bundling_time |
Max view bundling timeout if view bundling is turned on |
max_join_attempts |
Number of join attempts before we give up and become a singleton. 0 means never give up. |
max_leave_attempts |
Number of times a LEAVE request is sent to the coordinator (without receiving a LEAVE response, before giving up and leaving anyway (failure detection will eventually exclude the left member). A value of 0 means wait forever |
membership_change_policy |
The fully qualified name of a class implementing MembershipChangePolicy. |
merge_timeout |
Timeout (in ms) to complete merge |
num_prev_mbrs |
Max number of old members to keep in history. Default is 50 |
num_prev_views |
Number of views to store in history |
print_local_addr |
Print local address of this member after connect. Default is true |
print_physical_addrs |
Print physical address(es) on startup |
print_view_details |
When true, left and joined members are printed in addition to the view |
use_delta_views |
If true, then GMS is allowed to send VIEW messages with delta views, otherwise it always sends full views. See https://issues.jboss.org/browse/JGRP-1354 for details. |
use_flush_if_present |
Use flush for view changes. Default is true |
view_ack_collection_timeout |
Time in ms to wait for all VIEW acks (0 == wait forever. Default is 2000 msec |
view_bundling |
View bundling toggle |
Joining a new member
Consider the following situation: a new member wants to join a group. The prodedure to do so is:
-
Multicast an (unreliable) discovery request (ping)
-
Wait for n responses or m milliseconds (whichever is first)
-
Every member responds with the address of the coordinator
-
If the initial responses are > 0: determine the coordinator and start the JOIN protocol
-
If the initial response are 0: become coordinator, assuming that no one else is out there
However, the problem is that the initial mcast discovery request might get lost, e.g. when multiple members start at the same time, the outgoing network buffer might overflow, and the mcast packet might get dropped. Nobody receives it and thus the sender will not receive any responses, resulting in an initial membership of 0. This could result in multiple coordinators, and multiple subgroups forming. How can we overcome this problem ? There are two solutions:
-
Increase the timeout, or number of responses received. This will only help if the reason of the empty membership was a slow host. If the mcast packet was dropped, this solution won’t help
-
Add the MERGE2 or MERGE3 protocol. This doesn’t actually prevent multiple initial cordinators, but rectifies the problem by merging different subgroups back into one. Note that this might involve state merging which needs to be done by the application.
6.10. Flow control
Flow control takes care of adjusting the rate of a message sender to the rate of the slowest receiver over time. If a sender continuously sends messages at a rate that is faster than the receiver(s), the receivers will either queue up messages, or the messages will get discarded by the receiver(s), triggering costly retransmissions. In addition, there is spurious traffic on the cluster, causing even more retransmissions.
Flow control throttles the sender so the receivers are not overrun with messages.
This is implemented through a credit based system, where each sender has max_credits credits and decrements
them whenever a message is sent. The sender blocks when the credits fall below 0, and only resumes
sending messages when it receives a replenishment message from the receivers.
The receivers maintain a table of credits for all senders and decrement the given sender’s credits as well, when a message is received.
When a sender’s credits drops below a threshold, the receiver will send a replenishment message to
the sender. The threshold is defined by min_bytes or min_threshold.
Note that flow control can be bypassed by setting message flag Message.NO_FC. See Tagging messages with flags for details.
The properties for FlowControl are shown below and can be used in MFC and UFC:
| Name | Description |
|---|---|
max_block_time |
Max time (in ms) to block |
max_block_times |
Max times to block for the listed messages sizes (Message.getLength()). Example: "1000:10,5000:30,10000:500" |
max_credits |
Max number of bytes to send per receiver until an ack must be received to proceed |
min_credits |
Computed as max_credits x min_theshold unless explicitly set |
min_threshold |
The threshold (as a percentage of max_credits) at which a receiver sends more credits to a sender. Example: if max_credits is 1'000'000, and min_threshold 0.25, then we send ca. 250'000 credits to P once we’ve got only 250'000 credits left for P (we’ve received 750'000 bytes from P) |
6.10.1. MFC and UFC
|
|
Flow control is implemented with MFC (Multicast Flow Control) and Unicast Flow Control (UFC). The reason
for 2 separate protocols (which have a common superclass FlowControl) is that multicast flow control should not be
impeded by unicast flow control, and vice versa. Also, performance for the separate implementations could be increased,
plus they can be individually omitted.
|
For example, if no unicast flow control is needed, UFC can be left out of the stack configuration.
MFC
MFC has currently no properties other than those inherited by FlowControl (see above).
UFC
UFC has currently no properties other than those inherited by FlowControl (see above).
6.11. Non blocking flow control
Contrary to blocking flow control, which blocks senders from sending a message when credits are lacking, non-blocking flow control avoids blocking the sender thread.
Instead, when a sender has insufficient credits to send a message, the message is queued and the control flow returns to the calling thread. When more credits are received, the queued messages are sent.
This means that a JChannel.send(Message) never blocks and - if the transport is also non-blocking (e.g. TCP_NIO2) -
we have a completely non-blocking stack.
However, if the send rate is always faster than the receive (processing) rate, messages will end up in the queues and the queues will grow, leading to memory exhaustion.
It is therefore possible to fall back to blocking the sender threads if the message queues grow beyond a certain limit.
The attribute to bound a queue is max_queue_size, and defines the max number of bytes the accumulated messages can
have. If that size is exceeded, the addition of a message to a queue will block until messages are removed from the queue.
The max_queue_size attribute is per queue, so for unicast messages we have 1 queue per destination and for multicast
messages we have a single queue for all destinations. For example, if max_queue_size is set to 5M (5 million bytes),
and we have members {A,B,C,D}, then on A the queues for B, C and D will have a combined max size of 15MB.
6.11.1. UFC_NB
This is the non-blocking alternative to UFC. It extends UFC, so all attributes from UFC are inherited.
| Name | Description |
|---|---|
max_queue_size |
Max number of bytes of all queued messages for a given destination. If a given destination has no credits left and the message cannot be added to the queue because it is full, then the sender thread will be blocked until there is again space available in the queue, or the protocol is stopped. |
6.11.2. MFC_NB
This is the non-blocking alternative to MFC. It inherits from MFC, so all attributes are inherited.
| Name | Description |
|---|---|
max_queue_size |
Max number of bytes of all queued messages for a given destination. If a given destination has no credits left and the message cannot be added to the queue because it is full, then the sender thread will be blocked until there is again space available in the queue, or the protocol is stopped. |
6.12. Fragmentation
6.12.1. FRAG and FRAG2
FRAG and FRAG2 fragment large messages into smaller ones, send the smaller ones, and at the receiver side, the smaller fragments will get assembled into larger messages again, and delivered to the application. FRAG and FRAG2 work for both unicast and multicast messages.
The difference between FRAG and FRAG2 is that FRAG2 does 1 less copy than FRAG, so it is the recommended fragmentation protocol. FRAG serializes a message to know the exact size required (including headers), whereas FRAG2 only fragments the payload (excluding the headers), so it is faster.
The properties of FRAG2 are:
| Name | Description |
|---|---|
frag_size |
The max number of bytes in a message. Larger messages will be fragmented |
Contrary to FRAG, FRAG2 does not need to serialize a message in order to break it into smaller fragments: it looks only at the message’s buffer, which is a byte array anyway. We assume that the size addition for headers and src and dest addresses is minimal when the transport finally has to serialize the message, so we add a constant (by default 200 bytes). Because of the efficiency gained by not having to serialize the message just to determine its size, FRAG2 is generally recommended over FRAG. .FRAG3
| Name | Description |
|---|---|
frag_size |
The max number of bytes in a message. Larger messages will be fragmented |
FRAG2 needs only half the memory than FRAG2 to handle fragments and the final full message. See https://issues.jboss.org/browse/JGRP-2154 for details.
6.13. Ordering
6.13.1. SEQUENCER
SEQUENCER provider total order for multicast (=group) messages by forwarding messages to the current coordinator, which then sends the messages to the cluster on behalf of the original sender. Because it is always the same sender (whose messages are delivered in FIFO order), a global (or total) order is established.
Sending members add every forwarded message M to a buffer and remove M when they receive it. Should the current coordinator crash, all buffered messages are forwarded to the new coordinator.
| Name | Description |
|---|---|
delivery_table_max_size |
Size of the set to store received seqnos (for duplicate checking) |
flush_forward_table |
If true, all messages in the forward-table are sent to the new coord, else thye’re dropped (https://issues.jboss.org/browse/JGRP-2268) |
threshold |
Number of acks needed before going from ack-mode to normal mode. 0 disables this, which means that ack-mode is always on |
6.13.2. Total Order Anycast (TOA)
A total order anycast is a totally ordered message sent to a subset of the cluster members. TOA intercepts messages with an AnycastMessage (carrying a list of addresses) and handles sending of the message in total order. Say the cluster is {A,B,C,D,E} and the Anycast is to {B,C}.
Skeen’s algorithm is used to send the message: B and C each maintain a logical clock (a counter). When a message is to be sent, TOA contacts B and C and asks them for their counters. B and C return their counters (incrementing them for the next request).
The originator of the message then sets the message’s ID to be the max of all returned counters and sends the message. Receivers then deliver the messages in order of their IDs.
The main use of TOA is currently in Infinispan’s transactional caches with partial replication: it is used to apply transactional modifications in total order, so that no two-phase commit protocol has to be run and no locks have to be acquired.
As shown in "Exploiting Total Order Multicast in Weakly Consistent Transactional Caches", when we have many conflicts by different transactions modifying the same keys, TOM fares better than 2PC.
Note that TOA is experimental (as of 3.1).
6.14. State Transfer
6.14.1. pbcast.STATE_TRANSFER
STATE_TRANSFER is the existing transfer protocol, which transfers byte[] buffers around. However, at the state provider’s side, JGroups creates an output stream over the byte[] buffer, and passes the ouput stream to the getState(OutputStream) callback, and at the state requester’s side, an input stream is created and passed to the setState(InputStream) callback.
This allows us to continue using STATE_TRANSFER, until the new state transfer protocols are going to replace it (perhaps in 4.0).
In order to transfer application state to a joining member of a cluster, STATE_TRANSFER has to load entire state into memory and send it to a joining member. The major limitation of this approach is that for state transfers that are very large this would likely result in memory exhaustion.
For large state transfer use either the STATE or STATE_SOCK protocol. However, if the state is small, STATE_TRANSFER is okay.
6.14.2. StreamingStateTransfer
StreamingStateTransfer is the superclass of STATE and STATE_SOCK (see below). Its properties are:
| Name | Description |
|---|---|
buffer_size |
Size (in bytes) of the state transfer buffer |
max_pool |
Maximum number of pool threads serving state requests |
pool_thread_keep_alive |
Keep alive for pool threads serving state requests |
6.14.3. pbcast.STATE
Overview
STATE was renamed from (2.x) STREAMING_STATE_TRANSFER, and refactored to extend a common superclass StreamingStateTransfer. The other state transfer protocol extending StreamingStateTransfer is STATE_SOCK (see STATE_SOCK).
STATE uses a streaming approach to state transfer; the state provider writes its state to the output stream passed to it in the getState(OutputStream) callback, which chunks the stream up into chunks that are sent to the state requester in separate messages.
The state requester receives those chunks and feeds them into the input stream from which the state is read by the setState(InputStream) callback.
The advantage compared to STATE_TRANSFER is that state provider and requester only need small (transfer) buffers to keep a part of the state in memory, whereas STATE_TRANSFER needs to copy the entire state into memory.
If we for example have a list of 1 million elements, then STATE_TRANSFER would have to create a byte[] buffer out of it, and return the byte[] buffer, whereas a streaming approach could iterate through the list and write each list element to the output stream. Whenever the buffer capacity is reached, we’d then send a message and the buffer would be reused to receive more data.
Configuration
STATE has currently no properties other than those inherited by StreamingStateTransfer (see above).
6.14.4. STATE_SOCK
STATE_SOCK is also a streaming state transfer protocol, but compared to STATE, it doesn’t send the chunks as messages, but uses a TCP socket connection between state provider and requester to transfer the state.
The state provider creates a server socket at a configurable bind address and port, and the address and port are sent back to a state requester in the state response. The state requester then establishes a socket connection to the server socket and passes the socket’s input stream to the setState(InputStream) callback.
Configuration
The configuration options of STATE_SOCK are listed below:
| Name | Description |
|---|---|
bind_addr |
The interface (NIC) used to accept state requests. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
bind_interface_str |
The interface (NIC) which should be used by this transport |
bind_port |
The port listening for state requests. Default value of 0 binds to any (ephemeral) port |
external_addr |
Use "external_addr" if you have hosts on different networks, behind firewalls. On each firewall, set up a port forwarding rule (sometimes called "virtual server") to the local IP (e.g. 192.168.1.100) of the host then on each host, set "external_addr" TCP transport parameter to the external (public IP) address of the firewall. |
external_port |
Used to map the internal port (bind_port) to an external port. Only used if > 0 |
6.14.5. BARRIER
BARRIER is used by some of the state transfer protocols, as it lets existing threads complete and blocks new threads to get both the digest and state in one go.
In 3.1, a new mechanism for state transfer will be implemented, eliminating the need for BARRIER. Until then, BARRIER should be used when one of the state transfer protocols is used. BARRIER is part of every default stack which contains a state transfer protocol.
| Name | Description |
|---|---|
flush_timeout |
Max time (in ms) to wait until the threads which passed the barrier before it was closed have completed. If this time elapses, an exception will be thrown and state transfer will fail. 0 = wait forever |
max_close_time |
Max time barrier can be closed. Default is 60000 ms |
6.15. pbcast.FLUSH
Flushing forces group members to send all their pending messages prior to a certain event. The process of flushing acquiesces the cluster so that state transfer or a join can be done. It is also called the stop-the-world model as nobody will be able to send messages while a flush is in process. Flush is used in:
- State transfer
-
When a member requests state transfer, it tells everyone to stop sending messages and waits for everyone’s ack. Then it have received everyone’s asks, the application asks the coordinator for its state and ships it back to the requester. After the requester has received and set the state successfully, the requester tells everyone to resume sending messages.
- View changes (e.g.a join)
-
Before installing a new view V2, flushing ensures that all messages sent in the current view V1 are indeed delivered in V1, rather than in V2 (in all non-faulty members). This is essentially Virtual Synchrony.
FLUSH is designed as another protocol positioned just below the channel, on top of the stack (e.g. above STATE_TRANSFER). The STATE_TRANSFER and GMS protocols request a flush by sending an event up the stack, where it is handled by the FLUSH protcol. Another event is sent back by the FLUSH protocol to let the caller know that the flush has completed. When done (e.g. view was installed or state transferred), the protocol sends a message, which will allow everyone in the cluster to resume sending.
A channel is notified that the FLUSH phase has been started by the Receiver.block() callback.
Read more about flushing in Flushing: making sure every node in the cluster received a message.
| Name | Description |
|---|---|
bypass |
When set, FLUSH is bypassed, same effect as if FLUSH wasn’t in the config at all |
enable_reconciliation |
Reconciliation phase toggle. Default is true |
end_flush_timeout |
Timeout to wait for UNBLOCK after STOP_FLUSH is issued. Default is 2000 msec |
retry_timeout |
Retry timeout after an unsuccessful attempt to quiet the cluster (first flush phase). Default is 3000 msec |
start_flush_timeout |
Timeout (per atttempt) to quiet the cluster during the first flush phase. Default is 2000 msec |
timeout |
Max time to keep channel blocked in flush. Default is 8000 msec |
6.16. Security
Security is used to prevent (1) non-authorized nodes being able to join a cluster and (2) non-members being able to communicate with cluster members.
(1) is handled by AUTH or SASL which allows only authenticated nodes to join a cluster.
(2) is handled by the encryption protocol (SYM_ENCRYPT or ASYM_ENCRYPT) which encrypts messages between cluster members such that a non-member cannot understand them.
6.16.1. Encryption
Encryption is based on a shared secret key that all members of a cluster have. The key is either acquired from a shared keystore (symmetric encryption) or a new joiner fetches it from the coordinator via public/private key exchange (asymmetric encryption).
A sender encrypts a message with the shared secret key and the receivers decrypt it with the same secret key.
By default, only the payload of a message is encrypted, but not the other metadata (e.g. headers, destination address, flags etc).
If (for example) headers are not encrypted, it is possible to use replay attacks, because the sequence number (seqno) of a message is seen. For example, if a seqno is 50, then an attacker might copy the message, and increment the seqno.
To prevent this, the SERIALIZE protocol can be placed on top of SYM_ENCRYPT or ASYM_ENCRYPT. It serializes the entire message into the payload of a new message that’s then encrypted and sent down the stack.
SYM_ENCRYPT
This is done by SYM_ENCRYPT. The configuration includes mainly attributes that define the keystore, e.g. keystore_name
(name of the keystore, needs to be found on the classpath), store_password, key_password and alias.
SYM_ENCRYPT uses store type JCEKS (for details between JKS and JCEKS see here), however keytool uses JKS, therefore
a keystore generated with keytool will not be accessible.
To generate a keystore compatible with JCEKS, use the following command line options to keytool:
keytool -genseckey -alias myKey -keypass changeit -storepass changeit -keyalg Blowfish -keysize 56 -keystore defaultStore.keystore -storetype JCEKS
SYM_ENCRYPT could then be configured as follows:
<SYM_ENCRYPT sym_algorithm="AES/CBC/PKCS5Padding"
sym_iv_length="16"
key_store_name="defaultStore.keystore"
store_password="changeit"
alias="myKey"/>Note that defaultStore.keystore will have to be found in the classpath.
|
|
Both SYM_ENCRYPT and ASYM_ENCRYPT should be placed directly under NAKACK2 (see sample configurations, e.g. sym-encrypt.xml or asym-encrypt.xml). |
| Name | Description |
|---|---|
alias |
Alias used for recovering the key. Change the default |
key_password |
Password for recovering the key. Change the default |
keystore_name |
File on classpath that contains keystore repository |
keystore_type |
The type of the keystore. Types are listed in http://docs.oracle.com/javase/8/docs/technotes/tools/unix/keytool.html |
store_password |
Password used to check the integrity/unlock the keystore. Change the default |
ASYM_ENCRYPT
Contrary to SYM_ENCRYPT, the secret key is not fetched from a shared keystore, but from the current coordinator C. After new member P joins the cluster, it sends a request to get the secret key (including P’s public key).
C then sends the secret key back to P, encrypted with P’s public key, and P decrypts it with its private key and installs it. From then on, P encrypts and decrypts messages using the secret key.
When a member leaves, C can optionally (based on change_key_on_leave) create a new secret key, and every cluster member
needs to fetch it again, using the public/private key exchange described above.
A stack configured to use asymmetric encryption could look like this:
...
<VERIFY_SUSPECT/>
<ASYM_ENCRYPT
sym_keylength="128"
sym_algorithm="AES/CBC/PKCS5Padding"
sym_iv_length="16"
asym_keylength="512"
asym_algorithm="RSA"/>
<pbcast.NAKACK2/>
<UNICAST3/>
<pbcast.STABLE/>
<FRAG2/>
<AUTH auth_class="org.jgroups.auth.MD5Token"
auth_value="chris"
token_hash="MD5"/>
<pbcast.GMS join_timeout="2000" />The configuration snippet shows ASYM_ENCRYPT positioned just below NAKACK2, so that headers of the important retransmission protocols NAKACK2 and UNICAST3 are encrypted, too. Note that AUTH should be part of the configuration, or else unauthenticated nodes would be able to acquire the secret key from the coordinator.
For details on the design of ASYM_ENCRYPT see https://github.com/belaban/JGroups/blob/master/doc/design/ASYM_ENCRYPT.txt.
| Name | Description |
|---|---|
change_key_on_coord_leave |
Change the secret group key when the coordinator changes. If enabled, this will take place even if change_key_on_leave is disabled. |
change_key_on_leave |
When a node leaves, change the secret group key, preventing old members from eavesdropping |
use_external_key_exchange |
If true, a separate KeyExchange protocol (somewhere in the stack) is used to fetch the shared secret key. If false, the default (built-in) key exchange protocol will be used. |
SERIALIZE
This protocol serializes every sent message including all of its metadata into a new message and sends it down. When a message is received, it will be deserialized and then sent up the stack. This can be used by the encryption protocols (see Encryption).
SSL_KEY_EXCHANGE
ASYM_ENCRYPT uses a built-in key exchange protocol for a requester to fetch the secret group key from the key server (usually the coordinator). Such secret key requests are accompanied by the requester’s public key. The key server encrypts the secret key response with the public key of the requester, and the requester decrypts the response with its private key and can then install the new secret group key to encrypt and decrypt messages.
This works well, however, it is not immune against man-in-the-middle attacks. If MitM attack prevention is required,
a separate key exchange protocol can be added to the stack. ASYM_ENCRYPT needs to be told to use the key exchange
protocol, which has to be located somewhere beneath it in the stack, by setting use_external_key_exchange to true.
A key exchange protocol needs to extend KeyExchange.
SSL_KEY_EXCHANGE implements MitM-safe key exchange by using SSL sockets and client (and, of course, server)
certification. The key server opens an SSL server socket on a given port and requesters create an SSL client socket and
connect to it, then exchange the secret group key and finally close the connection.
As key requesters and the key server require properly configured certificate chains, trust is established between the two parties and secret group keys can be transmitted securely.
|
|
As certificates authenticate the identity of key servers and requesters (usually joining members), AUTH is not
needed as a separate protocol and can be removed from the configuration.
|
Here’s a typical configuration:
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:org:jgroups"
xsi:schemaLocation="urn:org:jgroups http://www.jgroups.org/schema/jgroups-4.2.xsd">
<UDP />
<PING/>
<MERGE3/>
<FD_ALL timeout="8000" interval="3000"/>
<FD_SOCK/>
<VERIFY_SUSPECT/>
<SSL_KEY_EXCHANGE
keystore_name="/home/bela/certs/my-keystore.jks"
keystore_password="password"
/>
<ASYM_ENCRYPT
use_external_key_exchange="true"
sym_keylength="128"
sym_algorithm="AES/CBC/PKCS5Padding"
sym_iv_length="16"
asym_keylength="512"
asym_algorithm="RSA"/>
<pbcast.NAKACK2/>
<UNICAST3/>
<pbcast.STABLE/>
<FRAG2/>
<pbcast.GMS join_timeout="2000" />
</config>Here SSL_KEY_EXCHANGE is positioned below ASYM_ENCRYPT. The latter is configured to use an external key exchange
protocol (1). The former is configured with a keystore and password (2).
| Name | Description |
|---|---|
bind_addr |
Bind address for the server or client socket. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
keystore_name |
Location of the keystore |
keystore_password |
Password to access the keystore |
keystore_type |
The type of the keystore. Types are listed in http://docs.oracle.com/javase/8/docs/technotes/tools/unix/keytool.html |
port |
The port at which the key server is listening. If the port is not available, the next port will be probed, up to port+port_range. Used by the key server (server) to create an SSLServerSocket and by clients to connect to the key server. |
port_range |
The port range to probe |
require_client_authentication |
If enabled, clients are authenticated as well (not just the server). Set to true to prevent rogue clients to fetch the secret group key (e.g. via man-in-the-middle attacks) |
secret_key_algorithm |
The type of secret key to be sent up the stack (converted from DH). Should be the same as the algorithm part of ASYM_ENCRYPT.sym_algorithm if ASYM_ENCRYPT is used |
session_verifier_arg |
The argument to the session verifier |
session_verifier_class |
The fully qualified name of a class implementing SessionVerifier |
socket_timeout |
Timeout (in ms) for a socket read. This applies for example to the initial SSL handshake, e.g. if the client connects to a non-JGroups service accidentally running on the same port |
ssl_protocol |
The SSL protocol to use. Defaults to TLSv1.2. |
ssl_provider |
The SSL security provider. Defaults to null, which will use the default JDK provider. |
SSL_KEY_EXCHANGE and left members
Note that when we have members {A,B,C} and change_key_on_leave is true in ASYM_ENCRYPT, then A will install a new
shared group key in {A,B} when C leaves (or crashes).
This works fine as long as we don’t use an external key exchange mechanism (such as SSL_KEY_EXCHANGE): C will not be able to decrypt A’s or B’s messages, as it doesn’t have the new secret group key.
However, as (for example) SSL_KEY_EXCHANGE works by connecting to the key server (the coordinator) and validating the
identity of the key requester via a certificate chain, the left member will still be able to decrypt the traffic in
the new cluster {A,B} by simply fetching and installing the new secret group key.
There’s no way around this as we assume that any member with a valid certificate (chain) can fetch the secret group key. As a matter of fact, even a rogue member having the correct certficates would be able to acquire the secret group key!
6.16.2. AUTH
Authentication is performed by AUTH. Its main use is to make sure only authenticated members can join (or merge into) a cluster. Scenarios where AUTH kicks in are:
-
Joining a cluster: only authenticated joiners are allowed to join
-
Merging: make sure only authenticated members can merge into a new cluster
-
View installation (if enabled): views and merge views can only be installed by authenticated members
So authentication makes sure that rogue nodes will never be able to be members of a cluster, be it via joining or merging.
AUTH provides pluggable security that defines if a node should be allowed to join a cluster. It can be used standalone, or in conjunction with encryption protocols such as SYM_ENCRYPT or ASYM_ENCRYPT.
AUTH sits below the GMS protocol and listens for JOIN REQUEST messages. When a JOIN REQUEST is received it tries to find an AuthHeader object, inside of which should be an implementation of the AuthToken object.
AuthToken is an abstract class, implementations of which are responsible for providing the actual authentication mechanism. Some basic implementations of AuthToken are provided in the org.jgroups.auth package (e.g X509Token, FixedMembershipToken etc).
If authentication is successful, the message is simply passed up the stack to the GMS protocol.
If it fails, the AUTH protocol creates a JOIN RESPONSE message with a failure string and passes it back down the stack. This failure string informs the client of the reason for failure. Clients will then fail to join the group and will throw a SecurityException. If this error string is null then authentication is considered to have passed.
For historical (= outdated) information refer to the wiki at AUTH.
| Name | Description |
|---|---|
auth_class |
The fully qualified name of the class implementing the AuthToken interface |
auth_coord |
Do join or merge responses from the coordinator also need to be authenticated |
AuthToken implementations
The AuthToken implementations are listed below. Check the javadoc for details.
| Name | Description |
|---|---|
SimpleToken |
Uses a simple string (password) which is shared, and sent along with the authentication request (deprecated) |
FixedMembershipToken |
A fixed list of IP address:port pairs. If the requester is not in this list, authentication fails |
RegexpMembership |
Uses a regular expression to match against IP address or hostname |
Krb5Token |
Uses Kerberos for authentication |
MD5Token |
Uses an MD5 hash of a simple string (similar to SimpleString above, but hashed instead of plaintext) (deprecated) |
X509Token |
Uses a shared X.509 certificate |
Problems with AUTH
The problem with (deprecated) MD5Token and SimpleToken implementations is that an attacker can find out the
value of the hashed password (MD5Token) or the plain password (SimpleToken). Once they have it, they can bypass AUTH
and join (or merge into) a cluster. See https://issues.jboss.org/browse/JGRP-2367 for details.
The usefulness of AUTH therefore only lies in filtering out JOIN/MERGE requests from members that are not included in
a list of IP addresses (FixedMembershipToken) or IP addresses / hosts / symbolic names (RegexMembership).
A better way of preventing access to members which are not supposed to join is the combo of SSL_KEY_EXCHANGE and ASYM_ENCRYPT.
The latter encrypts messages with a shared group key that’s dynamically generated by the coordinator and disseminated to all members (and optionally changed on a member leaving or joining the group).
The former uses certificates to obtain the shared group key from a coordinator. Members whose certificates cannot be validated can therefore not join or merge.
6.16.3. SASL
SASL is an alternative to the AUTH protocol which provides a layer of authentication to JGroups by allowing the use of one of the SASL mechanisms made available by the JDK. SASL sits below the GMS protocol and listens for JOIN / MERGE REQUEST messages. When a JOIN / MERGE REQUEST is received it tries to find a SaslHeader object which contains the initial response required by the chosen SASL mech. This initiates a sequence of challenge/response messages which, if successful, culminates in allowing the new node to join the cluster. The actual validation logic required by the SASL mech must be provided by the user in the form of a standard javax.security.auth.CallbackHandler implementation.
When authentication is successful, the message is simply passed up the stack to the GMS protocol. When it fails, the SASL protocol creates a JOIN / MERGE RESPONSE message with a failure string and passes it back down the stack. This failure string informs the client of the reason for failure. Clients will then fail to join the group and will throw a SecurityException. If this error string is null then authentication is considered to have passed.
SASL can be (minimally) configured as follows:
<config ... >
<UDP />
<PING />
<pbcast.NAKACK />
<UNICAST3 />
<pbcast.STABLE />
<SASL mech="DIGEST-MD5"
client_callback_handler="org.example.ClientCallbackHandler"
server_callback_handler="org.example.ServerCallbackHandler"/>
<pbcast.GMS />
</config>The mech property specifies the SASL mech you want to use, as defined by RFC-4422. You will also need to provide two
callback handlers, one used when the node is running as coordinator (server_callback_handler) and one used in all other
cases (client_callback_handler). Refer to the JDK’s SASL reference guide for more details: http://docs.oracle.com/javase/7/docs/technotes/guides/security/sasl/sasl-refguide.html
The JGroups package comes with a simple properties-based CallbackHandler which can be used when a more complex Kerberos/LDAP approach is not needed. To use this set both the (server_callback_handler) and
the (client_callback_handler) to org.jgroups.auth.sasl.SimpleAuthorizingCallbackHandler. This CallbackHandler can be configured either programmatically by passing to the constructor an
instance of java.util.Properties containing the appropriate properties, or via standard Java system properties (i.e. set on the command-line using the -DpropertyName=propertyValue notation.
The following properties are available:
-
sasl.credentials.properties - the path to a property file which contains principal/credential mappings represented as principal=password
-
sasl.local.principal - the name of the principal that is used to identify the local node. It must exist in the sasl.credentials.properties file
-
sasl.roles.properties - (optional) the path to a property file which contains principal/roles mappings represented as principal=role1,role2,role3
-
sasl.role - (optional) if present, authorizes joining nodes only if their principal is
-
sasl.realm - (optional) the name of the realm to use for the SASL mechanisms that require it
| Name | Description |
|---|---|
client_callback_handler |
The CallbackHandler to use when a node acts as a client (i.e. it is not the coordinator |
client_callback_handler_class |
n/a |
client_name |
The name to use when a node is acting as a client (i.e. it is not the coordinator. Will also be used to obtain the subject if using a JAAS login module |
client_password |
The password to use when a node is acting as a client (i.e. it is not the coordinator. Will also be used to obtain the subject if using a JAAS login module |
login_module_name |
The name of the JAAS login module to use to obtain a subject for creating the SASL client and server (optional). Only required by some SASL mechs (e.g. GSSAPI) |
mech |
The name of the mech to require for authentication. Can be any mech supported by your local SASL provider. The JDK comes standard with CRAM-MD5, DIGEST-MD5, GSSAPI, NTLM |
sasl_props |
Properties specific to the chosen mech |
server_callback_handler |
The CallbackHandler to use when a node acts as a server (i.e. it is the coordinator |
server_callback_handler_class |
n/a |
server_name |
The fully qualified server name |
timeout |
How long to wait (in ms) for a response to a challenge |
6.17. Misc
6.17.1. Statistics
STATS exposes various statistics, e.g. number of received multicast and unicast messages, number of bytes sent etc. It should be placed directly over the transport
6.17.2. COMPRESS
COMPRESS compresses messages larger than min_size, and uncompresses them at the
receiver’s side. Property compression_level determines how thorough the
compression algorith should be (0: no compression, 9: highest compression).
| Name | Description |
|---|---|
compression_level |
Compression level (from java.util.zip.Deflater) (0=no compression, 1=best speed, 9=best compression). Default is 9 |
min_size |
Minimal payload size of a message (in bytes) for compression to kick in. Default is 500 bytes |
pool_size |
Number of inflaters/deflaters for concurrent processing. Default is 2 |
6.17.3. NAMING
If IpAddressUUIDs are used, then the address/logical_name cache may not be populated for all members. Note that this doesn’t affect correctness, but instead of logical names, the real IP addresses of some members will be printed (e.g. in debug logs).
To prevent this, NAMING can be added to the stack. The typical location is somewhere towards the bottom of the stack,
e.g. above the discovery protocol (e.g. PING).
|
|
NAMING is only needed when TP.use_ip_addrs is true.
|
| Name | Description |
|---|---|
stagger_timeout |
Stagger timeout (in ms). Staggering will be a random timeout in range [0 .. stagger_timeout] |
6.17.4. RELAY
RELAY bridges traffic between seperate clusters, see Bridging between remote clusters for details.
| Name | Description |
|---|---|
bridge_name |
Name of the bridge cluster |
bridge_props |
Properties of the bridge cluster (e.g. tcp.xml) |
present_global_views |
Drops views received from below and instead generates global views and passes them up. A global view consists of the local view and the remote view, ordered by view ID. If true, no protocolwhich requires (local) views can sit on top of RELAY |
relay |
If set to false, don’t perform relaying. Used e.g. for backup clusters; unidirectional replication from one cluster to another, but not back. Can be changed at runtime |
site |
Description of the local cluster, e.g. "nyc". This is added to every address, so itshould be short. This is a mandatory property and must be set |
6.17.5. RELAY2
RELAY2 provides clustering between different sites (local clusters), for multicast and unicast messages. See Relaying between multiple sites (RELAY2) for details.
| Name | Description |
|---|---|
async_relay_creation |
If true, the creation of the relay channel (and the connect()) are done in the background. Async relay creation is recommended, so the view callback won’t be blocked |
can_become_site_master |
Whether or not this node can become the site master. If false, and we become the coordinator, we won’t start the bridge(s) |
can_forward_local_cluster |
If true, a site master forwards messages received from other sites to randomly chosen members of the local site for load balancing, reducing work for itself |
config |
Name of the relay configuration |
enable_address_tagging |
Whether or not we generate our own addresses in which we use can_become_site_master. If this property is false, can_become_site_master is ignored |
max_site_masters |
Maximum number of site masters. Setting this to a value greater than 1 means that we can have multiple site masters. If the value is greater than the number of cluster nodes, everyone in the site will be a site master (and thus join the global cluster |
relay_multicasts |
Whether or not to relay multicast (dest=null) messages |
site |
Name of the site (needs to be defined in the configuration) |
site_master_picker_impl |
Fully qualified name of a class implementing SiteMasterPicker |
site_masters_ratio |
Ratio of members that are site masters, out of range [0..1] (0 disables this). The number of site masters is computes as Math.min(max_site_masters, view.size() * site_masters_ratio). See https://issues.redhat.com/browse/JGRP-2581 for details |
suppress_time_no_route_errors |
Time (in ms) during which identical errors about no route to host will be suppressed. 0 disables this (every error will be logged). |
topo_wait_time |
Number of millis to wait for topology detection |
warn_when_ftc_missing |
If true, logs a warning if the FORWARD_TO_COORD protocol is not found. This property might get deprecated soon |
6.17.6. STOMP
STOMP is discussed in STOMP support. The properties for it are shown below:
| Name | Description |
|---|---|
bind_addr |
The bind address which should be used by the server socket. The following special values are also recognized: GLOBAL, SITE_LOCAL, LINK_LOCAL and NON_LOOPBACK |
endpoint_addr |
If set, then endpoint will be set to this address |
exact_destination_match |
If set to false, then a destination of /a/b match /a/b/c, a/b/d, a/b/c/d etc |
forward_non_client_generated_msgs |
Forward received messages which don’t have a StompHeader to clients |
port |
Port on which the STOMP protocol listens for requests |
send_info |
If true, information such as a list of endpoints, or views, will be sent to all clients (via the INFO command). This allows for example intelligent clients to connect to a different server should a connection be closed. |
6.17.7. DAISYCHAIN
The DAISYCHAIN protocol is discussed in Daisychaining.
| Name | Description |
|---|---|
loopback |
Loop back multicast messages |
6.17.8. RATE_LIMITER
RATE_LIMITER can be used to set a limit on the data sent per time unit. When sending data, only max_bytes can be sent per time_period milliseconds. E.g. if max_bytes="50M" and time_period="1000", then a sender can only send 50MBytes / sec max.
| Name | Description |
|---|---|
max_bytes |
Max number of bytes to be sent in time_period ms. Blocks the sender if exceeded until a new time period has started |
time_period |
Number of milliseconds during which max_bytes bytes can be sent |
6.17.9. Random Early Drop (RED)
RED is an implementation of a Random Early Detect (or Drop) protocol. It measures the queue size of the bundler in the transport and drops a message if the bundler’s queue is starting to get full. When the queue is full, all messages will be dropped (tail drop).
The RED protocol should be placed above the transport.
| Name | Description |
|---|---|
enabled |
If false, all messages are passed down. Will be set to false if the bundler returns a queue size of -1 |
max_threshold |
The max threshold (percentage between min_threshold and 1.0) above which all messages are dropped |
min_threshold |
The min threshold (percentage between 0 and 1.0) below which no message is dropped |
weight_factor |
The weight used to compute the average queue size. The higher the value is, the less the current queue size is taken into account. E.g. with 2, 25% of the current queue size and 75% of the old average is taken to compute the new average. In other words: with a high value, the average will take longer to reflect the current queueu size. |
6.17.10. SOS
SOS is a protocol that periodically dumps a selected set of critical attributes into a file. These could for example
be the size of the thread pool, the number of retransmissions, or the number of rejected messages.
Looking at the values over time would help a support person in diagnosing the problem.
SOS can be placed anywhere in the stack.
| Name | Description |
|---|---|
cmd |
The attributes to be fetched. In probe format (jmx or op command) |
config |
The configuration file containing all protocols and attributes to be dumped |
filename |
File to which the periodic data is written |
interval |
Interval in ms at which the attributes are fetched and written to the file |
6.17.11. Locking protocols
The locking protocol is org.jgroups.protocols.CENTRAL_LOCK:
| Name | Description |
|---|---|
bypass_bundling |
bypasses message bundling if set |
lock_striping_size |
Number of locks to be used for lock striping (for synchronized access to the server_lock entries) |
CENTRAL_LOCK
CENTRAL_LOCK has the current coordinator of a cluster grants locks, so every node has to communicate with the coordinator to acquire or release a lock. Lock requests by different nodes for the same lock are processed in the order in which they are received.
A coordinator maintains a lock table. To prevent losing the knowledge of who holds which locks, the coordinator can push lock information to a number of backups defined by num_backups. If num_backups is 0, no replication of lock information happens. If num_backups is greater than 0, then the coordinator pushes information about acquired and released locks to all backup nodes. Topology changes might create new backup nodes, and lock information is pushed to those on becoming a new backup node.
The advantage of CENTRAL_LOCK is that all lock requests are granted in the same order across the cluster.
| Name | Description |
|---|---|
num_backups |
Number of backups to the coordinator. Server locks get replicated to these nodes as well |
use_thread_id_for_lock_owner |
By default, a lock owner is address:thread-id. If false, we only use the node’s address. See https://issues.jboss.org/browse/JGRP-1886 for details |
CENTRAL_LOCK2
In CENTRAL_LOCK2, the coordinator (= lock issuer) does not backup its lock table to other member(s), but instead a new coordinator fetches information about held locks and pending lock/unlock requests from existing members, before it starts processing lock requests. See Cluster wide locking for details.
| Name | Description |
|---|---|
lock_reconciliation_timeout |
Max time (im ms) to wait for lock info responses from members in a lock reconciliation phase |
use_thread_id_for_lock_owner |
By default, a lock owner is address:thread-id. If false, we only use the node’s address. See https://issues.jboss.org/browse/JGRP-1886 for details |
6.17.12. CENTRAL_EXECUTOR
CENTRAL_EXECUTOR is an implementation of Executing which is needed by the ExecutionService.
| Name | Description |
|---|---|
bypass_bundling |
bypasses message bundling if set |
| Name | Description |
|---|---|
num_backups |
Number of backups to the coordinator. Queue State gets replicated to these nodes as well |
6.17.13. COUNTER
COUNTER is the implementation of cluster wide counters, used by the CounterService.
| Name | Description |
|---|---|
bypass_bundling |
Bypasses message bundling if true |
num_backups |
Number of backup coordinators. Modifications are asynchronously sent to all backup coordinators |
reconciliation_timeout |
Number of milliseconds to wait for reconciliation responses from all current members |
timeout |
Request timeouts (in ms). If the timeout elapses, a Timeout (runtime) exception will be thrown |
6.17.14. SUPERVISOR
SUPERVISOR is a protocol which runs rules which periodically (or event triggered) check conditions and take corrective action if a condition is not met. Example: org.jgroups.protocols.rules.CheckFDMonitor is a rule which periodically checks if FD’s monitor task is running when the cluster size is > 1. If not, the monitor task is started.
The SUPERVISOR is explained in more detail in Supervising a running stack
| Name | Description |
|---|---|
config |
Location of an XML file listing the rules to be installed |
6.17.15. FORK
FORK allows ForkChannels to piggy-back messages on a regular channel. Needs to be placed towards the top of the stack. See ForkChannels: light-weight channels to piggy-back messages over an existing channel for details.
| Name | Description |
|---|---|
config |
Points to an XML file defining the fork-stacks, which will be created at initialization. Ignored if null |
process_state_events |
If enabled, state transfer events will be processed, else they will be passed up |
6.17.16. INJECT_VIEW
INJECT_VIEW exposes a managed operation (injectView) capable of injecting a view by parsing the view state from a string.
The string format is A=A/B/C;B=B/C;C=C (where A,B,C are node names), this would inject view [A,B,C] with A as leader in node A, view [B,C] with B as leader in node B and view [C] in node C.
|
|
Calling injectView("A=A/B/C;B=B/C;C=C"), as an example, just on node B would result only in view [B,C] applied to node B.
|
In order to leverage the injection on multiple nodes at once a tool like Probe can be used,
example: probe.sh op=INJECT_VIEW.injectView["A=A/B/C;B=B/C;C=C"]
|
|
INJECT_VIEW uses logical names to look up real addresses in the logical address cache (located in the
transport). This cache is keyed by address and its values are names. This means that, for example, UUIDs 1 and 6
may map to the same name ("say "A"). If we now look up the address for "A", either 1 or 6 may be returned, depending
on which address mapping was added last to the cache. This means that logical names should be unique, ie.
when running a fork channel.
|